This blog was updated on a semi-daily basis by Joey during the year of work concentrating on the git-annex assistant that was funded by his kickstarter campaign.
Post-kickstarter work will instead appear on the devblog. However, this page's RSS feed will continue to work, so you don't have to migrate your RSS reader.
Yesterday I cut another release. However, getting an OSX build took until 12:12 pm today because of a confusion about the location of lsof on OSX. The OSX build is now available, and I'm looking forward to hearing if it's working!
Today I've been working on making git annex sync commit in direct mode.
For this I needed to find all new, modified, and deleted files, and I also
need the git SHA from the index for all non-new files. There's not really
an ideal git command to use to query this. For now I'm using
git ls-files --others --stage, which works but lists more files than I
really need to look at. It might be worth using one of the Haskell libraries
that can directly read git's index.. but for now I'll stick with ls-files.
It has to check all direct mode files whose content is present, which means
one stat per file (on top of the stat that git already does), as well as one
retrieval of the key per file (using the single git cat-file process that
git-annex talks to).
This is about as efficient as I can make it, except that unmodified
annexed files whose content is not present are listed due to --stage,
and so it has to stat those too, and currently also feeds them into git add.
The assistant will be able to avoid all this work, except once at startup.
Anyway, direct mode committing is working!
For now, git annex sync in direct mode also adds new files. This because
git annex add doesn't work yet in direct mode.
It's possible for a direct mode file to be changed during a commit, which would be a problem since committing involves things like calculating the key and caching the mtime/etc, that would be screwed up. I took care to handle that case; it checks the mtime/etc cache before and after generating a key for the file, and if it detects the file has changed, avoids committing anything. It could retry, but if the file is a VM disk image or something else that's constantly modified, commit retrying forever would not be good.
For git annex sync to be usable in direct mode, it still needs
to handle merging. It looks like I may be able to just enhance the automatic
conflict resolution code to know about typechanged direct mode files.
The other missing piece before this can really be used is that currently
the key to file mapping is only maintained for files added locally, or
that come in via git annex sync. Something needs to set up that mapping
for files present when the repo is initally cloned. Maybe the thing
to do is to have a git annex directmode command that enables/disables
direct mode and can setup the the mapping, as well as any necessary unlocks
and setting the trust level to untrusted.
Spent a while tracking down a bug that causes a crash on OSX when setting up an XMPP account. I managed to find a small test case that reliably crashes, and sent it off to the author of the haskell-gnutls bindings, which had one similar segfault bug fixed before with a similar test case. Fingers crossed..
Just finished tracking down a bug in the Android app that caused its terminal to spin and consume most CPU (and presumably a lot of battery). I introduced this bug when adding the code to open urls written to a fifo, due to misunderstanding how java objects are created, basically. This bug is bad enough to do a semi-immediate release for; luckily it's just about time for a release anyway with other improvements, so in the next few days..
Have not managed to get a recent ghc-android to build so far.
Guilhem fixed some bugs in git annex unused.
Today was a day off, really. However, I have a job running to try to build get a version of ghc-android that works on newer Android releases.
Also, guilhem's git annex unused speedup patch landed. The results are
extrordinary -- speedups on the order of 50 to 100 times faster should
not be uncommon. Best of all (for me), it still runs in constant memory!
After a couple days plowing through it, my backlog is down to 30 messages from 150. And most of what's left is legitimate bugs and todo items.
Spent a while today on an ugly file descriptor leak in the assistant's local pairing listener. This was an upstream bug in the network-multicast library, so while I've written a patch to fix it, the fix isn't quite deployed yet. The file descriptor leak happens when the assistant is running and there is no network interface that supports multicast. I was able to reproduce it by just disconnecting from wifi.
Meanwhile, guilhem has been working on patches that promise to massively
speed up git annex unused! I will be reviewing them tonight.
Made some good progress on the backlog today. Fixed some bugs, applied some patches. Noticing that without me around, things still get followed up on, to a point, for example incomplete test cases for bugs get corrected so they work. This is a very good thing. Community!
I had to stop going through the backlog when I got to one message from
Anarcat mentioning quvi. That turns
out to be just what is needed to implement the often-requested feature
of git-annex addurl supporting YouTube and other similar sites. So I
spent the rest of the day making that work. For example:
% git annex addurl --fast 'http://www.youtube.com/watch?v=1mxPFHBCfuU&list=PL4F80C7D2DC8D9B6C&index=1' addurl Star_Wars_X_Wing__Seth_Green__Clare_Grant__and_Mike_Lamond_Join_Wil_on_TableTop_SE2E09.webm ok
Yes, that got the video title and used it as the filename, and yes,
I can commit this file and run git annex get later, and it will be
able to go download the video! I can even use git annex fsck --fast
to make sure YouTube still has my videos. Awesome.
The great thing about quvi is it takes the url to a video webpage, and returns an url that can be used to download the actual video file. So it simplifies ugly flash videos as far out of existence as is possible. However, since the direct url to the video file may not keep working for long. addurl actually records the page's url, with an added indication that quvi should be used to get it.
Back home. I have some 170 messages of backlog to attend to. Rather than digging into that on my first day back, I spent some time implementing some new features.
git annex import has grown three options that help managing importing of
duplicate files in different ways. I started work on that last week, but
didn't have time to find a way to avoid the --deduplicate option
checksumming each imported file twice. Unfortunately, I have still not
found a way I'm happy with, so it works but is not as efficient as it could
be.
git annex mirror is a new command suggested to me by someone at DebConf
(they don't seem to have filed the requested todo). It arranges for two
repositories to contain the same set of files, as much as possible (when
numcopies allows). So for example, git annex mirror --to otherdrive
will make the otherdrive remote have the same files present and not present
as the local repository.
I am thinking about expanding git annex sync with an option to also sync
data. I know some find it confusing that it only syncs the git metadata
and not the file contents. That still seems to me to be the best and most
flexible behavior, and not one I want to change in any case since
it would be most unexpected if git annex sync downloaded a lot of stuff
you don't want. But I can see making git annex sync --data download
all the file contents it can, as well as uploading all available file
contents to each remote it syncs with. And git annex sync --data --auto
limit that to only the preferred content. Although perhaps
these command lines are too long to be usable?
With the campaign more or less over, I only have a little over a week before it's time to dive into the first big item on the roadmap. Hope to be through the backlog by then.
Wow, 11 days off! I was busy with first dentistry and then DebConf.
Yesterday I visited CERN and
got to talk with some of their IT guys about how they manage their tens of
petabytes of data. Interested to hear they also have the equivilant of a
per-subdirectory annex.numcopies setting. OTOH, they have half a billion
more files than git's index file is likely to be able to scale to support. 
Pushed a release out today despite not having many queued changes. Also, I got git-annex migrated to Debian testing, and so was also able to update the wheezy backport to a just 2 week old version.
Today is also the last day of the campaign!
There has been a ton of discussion about git-annex here at DebConf, including 3 BoF sessions that mostly focused on it, among other git stuff. Also, RichiH will be presenting his "Gitify Your Life" talk on Friday; you can catch it on the live stream.
I've also had a continual stream of in-person bug and feature requests. (Mostly features.) These have been added to the wiki and I look forward to working on that backlog when I get home.
As for coding, I am doing little here, but I do have a branch cooking that
adds some options to git annex import to control handling of duplicate
files.
Made two big improvements to the Windows port, in just a few hours. First, got gpg working, and encrypted special remotes work on Windows. Next, fixed a permissions problem that was breaking removing files from directory special remotes on Windows. (Also cleaned up a lot of compiler warnings on Windows.)
I think I'm almost ready to move the Windows port from alpha to beta status. The only really bad problem that I know of with using it is that due to a lack of locking, it's not safe to run multiple git-annex commands at the same time in Windows.
Got the release out, with rather a lot of fiddling to fix broken builds on various platforms.
Also released a backport to Debian stable. This backport has the assistant, although without WebDAV support. Unfortunately it's an old version from May, since ghc transitions and issues have kept newer versions out of testing so far. Hope that will clear up soon (probably by dropping haskell support for s390x), and I can update it to a newer version. If nothing else it allows using direct mode with Debian stable.
Pleased that the git-cat-files bug was quickly fixed by Peff and has already been pulled into Junio's release tree!
This evening, I've added an interface around the new improved
git check-ignore in git 1.8.4. The assistant can finally honor .gitignore
files!
Today was a nice reminder that there are no end of bugs lurking in filename handling code.
First, fixed a bug that prevented git-annex from adding filenames starting with ":", because that is a special character to git.
Second, discovered that git 1.8.4 rc0 has changed git-cat-file --batch in
a way that makes it impossible to operate on filenames containing spaces.
This is, IMHO, a reversion, so hopefully my
bug report will get it fixed.
Put in a workaround for that, although using the broken version of git with a direct mode repository with lots of spaces in file or directory names is going to really slow down git-annex, since it often has to fork a new git cat-file process for each file.
Release day tomorrow..
Turns out ssh-agent is the cause of the unknown UUID bug! I got a tip
about this from a user, and was quickly able to reproduce the bug that had
eluded me so long. Anyone who has run ssh-add and is using ssh-agent
would see the bug.
It was easy enough to fix as it turns out. Just need to set IdentitiesOnly in .ssh/config where git-annex has set up its own IdentityFile to ensure that its special purpose ssh key is used rather than whatever key the ssh-agent has loaded into it. I do wonder why ssh behaves this way -- why would I set an IdentityFile for a host if I didn't want ssh to use it?
Spent the rest of the day cleaning up after the bug. Since this affects so many people, I automated the clean up process. The webapp will detect repositories with this problem, and the user just has to click to clean up. It'll then correct their .ssh/config and re-enable the repository.
Back to bug squashing. Fixed several, including a long-standing problem on OSX that made the app icon seem to "bounce" or not work. Followed up on a bunch more.
The 4.20130723 git-annex release turns out to have broken support for
running on crippled filesystems (Android, Windows). git annex sync will
add dummy symlinks to the annex as if they were regular files, which is
not good!
Recovery instructions
I've updated the Android and Windows builds and recommend an immediate upgrade.
Will make a formal release on Friday.
Spent some time improving the test suite on Windows, to catch this bug,
and fix a bug that was preventing it from testing git annex sync on
Windows.
I am getting very frustrated with this "unknown UUID" problem that a dozen
people have reported. So far nobody has given me enough information to
reproduce the problem. It seems to have something to do with
git-annex-shell not being found on the remote system that has been either
local paired with or is being used as a ssh server, but I don't yet
understand what. I have spent hours today trying various scenarios to break
git-annex and get this problem to happen.
I certainly can improve the webapp's behavior when a repository's UUID is not known. The easiest fix would be to simply not display such repositories. Or there could be a UI to try to get the UUID. But I'm more interested in fixing the core problem than putting in a UI bandaid.
Technically offtopic, but did a fun side project today: http://joeyh.name/blog/entry/git-annex_as_a_podcatcher/
Worked on 3 interesting bugs today. One I noticed myself while doing tests with adding many thousands of files yesterday. Assistant was delaying making a last commit of the batch of files, and would only wake up and commit them after a further change was made. Turns out this bug was introduced in April while improving commit batching when making very large commits. I seem to remember someone mentioning this problem at some point, but I have not been able to find a bug report to close.
Also tried to reproduce ?this bug. Frustrating, because I'm quite sure I have made changes that will avoid it happening again, but since I still don't know what the root cause was, I can't let it go.
The last bug is ?non-repos in repositories list (+ other weird output) from git annex status and is a most strange thing. Still trying to get a handle on multiple aspects of it.
Also various other bug triage. Down to only 10 messages in my git-annex folder. That included merging about a dozen bugs about local pairing, that all seem to involve git-annex-shell not being found in path. Something is up with that..
The big news: Important behavior change in git annex dropunused. Now it
checks, just like git annex drop, that it's not dropping the last copy of
the file. So to lose data, you have to use --force. This continues the
recent theme of making git-annex hold on more tenaciously to old data, and
AFAIK it was the last place data could be removed without --force.
Also a nice little fix to git annex unused so it doesn't identify
temporary files as unused if they're being used to download a file.
Fixing it was easy thanks to all the transfer logs and locking
infrastucture built for the assistant.
Fixed a bug in the assistant where even though syncing to a network remote was disabled, it would still sync with it every hour, or whenever a network connection was detected.
Working on some direct mode scalability problems when thousands of the identical files are added. Fixing this may involvie replacing the current simple map files with something more scalable like a sqllite database.
While tracking that down, I also found a bug with adding a ton of files in indirect mode, that could make the assistant stall. Turned out to be a laziness problem. (Worst kind of Haskell bug.) Fixed.
Today's sponsor is my sister, Anna Hess, who incidentially just put the manuscript of her latest ebook in the family's annex prior to its publication on Amazon this weekend.
Seems I forgot why I was using debian stable chroots to make the autobuilds: Lots of people still using old glibc version. Had to rebuild the stable chroots that I had upgraded to unstable. Wasted several hours.. I was able to catch up on recent traffic in between.
Was able to reproduce a bug where git annex initremote hung with some
encrypted special remotes. Turns out to be a deadlock when it's not built
with the threaded GHC runtime. So I've forced that runtime to be used.
Got the release out.
I've been working on fleshing out the timeline for the next year. Including a fairly detailed set of things I want to do around disaster recovery in the assistant.
No release today after all. Unexpected bandwidth failure. Maybe in a few days..
Got unannex and uninit working in direct mode. This is one of the more subtle parts of git-annex, and took some doing to get it right. Surprisingly, unannex in direct mode actually turns out to be faster than in indirect mode. In direct mode it doesn't have to immediately commit the unannexing, it can just stage it to be committed later.
Also worked on the ssh connection caching code. The perrennial problem with that code is that the fifo used to communicate with ssh has a small limit on its path, somewhere around 100 characters. This had caused problems when the hostname was rather long. I found a way to avoid needing to be able to reverse back from the fifo name to the hostname, and this let me take the md5sum of long hostnames, and use that shorter string for the fifo.
Also various other bug followups.
Campaign is almost to 1 year!
git-annex has a new nicer versions of its logo, thanks to John Lawrence.
Finally tracked down a week-old bug about the watcher crashing. It turned out to crash when it encountered a directory containing a character that's invalid in the current locale. I've noticed that 'ü' is often the character I get bug reports about. After reproducing the bug I quickly tracked it down to code in the haskell hinotify library, and sent in a patch.
Also uploaded a fixed hinotify to Debian, and deployed it to all 3 of the autobuilder chroots. That took much more time than actually fixing the bug. Quite a lot of yak shaving went on actually. Oh well. The Linux autobuilders are updated to use Debian unstable again, which is nice.
Fixed a bug that prevented annex.diskreserve to be honored when storing files encrypted in a directory special remote.
Taught the webapp the difference between initializing a new special remote and enabling an existing special remote, which fixed some bad behavior when it got confused.
And then for the really fun bug of the day! A user sent me a large file which badly breaks git annex add. Adding the file causes a symlink to be set up, but the file's content is not stored in the annex. Indeed, it's deleted. This is the first data loss bug since January 2012.
Turns out it was caused by the code that handles the dummy files git uses
in place of symlinks on FAT etc filesystems. Code that had no business
running when core.symlinks=true. Code that was prone to false positives
when looking at a tarball of a git-annex repository. So I put in multiple
fixes for this bug. I'll be making a release on Monday.
Today's work was sponsored by Mikhail Barabanov. Thanks, Mikhail!
Succeeded fixing a few bugs today, and followed up on a lot of other ones..
Fixed checking when content is present in a non-bare repository accessed via http.
My changes a few days ago turned out to make uninit leave hard links behind in .git/annex. Luckily the test suite caught this bug, and it was easily fixed by making uninit delete objects with 2 or more hard links at the end.
Theme today seems to be fun with exceptions.
Fixed an uncaught exception that could crash the assistant's Watcher thread if just the right race occurred.
Also fixed it to not throw an exception if another process is
already transferring a file. What this means is that if you run multiple
git annex get processes on the same files, they'll cooperate in each
picking their own files to get and download in parallel. (Also works for
copy, etc.) Especially useful when downloading from an encrypted remote,
since often one process will be decrypting a file while the other is
downloading the next file. There is still room for improvement here;
a -jN option could better handle ensuring N downloads ran concurrently, and
decouple decryption from downloading. But it would need the output layer to
be redone to avoid scrambled output. (All the other stuff to make parallel
git-annex transfers etc work was already in place for a long time.)
Campaign update: Now funded for nearly 10 months, and aiming for a year. https://campaign.joeyh.name/
It looks like I'm funded for at least the next 9 months! It would still be
nice to get to a year. https://campaign.joeyh.name/
Working to get caught up on recent bug reports..
Made git annex uninit not nuke anything that's left over in
.git/annex/objects after unannexing all the files. After all, that could
be important old versions of files or deleted file, and just because the
user wants to stop using git-annex, doesn't mean git-annex shouldn't try to
protect that data with its dying breath. So it prints out some suggestions
in this case, and leaves it up to the user to decide what to do with the
data.
Fixed the Android autobuilder, which had stopped including the webapp.
Looks like another autobuilder will be needed for OSX 10.9.
Surprise! I'm running a new crowdfunding campaign, which I hope will fund several more months of git-annex development.
Please don't feel you have to give, but if you do decide to, give
generously. I'm accepting both Paypal and Bitcoin (via CoinBase.com),
and have some rewards that you might enjoy.
I came up with two lists of things I hope this campaign will fund. These are by no means complete lists. First, some general features and development things:
- Integrate better with Android.
- Get the assistant and webapp ported to Windows.
- Refine the automated stress testing tools to find and fix more problems before users ever see them.
- Automatic recovery. Cosmic ray flipped a bit in a file? USB drive corrupted itself? The assistant should notice these problems, and fix them.
- Encourage more contributions from others. For example, improve the special remote plugin interface so it can do everything the native Haskell interface can do. Eight new cloud storage services were added this year as plugins, but we can do better!
- Use deltas to reduce bandwidth needed to transfer modified versions of files.
Secondly, some things to improve security:
- Add easy support for encrypted git repositories using git-remote-gcrypt, so you can safely push to a repository on a server you don't control.
- Add support for setting up and using GPG keys in the webapp.
- Add protection to the XMPP protocol to guard against man in the middle attacks if the XMPP server is compromised. Ie, Google should not be able to learn about your git-annex repository even if you're using their servers.
- To avoid leaking even the size of your encrypted files to cloud storage providers, add a mode that stores fixed size chunks.
It will also, of course, fund ongoing bugfixing, support, etc.
Been keeping several non-coding balls in the air recently, two of which landed today.
First, Rsync.net is offering a discount to all git-annex users, at one third their normal price. "People using git-annex are clueful and won't be a big support burden for us, so it's a win-win." The web app will be updated offer the discount when setting up a rsync.net repository.
Secondly, I've recorded an interview today for the Git Minutes podcast, about git-annex. Went well, looking forward to it going up, probably on Monday.
Got the release out, after fixing test suite and windows build breakage. This release has all the features on the command line side (--all, --unused, etc), but several bugfixes on the assistant side, and a lot of Windows bug fixes.
I've spent this evening adding icons to git-annex on Linux. Even got the Linux standalone tarball to automatically install icons.
Two gpg fixes today. The OSX Mtn Lion builds were pulling in a build of gpg that wanted a gpg-agent to be installed in /usr/local or it wouldn't work. I had to build my own gpg on OSX to work around this. I am pondering making the OSX dmg builds pull down the gpg source and build their own binary, so issues on the build system can't affect it. But would really rather not, since maintaining your own version of every dependency on every OS is hard (pity about there still being so many OS's without sane package management).
On Android, which I have not needed to touch for a month, gpg was built with --enable-minimal, which turned out to not be necessary and was limiting the encryption algorythms included, and led to interoperability problems for some. Fixed that gpg build too.
Also fixed an ugly bug in the webapp when setting up a rsync repository.
It would configure ~/.ssh/authorized_keys on the server to force
git-annex-shell to be run. Which doesn't work for rsync. I didn't notice
this before because it doesn't affect ssh servers that already have a ssh
setup that allows accessing them w/o a password.
Spent a while working on a bug that can occur in a non-utf8 locale when using special characters in the directory name of a ssh remote. I was able to reproduce it, but have not worked out how to fix it; encoding issues like this are always tricky.
Added something to the walkthrough to help convince people that yes, you can use tags and branches with git-annex just like with regular git. One of those things that is so obvious to the developer writing the docs that it's hard to realize it will be a point of concern.
Seems like there is a release worth of changes already, so I plan to push it out tomorrow.
Actually spread out over several days..
I think I have finally comprehensively dealt with all the wacky system
misconfigurations that can make git commit complain and refuse to commit.
The last of these is a system with a FQDN that doesn't have a dot in it.
I personally think git should just use the hostname as-is in the email
address for commits here -- it's better to be robust. Indeed, I think it
would make more sense if git commit never failed, unless it ran out of
disk or the repo is corrupt. But anyway, git-annex
init will now detect when the commit fails because of this and put a
workaround in place.
Fixed a bug in git annex addurl --pathdepth when the url's path was
shorter than the amount requested to remove from it.
Tracked down a bug that prevents git-annex from working on a system with an old linux kernel. Probably the root cause is that the kernel was built without EVENTFD support. Found a workaround to get a usable git-annex on such a system is to build it without the webapp, since that disables the threaded runtime which triggered the problem.
Dealt with a lot of Windows bugs. Very happy that it's working well enough
that some users are reporting bugs on it in Windows, and with enough detail
that I have not needed to boot Windows to fix them so far.
I've felt for a while that git-annex needed better support for managing the contents of past versions of files that are stored in the annex. I know some people get confused about whether git-annex even supports old versions of files (it does, but you should use indirect mode; direct mode doesn't guarantee old versions of files will be preserved).
So today I've worked on adding command-line power for managing past
versions: a new --all option.
So, if you want to copy every version of every file in your repository to
an archive, you can run git annex copy --all --to archive.
Or if you've got a repository on a drive that's dying, you can run
git annex copy --all --to newdrive, and then on the new drive, run git
annex fsck --all to check all the data.
In a bare repository, --all is default, so you can run git annex get
inside a bare repository and it will try to get every version of every file
that it can from the remotes.
The tricky thing about --all is that since it's operating on objects and
not files, it can't check .gitattributes settings, which are tied to the
file name. I worried for a long time that adding --all would make
annex.numcopies settings in those files not be honored, and that this would
be a Bad Thing. The solution turns out to be simple: I just didn't
implement git annex drop --all! Dropping is the only action that needs to
check numcopies (move can also reduce the number of copies, but explicitly
bypasses numcopies settings).
I also added an --unused option. So if you have a repository that has
been accumulating history, and you'd like to move all file contents not
currently in use to a central server, you can run git annex unused; git
annex move --unused --to origin
Spent too many hours last night tracking down a bug that caused the webapp
to hang when it got built with the new yesod 1.2 release. Much of that time
was spent figuring out that yesod 1.2 was causing the problem. It turned out to
be a stupid typo in my yesod compatability layer. liftH = liftH in
Haskell is an infinite loop, not the stack overflow you get in most
languages.
Even though it's only been a week since the last release, that was worth pushing a release out for, which I've just done. This release is essentially all bug fixes (aside from the automatic ionice and nicing of the daemon).
This website is now available over https. Perhaps more importantly, all the links to download git-annex builds are https by default.
The success stories list is getting really
nice. Only way it could possibly be nicer is if you added your story! Hint.
Came up with a fix for the gnucash hard linked file problem that makes the assistant notice the files gnucash writes. This is not full hard link support; hard linked files still don't cleanly sync around. But new hard links to files are noticed and added, which is enough to support gnucash.
Spent around 4 hours on reproducing and trying to debug ?Hanging on install on Mountain lion. It seems that recent upgrades of the OSX build machine led to this problem. And indeed, building with an older version of Yesod and Warp seems to have worked around the problem. So I updated the OSX build for the last release. I will have to re-install the new Yesod on my laptop and investigate further -- is this an OSX specific problem, or does it affect Linux? Urgh, this is the second hang I've encountered involving Warp..
Got several nice success stories, but I don't
think I've seen yours yet. Please post!
Got caught up on a big queue of messages today. Mostly I hear from people when git-annex is not working for them, or they have a question about using it. From time to time someone does mention that it's working for them.
We have 4 or so machines all synching with each other via the local network thing. I'm always amazed when it doesn't just explode
Due to the nature of git-annex, a lot of people can be using it without anyone knowing about it. Which is great. But these little success stories can make all the difference. It motivates me to keep pounding out the development hours, it encourages other people to try it, and it'd be a good thing to be able to point at if I tried to raise more funding now that I'm out of Kickstarter money.
I'm posting my own success story to my main blog: git annex and my mom
If you have a success story to share, why not blog about it, microblog it, or just post a comment here, or even send me a private message. Just a quick note is fine. Thanks!
Going through the bug reports and questions today, I ended up fixing three separate bugs that could break setting up a repo on a remote ssh server from the webapp.
Also developed a minimal test case for some gnucash behavior that prevents the watcher from seeing files it writes out. I understand the problem, but don't have a fix for that yet. Will have to think about it. (A year ago today, my blog featured the first release of the watcher.)
Pushed out a release today. While I've somewhat ramped down activity this month with the Kickstarter period over and summer trips and events ongoing, looking over the changelog I still see a ton of improvements in the 20 days since the last release.
Been doing some work to make the assistant daemon be more nice. I don't
want to nice the whole program, because that could make the web interface
unresponsive. What I am able to do, thanks to Linux violating POSIX, is to
nice certain expensive operations, including the startup scan and the daily
sanity check. Also, I put in a call to ionice (when it's available)
when git annex assistant --autostart is run, so the daemon's
disk IO will be prioritized below other IO. Hope this keeps it out of your
way while it does its job.
One of my Windows fixes yesterday got the test suite close to sort of working on Windows, and I spent all day today pounding on it. Fixed numerous bugs, and worked around some weird Windows behaviors -- like recursively deleting a directory sometimes fails with a permission denied error about a file in it, and leaves behind an empty directory. (What!?) The most important bug I fixed caused CR to leak into files in the git-annex branch from Windows, during a union merge, which was not a good thing at all.
At the end of the day, I only have 6 remaining failing test cases on
Windows. Half of them are some problem where running git annex sync
from the test suite stomps on PATH somehow and prevents xargs from working.
The rest are probably real bugs in the directory (again something to do
with recursive directory deletion, hmmm..), hook, and rsync
special remotes on Windows. I'm punting on those 6 for now, they'll be
skipped on Windows.
Should be worth today's pain to know in the future when I break something that I've oh-so-painfully gotten working on Windows.
Yay, I fixed the Handling of files inside and outside archive directory at the same time bug! At least in direct mode, which thanks to its associated files tracking knows when a given file has another file in the repository with the same content. Had not realized the behavior in direct mode was so bad, or the fix so relatively easy. Pity I can't do the same for indirect mode, but the problem is much less serious there.
That was this weekend. Today, I nearly put out a new release (been 2 weeks since the last one..), but ran out of time in the end, and need to get the OSX autobuilder fixed first, so have deferred it until Friday.
However, I did make some improvements today.
Added an annex.debug git config setting, so debugging can
be turned on persistently. People seem to expect that to happen when
checking the checkbox in the webapp, so now it does.
Fixed 3 or 4 bugs in the Windows port. Which actually, has users now, or at least one user. It's very handy to actually get real world testing of that port.
Today I got to deal with bugs on Android (busted use of cp among other
problems), Windows (fixed a strange hang when adding several files), and
Linux (.desktop files suck and Wine ships a particularly nasty one).
Pretty diverse!
Did quite a lot of research and thinking on XMPP encryption yesterday, but
have not run any code yet (except for trying out a D-H exchange in ghci).
I have listed several options on the XMPP page.
Planning to take a look at Handling of files inside and outside archive directory at the same time tomorrow; maybe I can come up with a workaround to avoid it behaving so badly in that case.
Got caught up on my backlog yesterday.
Part of adding files in direct mode involved removing write permission from them temporarily. That turned out to cause problems with some programs that open a file repeatedly, and was generally against the principle that direct mode files are always directly available. Happily, I was able to get rid of that without sacrificing any safety.
Improved syncing to bare repositories. Normally syncing pushes to a synced/master branch, which is good for non-bare repositories since git does not allow pushing to the currently checked out branch. But for bare repositories, this could leave them without a master branch, so cloning from them wouldn't work. A funny thing is that git does not really have any way to tell if a remote repository is bare or not. Anyway, I did put in a fix, at the expense of pushing twice (but the git data should only be transferred once anyway).
Slowly getting through the bugs that were opened while I was on vacation and then I'll try to get to all the comments. 60+ messages to go.
Got git-annex working better on encfs, which does not support hard links in paranoid mode. Now git-annex can be used in indirect mode, it doesn't force direct mode when hard links are not supported.
Made the Android repository setup special case generate a .gitignore file to ignore thumbnails. Which will only start working once the assistant gets .gitignore support.
Been thinking today about encrypting XMPP traffic, particularly git push data. Of course, XMPP is already encrypted, but that doesn't hide it from those entities who have access to the XMPP server or its encryption key. So adding client-to-client encryption has been on the TODO list all along.
OTR would be a great way to do it. But I worry that the confirmation steps OTR uses to authenticate the recipient would make the XMPP pairing UI harder to get through.
Particularly when pairing your own devices over XMPP, with several devices involved, you'd need to do a lot of cross-confirmations. It would be better there, I think, to just use a shared secret for authentication. (The need to enter such a secret on each of your devices before pairing them would also provide a way to use different repositories with the same XMPP account, so 2birds1stone.)
Maybe OTR confirmations would be ok when setting up sharing with a friend. If OTR was not used there, and it just did a Diffie-Hellman key exchange during the pairing process, it could be attacked by an active MITM spoofing attack. The attacker would then know the keys, and could decrypt future pushes. How likely is such an attack? This goes far beyond what we're hearing about. Might be best to put in some basic encryption now, so we don't have to worry about pushes being passively recorded on the server. Comments appreciated.
Today marks 1 year since I started working on the git-annex assistant. 280 solid days of work!
As a background task here at the beach I've been porting git-annex to yesod 1.2. Finished it today, earlier than expected, and also managed to keep it building with older versions. Some tricks kept the number of ifdefs reasonably low.
Landed two final changes before the release..
First, made git-annex detect if any of the several long-running git process
it talks to have died, and, if yes, restart them. My stress test is reliably
able to get at least git cat-file to crash, and while I don't know why (and
obviously should follow up by getting a core dump and stack trace of it),
the assistant needs to deal with this to be robust.
Secondly, wrote rather a lot of Java code to better open the web browser
when the Android app is started. A thread listens for URLs to be written to
a FIFO. Creating a FIFO from fortran^Wjava code is .. interesting. Glad to
see the back of the am command; it did me no favors.
AFK
Winding down work for now, as I prepare for a week at the beach starting in 2 days. That will be followed by a talk about git-annex at SELF2013 in Charlotte NC on June 9th.
Bits & pieces today.
Want to get a release out RSN, but I'm waiting for the previous release to finally reach Debian testing, which should happen on Saturday. Luckily I hear the beach house has wifi, so I will probably end up cutting the release from there. Only other thing I might work on next week is updating to yesod 1.2.
Yeah, Java hacking today. I have something that I think should deal with the ?Android app permission denial on startup problem. Added a "Open WebApp" item to the terminal's menu, which should behave as advertised. This is available in the Android daily build now, if your device has that problem.
I was not able to get the escape sequence hack to work. I had no difficulty modifying the terminal to send an intent to open an url when it received a custom escape sequence. But sending the intent just seemed to lock up the terminal for a minute without doing anything. No idea why. I had to propigate a context object in to the terminal emulator through several layers of objects. Perhaps that doesn't really work despite what I read on stackoverflow.
Anyway, that's all I have time to do. It would be nice if I, or some other interested developer who is more comfortable with Java, could write a custom Android frontend app, that embedded a web browser widget for the webapp, rather than abusing the terminal this way. OTOH, this way does provide the bonus of a pretty good terminal and git shell environment for Android to go with git-annex.
The fuzz testing found a file descriptor leak in the XMPP git push code. The assistant seems to hold up under fuzzing for quite a while now.
Have started trying to work around some versions of Android not letting
the am command be used by regular users to open a web browser on an URL.
Here is my current crazy plan: Hack the terminal emulator's title setting
code, to get a new escape sequence that requests an URL be opened. This
assumes I can just use startActivity() from inside the app and it will
work. This may sound a little weird, but it avoids me needing to set up a
new communications channel from the assistant to the Java app. Best of all,
I have to write very little Java code. I last wrote Java code in 1995, so
writing much more is probably a good thing to avoid.
Fuzz tester has found several interesting bugs that I've now fixed. It's even found a bug in my fixes. Most of the problems the fuzz testing has found have had to do with direct mode merges, and automatic merge conflict resoltion. Turns out the second level of automatic merge conflict resolution (where the changes made to resolve a merge conflict themselves turn out conflict in a later merge) was buggy, for example.
So, didn't really work a lot today -- was not intending to work at all actually -- but have still accomplished a lot.
(Also, Tobias contributed dropboxannex .. I'll be curious to see what the use case for that is, if any!)
Got caught up on some bug reports yesterday. The main one was odd behavior of the assistant when the repository was in manual mode. A recent change to the preferred content expression caused it. But the expression was not broken. The problem was in the parser, which got the parentheses wrong in this case. I had to mostly rewrite the parser, unfortunately. I've tested the new one fairly extensively -- on the other hand this bug lurked in the old parser for several years (this same code is used for matching files with command-line parameters).
Just as I finished with that, I noticed another bug. Turns out git-cat-file doesn't reload the index after it's started. So last week's changes to make git-annex check the state of files in the index won't work when using the assistant. Luckily there was an easy workaround for this.
Today I finished up some robustness fixes, and added to the test suite checks for preferred content expressions, manual mode, etc.
I've started a stress test, syncing 2 repositories over XMPP, with the fuzz tester running in each to create lots of changes to keep in sync.
The Android app should work on some more devices now, where hard linking to busybox didn't work. Now it installs itself using symlinks.
Pushed a point release so cabal install git-annex works again. And,
I'm really happy to see that the 4.20130521 release has autobuilt on all
Debian architectures, and will soon be replacing the old 3.20120629 version
in testing. (Well, once a libffi transition completes..)
TobiasTheMachine has done it again: ?googledriveannex
I spent most of today building a fuzz tester for the assistant. git annex
fuzztest will (once you find the special runes to allow it to run) create
random files in the repository, move them around, delete them, move
directory trees around, etc. The plan is to use this to run some long
duration tests with eg, XMPP, to make sure the assistant keeps things
in shape after a lot of activity. It logs in machine-readable format,
so if it turns up a bug I may even be able to use it to reproduce the same
bug (fingers crossed).
I was able to use QuickCheck to generate random data for some parts of the fuzz tester. (Though the actual file names it uses are not generated using QuickCheck.) Liked this part:
instance Arbitrary FuzzAction where
arbitrary = frequency
[ (100, FuzzAdd <$> arbitrary)
, (10, FuzzDelete <$> arbitrary)
, (10, FuzzMove <$> arbitrary <*> arbitrary)
, (10, FuzzModify <$> arbitrary)
, (10, FuzzDeleteDir <$> arbitrary)
, (10, FuzzMoveDir <$> arbitrary <*> arbitrary)
, (10, FuzzPause <$> arbitrary)
]
Tobias has been busy again today, creating a flickrannex special remote! Meanwhile, I'm thinking about providing a ?more complete interface so that special remote programs not written in Haskell can do some of the things the hook special remote's simplicity doesn't allow.
Finally realized last night that the main problem with the XMPP push code was an inversion of control. Reworked it so now there are two new threads, XMPPSendpack and XMPPReceivePack, each with their own queue of push initiation requests, that run the pushes. This is a lot easier to understand, probably less buggy, and lets it apply some smarts to squash duplicate actions and pick the best request to handle next.
Also made the XMPP client send pings to detect when it has been disconnected from the server. Currently every 120 seconds, though that may change. Testing showed that without this, it did not notice (for at least 20 minutes) when it lost routing to the server. Not sure why -- I'd think the TCP connections should break and this throw an error -- but this will also handle any idle disconnection problems that some XMPP servers might have.
While writing that, I found myself writing this jem using async, which has a comment much longer than the code, but basically we get 4 threads that are all linked, so when any dies, all do.
pinger `concurrently` sender `concurrently` receiver
Anyway, I need to run some long-running XMPP push tests to see if I've really ironed out all the bugs.
Got the bugfix release out.
Tobias contributed megaannex, which allows using mega.co.nz as a special remote. Someone should do this with Flickr, using filr. I have improved the hook special remote to make it easier to create and use reusable programs like megaannex.
But, I am too busy rewriting lots of the XMPP code to join in the special remote fun. Spent all last night staring at protocol traces and tests, and came to the conclusion that it's working well at the basic communication level, but there are a lot of bugs above that level. This mostly shows up as one side refusing to push changes made to its tree, although it will happily merge in changes sent from the other side.
The NetMessanger code, which handles routing messages to git commands and queuing other messages, seems to be just wrong. This is code I wrote in the fall, and have basically not touched since. And it shows. Spent 4 hours this morning rewriting it. Went all Erlang and implemented message inboxes using STM. I'm much more confident it won't drop messages on the floor, which the old code certainly did do sometimes.
Added a check to avoid unnecessary pushes over XMPP. Unfortunately, this required changing the protocol in a way that will make previous versions of git-annex refuse to accept any pushes advertised by this version. Could not find a way around that, but there were so many unnecessary pushes happening (and possibly contributing to other problems) that it seemed worth the upgrade pain.
Will be beating on XMPP a bit more. There is one problem I was seeing
last night that I cannot reproduce now. It may have been masked or even
fixed by these changes, but I need to verify that, or put in a workaround.
It seemed that sometimes this code in runPush would run the setup
and the action, but either the action blocked forever, or an exception
got through and caused the cleanup not to be run.
r <- E.bracket_ setup cleanup <~> a
Worked on several important bug fixes today. One affects automatic merge confict resolution, and can case data loss in direct mode, so I will be making a release with the fix tomorrow.
Practiced TDD today, and good thing too. The new improved test suite turned up a really subtle bug involving the git-annex branch vector clocks-ish code, which I also fixed.
Also, fixes to the OSX autobuilds. One of them had a broken gpg, which is now fixed. The other one is successfully building again. And, I'm switching the Linux autobuilds to build against Debian stable, since testing has a new version of libc now, which would make the autobuilds not work on older systems. Getting an amd64 chroot into shape is needing rather a lot of backporting of build dependencies, which I already did for i386.
Today I had to change the implementation of the Annex monad. The old one turned out to be buggy around exception handling -- changes to state recorded by code that ran in an exception handler were discarded when it threw an exception. Changed from a StateT monad to a ReaderT with a MVar. Really deep-level change, but it went off without a hitch!
Other than that it was a bug catch up day. Almost entirely caught up once more.
git-annex is now autobuilt for Windows on the same Jenkins farm that builds msysgit. Thanks for Yury V. Zaytsev for providing that! Spent about half of today setting up the build.
Got the test suite to pass in direct mode, and indeed in direct mode
on a FAT file system. Had to fix one corner case in direct mode git annex
add. Unfortunately it still doesn't work on Android; somehow git clone
of a local repository is broken there. Also got the test suite to build,
and run on Windows, though it fails pretty miserably.
Made a release.
I am firming up some ideas for post-kickstarter. More on that later.
In the process of setting up a Windows autobuilder, using the same jenkins installation that is used to autobuild msysgit.
Laid some groundwork for porting the test suite to Windows, and getting it
working in direct mode. That's not complete, but even starting to run the
test suite in direct mode and looking at all the failures (many of them
benign, like files not being symlinks) highlighted something
I have been meaning to look into for quite a while: Why, in direct mode,
git-annex doesn't operate on data staged in the index, but requires you
commit changes to files before it'll see them. That's an annoying
difference between direct and indirect modes.
It turned out that I introduced this behavior back on
January 5th, working around a nasty
bug I didn't understand. Bad Joey, should have root caused the bug at the
time! But the commit says I was stuck on it for hours, and it was
presenting as if it was a bug in git cat-file itself, so ok. Anyway,
I quickly got to the bottom of it today, fixed the underlying bug (which
was in git-annex, not git itself), and got rid of the workaround and its
undesired consequences. Much better.
The test suite is turning up some other minor problems with direct mode. Should have found time to port it earlier.
Also, may have fixed the issue that was preventing GTalk from working on Android. (Missing DNS library so it didn't do SRV lookups right.)
The Windows port can now do everything in the walkthrough. It can use both local and remote git repositories. Some special remotes work (directory at least; probably rsync; likely any other special remote that can have its dependencies built). Missing features include most special remotes, gpg encryption, and of course, the assistant.
Also built a NullSoft installer for git-annex today. This was made very easy when I found the Haskell ncis library, which provides a DSL embedding the language used to write NullSoft installers into Haskell. So I didn't need to learn a new language, yay! And could pull in all my helpful Haskell utility libraries in the program that builds the installer.
The only tricky part was: How to get git-annex onto PATH? The standard way to do this seems to be to use a multiple-hundred line include file. Of course, that file does not have any declared license.. Instead of that, I used a hack. The git installer for Windows adds itself to PATH, and is a pre-requisite for git-annex. So the git-annex installer just installs it into the same directory as git.
So.. I'll be including this first stage Windows port, with installer in the next release. Anyone want to run a Windows autobuilder?
Spent some time today to get caught up on bug reports and website traffic. Fixed a few things.
Did end up working on Windows for a while too. I got git annex drop
working. But nothing that moves content quite works yet..
I've run into a stumbling block with rsync. It thinks that
C:\repo is a path on a ssh server named "C". Seems I will need to translate
native windows paths to unix-style paths when running rsync.
It's remarkable that a bad decision made in 1982 can cause me to waste an
entire day in 2013. Yes, / vs \ fun time. Even though I long ago
converted git-annex to use the haskell </> operator wherever it builds
up paths (which transparently handles either type of separator), I still
spent most of today dealing with it. Including some libraries I use that
get it wrong. Adding to the fun is that git uses / internally, even on
Windows, so Windows separated paths have to be converted when being fed
into git.
Anyway, git annex add now works on Windows. So does git annex find,
and git annex whereis, and probably most query stuff.
Today was very un-fun and left me with a splitting headache, so I will certainly not be working on the Windows port tomorrow.
After working on it all day, git-annex now builds on Windows!
Even better, git annex init works. So does git annex status, and
probably more. Not git annex add yet, so I wasn't able to try much more.
I didn't have to add many stubs today, either. Many of the missing Windows features were only used in code paths that made git-annex faster, but I could fall back to a slower code path on Windows.
The things that are most problematic so far:
- POSIX file locking. This is used in git-annex in several places to make it safe when multiple git-annex processes are running. I put in really horrible dotfile type locking in the Windows code paths, but I don't trust it at all of course.
- There is, apparently, no way to set an environment variable in Windows from Haskell. It is only possible to set up a new process' environment before starting it. Luckily most of the really crucial environment variable stuff in git-annex is of this latter sort, but there were a few places I had to stub out code that tries to manipulate git-annex's own environment.
The windows branch has a diff of 2089 lines. It add 88 ifdefs to the code
base. Only 12 functions are stubbed out on Windows. This could be so much
worse.
Next step: Get the test suite to build. Currently ifdefed out because it
uses some stuff like setEnv and changeWorkingDirectory that I don't know
how to do in Windows yet.
Set up my Windows development environment. For future reference, I've installed:
- haskell platform for windows
- cygwin
- gcc and a full C toolchain in cygwin
- git from upstream (probably git-annex will use this)
- git in cygwin (the other git was not visible inside cygwin)
- vim in cygwin
- vim from upstream, as the cygwin vim is not very pleasant to use
- openssh in cygwin (seems to be missing a ssh server)
- rsync in cygwin
- Everything that
cabal install git-annexis able to install successfully.
This includes all the libraries needed to build regular git-annex, but not the webapp. Good start though.
Result basically feels like a linux system that can't decide which way slashes in paths go. :P I've never used Cygwin before (I last used a Windows machine in 2003 for that matter), and it's a fairly impressive hack.
Fixed up git-annex's configure program to run on Windows (or, at least, in Cygwin), and have started getting git-annex to build.
For now, I'm mostly stubbing out functions that use unix stuff. Gotten the first 44 of 300 source files to build this way.
Once I get it to build, if only with stubs, I'll have a good idea about all the things I need to find Windows equivilants of. Hopefully most of it will be provided by http://hackage.haskell.org/package/unix-compat-0.3.0.1.
So that's the plan. There is a possible shortcut, rather than doing a full port. It seems like it would probably not be too hard to rebuild ghc inside Cygwin, and the resulting ghc would probably have a full POSIX emulation layer going through cygwin. From ghc's documentation, it looks like that's how ghc used to be built at some point in the past, so it would probably not be too hard to build it that way. With such a cygwin ghc, git-annex would probably build with little or no changes. However, it would be a git-annex targeting Cygwin, and not really a native Windows port. So it'd see Cygwin's emulated POSIX filesystem paths, etc. That seems probably not ideal for most windows users.. but if I get really stuck I may go back and try this method.
It all came together for Android today. Went from a sort of working app to a fully working app!
- rsync.net works.
- Box.com appears to work -- at least it's failing with the same timeout I get on my linux box here behind the firewall of dialup doom.
- XMPP is working too!
These all needed various little fixes. Like loading TLS certificates from where they're stored on Android, and ensuring that totally crazy file permissions from Android (----rwxr-x for files?!) don't leak out into rsync repositories. Mostly though, it all just fell into place today. Wonderful..
The Android autobuild is updated with all of today's work, so try it out.
Fixed a nasty bug that affects at least some FreeBSD systems. It misparsed
the output of sha256, and thought every file had a SHA256 of "SHA256".
Added multiple layers of protection against checksum programs not having
the expected output format.
Lots more building and rebuilding today of Android libs than I wanted to do. Finally have a completly clean build, which might be able to open TCP connections. Will test tomorrow.
In the meantime, I fired up the evil twin of my development laptop. It's identical, except it runs Windows.
I installed the Haskell Platform for Windows on it, and removed some of the bloatware to free up disk space and memory for development. While a rather disgusting experience, I certainly have a usable Haskell development environment on this OS a lot faster than I did on Android! Cabal is happily installing some stuff, and other stuff wants me to install Cygwin.
So, the clock on my month of working on a Windows port starts now. Since I've already done rather a lot of ground work that was necessary for a Windows port (direct mode, crippled filesystem support), and for general sanity and to keep everything else from screeching to a halt, I plan to only spend half my time messing with Windows over the next 30 days.
Put in a fix for getprotobyname apparently not returning anything for
"tcp" on Android. This might fix all the special remotes there, but I don't
know yet, because I have to rebuild a lot of Haskell libraries to try it.
So, I spent most of today writing a script to build all the Haskell libraries for Android from scratch, with all my patches.
This seems a very auspicious day to have finally gotten the Android app doing something useful! I've fixed the last bugs with using it to set up a remote ssh server, which is all I need to make my Android tablet sync photos I take with a repository on my laptop.
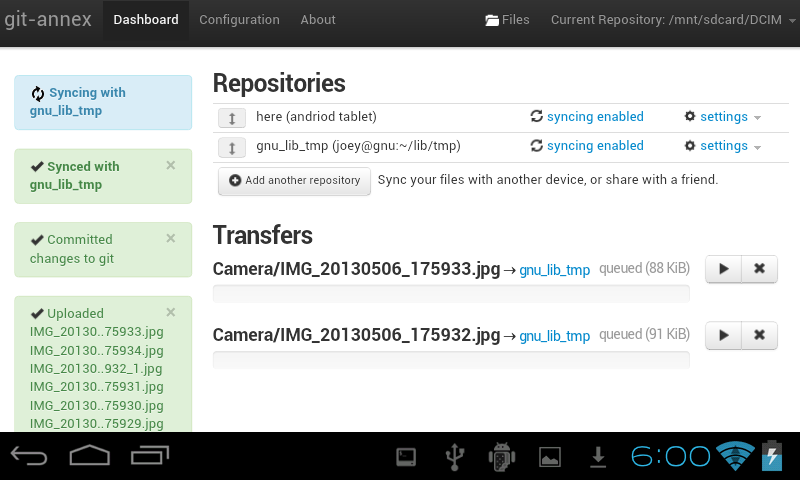
I set this up entirely in the GUI, except for needing to switch to the terminal twice to enter my laptop's password.
How fast is it? Even several minute long videos transfer before I can
switch from the camera app to the webapp. To get this screenshot with it in
the process of syncing, I had to take a dozen pictures in a minute. Nice
problem to have.
Have fun trying this out for yourself after tonight's autobuilds. But a
warning: One of the bugs I fixed today had to be fixed in git-annex-shell,
as run on the ssh server that the Android connects to. So the Android app
will only work with ssh servers running a new enough version of git-annex.
Worked on geting git-annex into Debian testing, which is needed before the wheezy backport can go in. Think I've worked around most of the issues that were keeping it from building on various architectures.
Caught up on some bug reports and fixed some of them.
Created a backport of the latest git-annex release for Debian 7.0 wheezy. Needed to backport a dozen haskell dependencies, but not too bad. This will be available in the backports repository once Debian starts accepting new packages again. I plan to keep the backport up-to-date as I make new releases.
The cheap Android tablet I bought to do this last Android push with came pre-rooted from the factory. This may be why I have not seen this bug: ?Android app permission denial on startup. If you have Android 4.2.2 or a similar version, your testing would be helpful for me to know if this is a widespread problem. I have an idea about a way to work around the problem, but it involves writing Java code, and probably polling a file, ugh.
Got S3 support to build for Android. Probably fails to work due to the same network stack problems affecting WebDAV and Jabber.
Got removable media mount detection working on Android. Bionic has an
amusing stub for getmntent that prints out "FIX ME! implement
getmntent()". But, /proc/mounts is there, so I just parse it.
Also enabled the app's WRITE_MEDIA_STORAGE permission to allow
access to removable media. However, this didn't seem to do anything. 
Several fixes to make the Android webapp be able to set up repositories on
remote ssh servers. However, it fails at the last hurdle with what
looks like a git-annex-shell communication problem. Almost there..
There's a new page Android that documents using git-annex on Android in detail.
The Android app now opens the webapp when a terminal window is opened. This is good enough for trying it out easily, but far from ideal.
Fixed an EvilSplicer bug that corrupted newlines in the static files served by the webapp. Now the icons in the webapp display properly, and the javascript works.
Made the startup screen default to /sdcard/annex for the repository
location, and also have a button to set up a camera repository. The camera
repository is put in the "source" preferred content group, so it will only
hang onto photos and videos until they're uploaded off the Android device.
Quite a lot of other small fixes on Android. At this point I've tested the following works:
- Starting webapp.
- Making a repository, adding files.
- All the basic webapp UI.
However, I was not able to add any remote repository using only the webapp, due to some more problems with the network stack.
- Jabber and Webdav don't quite work ("getProtocolByname: does not exist (no such protocol name: tcp)").
- SSH server fails. ("Network/Socket/Types.hsc:(881,3)-(897,61): Non-exhaustive patterns in case") I suspect it will work if I disable the DNS expansion code.
So, that's the next thing that needs to be tackled.
If you'd like to play with it in its current state, I've updated the Android builds to incorporate all my work so far.
I fixed what I thought was keeping the webapp from working on Android, but
then it started segfaulting every time it was started. Eventually I
determined this segfault happened whenever haskell code called
getaddrinfo. I don't know why. This is particularly weird since I had
a demo web server that used getaddrinfo working way back in
day 201 real Android wrapup. Anyway, I worked around it by not using
getaddrinfo on Android.
Then I spent 3 hours stuck, because the webapp seemed to run, but
nothing could connect to the port it was on. Was it a firewall? Was
the Haskell threaded runtime's use of accept() broken? I went all the way
down to the raw system calls, and back, only to finally notice I had netstat
available on my Android. Which showed it was not listening to the port I
thought it was!
Seems that ntohs and htons are broken somehow. To get the
screenshot, I fixed up the port manually. Have a build running that
should work around the issue.
Anyway, the webapp works on Android!
Pushed out a release today. Looking back over April, I'm happy with it as a bug fix and stabilization month. Wish I'd finished the Android app in April, but let's see what happens tomorrow.
Recorded part of a screencast on using Archive.org, but recordmydesktop
lost the second part. Grr. Will work on that later.
Took 2 days in a row off, because I noticed I have forgotten to do that since February, or possibly earlier, not counting trips. Whoops!
Also, I was feeling overwhelmed with the complexity of fixing XMPP to not be buggy when there are multiple separate repos using the same XMPP account. Let my subconscious work on that, and last night it served up the solution, in detail. Built it today.
It's only a partial solution, really. If you want to use the same XMPP account for multiple separate repositories, you cannot use the "Share with your other devices" option to pair your devices. That's because XMPP pairing assumes all your devices are using the same XMPP account, in order to avoid needing to confirm on every device each time you add a new device. The UI is clear about that, and it avoids complexity, so I'm ok with that.
But, if you want to instead use "Share with a friend", you now can use the same XMPP account for as many separate repositories as you like. The assistant now ignores pushes from repositories it doesn't know about. Before, it would merge them all together without warning.
While I was testing that, I think I found out the real reason why XMPP
pushes have seemed a little unreliable. It turns out to not be an XMPP
issue at all! Instead, the merger was simply not always
noticing when git receive-pack updated a ref, and not merging it into
master. That was easily fixed.
Adam Spiers has been getting a .gitignore query interface suitable for
the assistant to use into git, and he tells me it's landed in next.
I should soon check that out and get the assistant using it. But first,
Android app!
Turns out my old Droid has such an old version of Android (2.2) that it doesn't work with any binaries produced by my haskell cross-compiler. I think it's using a symbol not in its version of libc. Since upgrading this particular phone is a ugly process and the hardware is dying anyway (bad USB power connecter), I have given up on using it, and ordered an Android tablet instead to use for testing. Until that arrives, no Android. Bah. Wanted to get the Android app working in April.
Instead, today I worked on making the webapp require less redundant password entry when adding multiple repositories using the same cloud provider. This is especially needed for the Internet Archive, since users will often want to have quite a few repositories, for different IA items. Implemented it for box.com, and Amazon too.
Francois Marier has built an Ubuntu PPA for git-annex, containing the current version, with the assistant and webapp. It's targeted at Precise, but I think will probably also work with newer releases. https://launchpad.net/~fmarier/+archive/ppa
Probably while I'm waiting to work on Android again, I will try to improve the situation with using a single XMPP account for multiple repositories. Spent a while today thinking through ways to improve the design, and have some ideas.
Quiet day. Only did minor things, like adding webapp UI for changing the
directory used by Internet Archive remotes, and splitting out an
enableremote command from initremote.
My Android development environment is set up and ready to go on my Motorola Droid. The current Android build of git-annex fails to link at run time, so my work is cut out for me. Probably broke something while enabling XMPP?
Very productive & long day today, spent adding a new feature to the webapp: Internet Archive support!
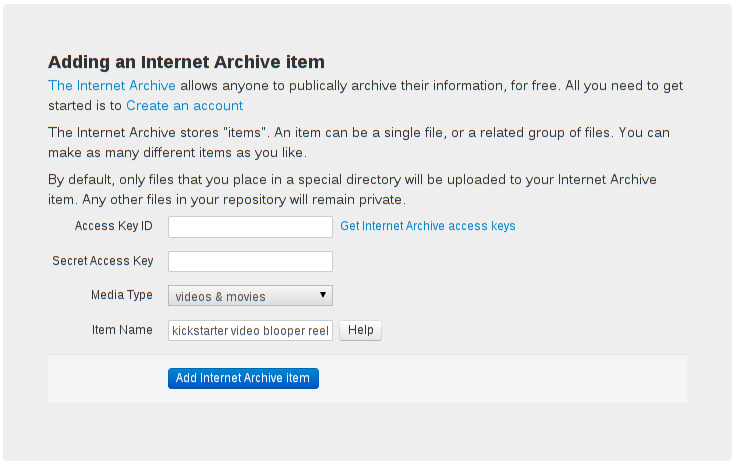
git-annex already supported using archive.org via its S3 special remotes, so this is just a nice UI around that.
How does it decide which files to publish on archive.org? Well, the item has a unique name, which is based on the description field. Any files located in a directory with that name will be uploaded to that item. (This is done via a new preferred content expression I added.)
So, you can have one repository with multiple IA items attached, and sort files between them however you like. I plan to make a screencast eventually demoing that.
Another interesting use case, once the Android webapp is done, would be add a repository on the DCIM directory, set the archive.org repository to prefer all content, and bam, you have a phone or tablet that auto-publishes and archives every picture it takes.
Another nice little feature added today is that whenever a file is uploaded
to the Internet Archive, its public url is automatically recorded, same
as if you'd ran git annex addurl. So any users who can clone your
repository can download the files from archive.org, without needing any
login or password info. This makes the Internet Archive a nice way to
publish the large files associated with a public git repository.
Working on assistant's performance when it has to add a whole lot of files (10k to 100k).
Improved behavior in several ways, including fixing display of the alert in the webapp when the default inotify limit of 8192 directories is exceeded.
Created a new TList data type, a transactional DList. Much nicer implementation than the TChan based thing it was using to keep track of the changes, although it only improved runtime and memory usage a little bit. The way that this is internally storing a function in STM and modifying that function to add items to the list is way cool.
Other tuning seems to have decreased the time it would take to import 100k files from somewhere in the range of a full day (too long to wait to see), to around 3.5 hours. I don't know if that's good, but it's certainly better.
There seem to be a steady state of enough bug reports coming in that I can work on them whenever I'm not working on anything else. As I did all day today.
This doesn't bother me if the bug reports are of real bugs that I can reproduce and fix, but I'm spending a lot of time currently following up to messages and asking simple questions like "what version number" and "can I please see the whole log file". And just trying to guess what a vague problem report means and read people's minds to get to a definite bug with a test case that I can then fix.
I've noticed the overall quality of bug reports nosedive over the past several months. My guess is this means that git-annex has found a less technical audience. I need to find something to do about this.
With that whining out of the way ... I fixed a pretty ugly bug on FAT/Android today, and I am 100% caught up on messages right now!
Got the OSX autobuilder back running, and finally got a OSX build up for the 4.20130417 release. Also fixed the OSX app build machinery to handle rpath.
Made the assistant (and git annex sync) sync with git remotes that have
annex-ignore set. So, annex-ignore is only used to prevent using
the annex of a remote, not syncing with it. The benefit of this change
is that it'll make the assistant sync the local git repository with
a git remote that is on a server that does not have git-annex installed.
It can even sync to github.
Worked around more breakage on misconfigured systems that don't have GECOS information.
... And other bug fixes and bug triage.
Ported all the C libraries needed for XMPP to Android. (gnutls, libgcrypt, libgpg-error, nettle, xml2, gsasl, etc). Finally got it all to link. What a pain.
Bonus: Local pairing support builds for Android now, seems recent changes to the network library for WebDAV also fixed it.
Today was not a work day for me, but I did get a chance to install git-annex in real life while visiting. Was happy to download the standalone Linux tarball and see that it could be unpacked, and git-annex webapp started just by clicking around in the GUI. And in very short order got it set up.
I was especially pleased to see my laptop noticed this new repository had appeared on the network via XMPP push, and started immediately uploading files to my rsync.net transfer repository so the new repository could get them.
Did notice that the standalone tarball neglected to install a FDO menu file. Fixed that, and some other minor issues I noticed.
I also got a brief chance to try the Android webapp. It fails to start;
apparently getaddrinfo doesn't like the flags passed to it and is
failing. As failure modes go, this isn't at all bad. I can certainly work
around it with some hardcoded port numbers, but I want to fix it the right
way. Have ordered a replacement battery for my dead phone so I can use it
for Android testing.
Got WebDAV enabled in the Android build. Had to deal with some system calls not available in Android's libc.
New poll: Android default directory
Finished the last EvilSplicer tweak and other fixes to make the Android webapp build without any hand-holding.
Currently setting up the Android autobuilder to include the webapp in its builds. To make this work I had to set up a new chroot with all the right stuff installed.
Investigated how to make the Android webapp open a web browser when run.
As far as I can tell (without access to an Android device right now),
am start -a android.intent.action.VIEW -d http://localhost/etc should do
it.
Seems that git 1.8.2 broke the assistant. I've put in a fix but have not yet tested it.
Late last night, I successfully built the full webapp for Android!
That was with several manual modifications to the generated code, which I still need to automate. And I need to set up the autobuilder properly still. And I need to find a way to make the webapp open Android's web browser to URL. So it'll be a while yet until a package is available to try. But what a milestone!
The point I was stuck on all day yesterday was generated code that looked like this:
(toHtml
(\ u_a2ehE -> urender_a2ehD u_a2ehE []
(CloseAlert aid)))));
That just couldn't type check at all. Most puzzling. My best guess is that
u_a2ehE is the dictionary GHC passes internally to make a typeclass work,
which somehow leaked out and became visible. Although
I can't rule out that I may have messed something up in my build environment.
The EvilSplicer has a hack in it that finds such code and converts it to
something like this:
(toHtml
(flip urender_a2ehD []
(CloseAlert aid)))));
I wrote some more about the process of the Android port in my personal blog: Template Haskell on impossible architectures
Release day today. The OSX builds are both not available yet for this release, hopefully will come out soon.
Several bug fixes today, and got mostly caught up on recent messages. Still have a backlog of two known bugs that I cannot reproduce well enough to have worked on, but I am thinking I will make a release tomorrow. There have been a lot of changes in the 10 days since the last release.
I am, frustratingly, stuck building the webapp on Android with no forward progress today (and last night) after such a productive day yesterday.
The expanded Template Haskell code of the webapp fails to compile, whereever type safe urls are used.
Assistant/WebApp/Types.hs:95:63:
Couldn't match expected type `Route WebApp -> t2'
with actual type `Text'
The function `urender_a1qcK' is applied to three arguments,
but its type `Route WebApp -> [(Text, Text)] -> Text' has only two
In the expression: urender_a1qcK u_a1qcL [] LogR
In the first argument of `toHtml', namely
`(\ u_a1qcL -> urender_a1qcK u_a1qcL [] LogR)'
My best guess is this is a mismatch between the versions of yesod (or other libraries) used for the native and cross compiled ghc's. So I've been slowly trying to get a fully matched set of versions in between working on bugs.
Back to really working toward an Android webapp now. I have been improving the EvilSplicer, and the build machinery, and build environment all day. Slow but steady progress.
First milestone of the day was when I got yesod-form to build with all
Template Haskell automatically expanded by the EvilSplicer. (With a few
manual fixups where it's buggy.)
At this point the Android build with the webapp enabled successfully builds several files containing Yesod code.. And I suspect I am very close to getting a first webapp build for Android.
Fixed a bug where the locked down ssh key that the assistant sets up to access the annex on a remote server was being used by ssh by default for all logins to that server.
That should not have happened. The locked down key is written to a filename
that ssh won't use at all, by default. But, I found code in gnome-keyring
that watches for ~/.ssh/*.pub to appear, and automatically adds all such
keys to the keyring. In at least some cases, probably when it has no other
key, it then tells ssh to go ahead and use that key. Astounding.
To avoid this, the assistant will store its keys in ~/.ssh/annex/~/.ssh/git-annex/ instead. gnome-keyring does not look there (verified in
the source). If you use gnome-keyring and have set up a repository on a
remote server with the assistant, I'd recommend moving the keys it set up
and editing ~/.ssh/config to point to their new location.
gnome-keyring is not the only piece of software that has a bad interaction with git-annex. I've been working on a bug that makes git-annex fail to authenticate to ejabberd. ejabberd 2.1.10 got support for SCRAM-SHA-1, but its code violates the RFC, and chokes on an address attribute that the haskell XMPP library provides. I hope to get this fixed in ejabberd.
Also did some more work on the Evil Splicer today, integrating it into the
build of the Android app, and making it support incremental building.
Improved its code generation, and am at the milestone where it creates
valid haskell code for the entire Assistant/WebApp/Types.hs file,
where Template Haskell expands 2 lines into 2300 lines of code!
Spent today bulding the Evil Splicer, a program that parses ghc -ddump-splices
output, and uses it to expand Template Haskell splices in source code.
I hope to use this crazy hack to get the webapp working on Android.
This was a good opportunity to use the Parsec library for parsing the ghc output. I've never really used it before, but found it quite nice to work with. The learning curve, if you already know monads and applicatives, is about 5 minutes. And instead of ugly regular expressions, you can work with nice code that's easily composable and refactorable. Even the ugly bits come out well:
{- All lines of the splice result will start with the same
- indent, which is stripped. Any other indentation is preserved. -}
i <- lookAhead indent
result <- unlines <$> many1 (string i >> restOfLine)
Anyway, it works.. sorta. The parser works great! The splices that ghc outputs are put into the right places in the source files, and formatted in a way that ghc is able to build. Often though, they contain code that doesn't actually build as-is. I'm working to fix up the code to get closer to buildable.
Meanwhile, guilhem has made ssh connection caching work for rsync special
remotes! It's very nice to have another developer working on git-annex. 
Felt like spending my birthday working on git-annex. Thanks again to everyone who makes it possible for me to work on something I care about every day.
Did some work on git annex addurl today. It had gotten broken in direct
mode (I think by an otherwise good and important bugfix). After fixing
that, I made it interoperate with the webapp. So if you have the webapp
open, it will display progress bars for downloads being run by git annex
addurl.
This enhancement meshes nicely with a FlashGot script Andy contributed, which lets you queue up downloads into your annex from a web browser. Andy described how to set it up in this tip.
(I also looked briefly into ways to intercept a drag and drop of a link into the webapp and make it lauch a download for you. It doesn't seem that browsers allow javascript to override their standard behavior of loading links that are dropped into them. Probably good to prevent misuse, but it would be nice here...)
Also, I think I have fixed the progress bars displayed when downloading a file from an encrypted remote. I did this by hooking up existing download progress metering (that was only being used to display a download percentage in the console) into the location log, so the webapp can use it. So that was a lot easier than it could have been, but still a pretty large patch (500+ lines). Haven't tested this; should work.
Short day because I spent 3 hours this morning explaining free software and kickstarter to an accountant. And was away until 3 pm, so how did I get all this done‽
Eliot pointed out that shutting down the assistant could leave transfers
running. This happened because git annex transferkeys is a separate
process, and so it was left to finish up any transfer that was in
process. I've made shutdown stop all transfers that the
assistant started. (Other paired computers could still be connecting to
make transfers even when the assistant is not running, and those are not
affected.)
Added sequence numbers to the XMPP messages used for git pushes. While
these numbers are not used yet, they're available for debugging, and will
help me determine if packets are lost or come out of order. So if you have
experienced problems with XMPP syncing sometimes failing, run tonight's
build of the assistant with --debug (or turn on debugging in the webapp
configuration screen), and send me a log by email to
debuglogs201204@joeyh.name
Changed the way that autobuilds and manual builds report their version number. It now includes the date of the last commit, and the abbreviated commit ID, rather than being some random date after the last release.
Frederik found a bug using the assistant on a FAT filesystem. It didn't properly handle the files that git uses to stand-in for symlinks in that situation, and annexed those files. I've fixed this, and even moving around symlink stand-in files on a FAT filesystem now results in correct changes to symlinks being committed.
Did my taxes today. Not very pretty. Planning to run them by a professional.
Reproduced a bug that prevents git-annex from authenticating to the ejabberd server, and passed the buck upstream with a test case to the author of the haskell XMPP library.
Added some animations to the webapp to show when it's busy doing things.
Made git annex webapp --listen=address:port work.
Added a annex.web-download-command setting.
Developed a way to run the webapp on a remote or headless computer.
The webapp can now be started on a remote or headless computer, just
specify --listen=address to make it listen on an address other than
localhost. It'll print out the URL to open to access it.
This doesn't use HTTPS yet, because it'd need to generate a certificate, and even if it generated a self-signed SSL certificate, there'd be no easy way for the browser to verify it and avoid a MITM.
So --listen is a less secure but easier option; using ssh to forward
the webapp's port to the remote computer is more secure.
(I do have an idea for a way to do this entirely securely, making the webapp set up the ssh port forwarding, which I have written down in webapp.. but it would be rather complicated to implement.)
Made the webapp rescan for transfers after it's been used to change a repository's group. Would have been easy, but I had to chase down a cache invalidation bug.
Finally fixed the bug causing repeated checksumming when a direct mode file contains duplicate files. I may need to add some cleaning of stale inode caches eventually.
Meanwhile, Guilhem made git annex initremote use higher quality entropy,
with --fast getting back to the old behavior of urandom quality entropy.
The assistant doesn't use high quality entropy since I have no way to
prompt when the user would need to generate more. I did have a fun idea to
deal with this: Make a javascript game, that the user can play while
waiting, which would generate enropy nicely. Maybe one day..
Also made a small but significant change to ?archive directory handling.
Now the assistant syncs files that are in archive directories like any
other file, until they reach an archive repository. Then they get dropped
from all the clients. This way, users who don't set up archive repositories
don't need to know about this special case, and users who do want to use
them can, with no extra configuration.
After recent changes, the preferred content expression for transfer repositories is becoming a bit unweidly, at 212 characters. Probably time to add support for macros..
(not (inallgroup=client and copies=client:2) and (((exclude=*/archive/* and exclude=archive/*) or (not (copies=archive:1 or copies=smallarchive:1))) or (not copies=semitrusted+:1))) or (not copies=semitrusted+:1)
Still, it's pretty great how much this little language lets me express, so easily.
Made a release today. Releasing has sure gotten easier with all the autobuilds to use!
I am now using git-annex to share files with my mom. Here's how the webapp looks for our family's repository. Soon several of us will be using this repository.
We're using XMPP and rsync.net, so pretty standard setup much like shown in my last screencast.
Real-world deployments help find bugs, and I found a few:
If you're running the webapp in
w3mon a remote computer to set it up, some forms are lacking submit buttons. This must be a issue with Bootstrap, or HTML5, I guess. I switched tolynxand it offers a way to submit forms that lack an explicit button.Progress bars for downloads from encrypted rsync repos don't update during the actual download, but only when gpg is decrypting the downloaded file.
XMPP pushes sometimes fail still. Especially when your mom's computer is saturating its limited outgoing network connection uploading hundreds of photos. I have not yet determined if this is a packet loss/corruption issue, or if the XMPP messages are getting out of order. My gut feeling is it's the latter, in which can I can fix this pretty easily by adding sequence numbers and some buffering for out of order packets. Or perhaps just make it retry failed pushes when this happens.
Anyway, I found it was useful to set up a regular git repository on a server to suppliment the git pushes over XMPP. It's helpful to have such a git repository anyway, so that clients can push to there when the other client(s) are not online to be pushed to directly over XMPP.
Got caught up on bug reports and made some bug fixes.
The one bug I was really worried about, a strange file corruption problem on Android, turned out not to be a bug in git-annex. (Nor is it a bug that will affect regular users.)
The only interesting bug fixed was a mixed case hash directory name collision when a repository is put on a VFAT filesystem (or other filesystem with similar semantics). I was able to fix that nicely; since such a repository will be in crippled filesystem mode due to other limitations of the filesystem, and so won't be using symlinks, it doesn't need to use the mixed case hash directory names.
Last night, finished up the repository removal code, and associated UI tweaks. It works very well.
Will probably make a release tomorrow.
Getting back to the repository removal handling from Sunday, I made the assistant detect when a repository that has been marked as unwanted becomes empty, and finish the removal process.
I was able to add this to the expensive transfer scan without making it any
more expensive than it already was, since that scan already looks at the
location of all keys. Although when a remote is detected as empty, it then
does one more check, equivilant to git annex unused, to find any
remaining objects on the remote, and force them off.
I think this should work pretty well, but it needs some testing and probably some UI work.
Andy spotted a bug in the preferred content expressions I was using to
handle untrusted remotes. So he saved me several hours dealing with an ugly
bug at some point down the line. I had misread my own preferred content
expression documentation, and copies=semitrusted:1 was not doing what I
thought it was. Added a new syntax that does what I need,
copies=semitrusted+:1
The 64 bit linux standalone builds are back. Apparently the 32 bit builds have stopped working on recent Fedora, for reasons that are unclear. I set up an autobuilder to produce the 64 bit builds.
The ?xmpp screencast is at long last done!
Fixed a bug that could cause the assistant to unstage files from git sometimes. This happened because of a bad optimisation; adding a file when it's already present and unchanged was optimised to do nothing. But if the file had just been removed, and was put back, this resulted in the removal being staged, and the add not being staged. Ugly bug, although the assistant's daily sanity check automatically restaged the files.
Underlying that bug was a more important problem: git-annex does not always update working tree files atomically. So a crash at just the wrong instant could cause a file to be deleted from the working tree. I fixed that too; all changes to files in the working tree should now be staged in a temp file, which is renamed into place atomically.
Also made a bunch of improvements to the dashboard's transfer display, and to the handling of the underlying transfer queue.
Both the assistant and git annex drop --auto refused to drop files from
untrusted repositories. Got that fixed.
Finally recorded the xmpp pairing screencast. In one perfect take, which
somehow recordmydesktop lost the last 3 minutes of.
Argh! Anyway I'm editing it now, so, look for that screencast soon.
The goals for April poll results are in.
- There have been no votes at all for working on cloud remotes. Seems that git-annex supports enough cloud remotes already.
- A lot of people want the Android webapp port to be done, so I will probably spend some time on that this month.
- Interest in other various features is split. I am surprised how many want git-remote-gcrypt, compared to the features that would make syncing use less bandwidth. Doesn't git push over xmpp cover most of the use cases where git-remote-gcrypt would need to be used with the assistant?
- Nearly as many people as want features, want me to work on bug fixing and polishing what's already there. So I should probably continue to make screencasts, since they often force me to look at things with fresh eyes and see and fix problems. And of course, continue working on bugs as they're reported.
- I'm not sure what to make of the 10% who want me to add direct mode support.
Since direct mode is already used by default, perhaps they want
me to take time off? (I certainly need to fix the
?Direct mode keeps re-checksuming duplicated files bug, and one other
direct mode bug I discovered yesterday.)
I've posted a poll: goals for April
Today added UI to the webapp to delete repositories, which many users have requested. It can delete the local repository, with appropriate cautions and sanity checks:
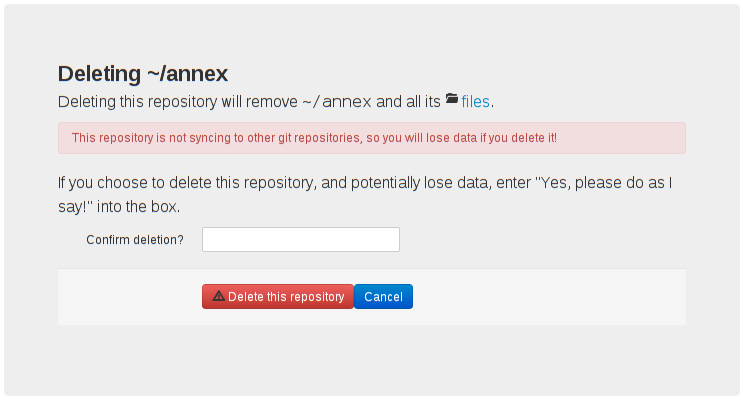
More likely, you'll use it to remove a remote, which is done with no muss and no fuss, since that doesn't delete any data and the remote can always be added back if you change your mind.
It also has an option to fully delete the data on a remote. This doesn't actually delete the remote right away. All it does is marks the remote as untrusted[1], and configures it to not want any content. This causes all the content on it to be sucked off to whatever other repositories can hold it.
I had to adjust the preferred content expressions to make that work. For example, when deleting an archive drive, your local (client) repository does not normally want to hold all the data it has in "archive" directories. With the adjusted preferred content expressions, any data on an untrusted or dead repository is wanted. An interesting result is that once a client repository has moved content from an untrusted remote, it will decide it doesn't want it anymore, and shove it out to any other remote that will accept it. Which is just the behavior we want. All it took to get all this behavior is adding "or (not copies=semitrusted:1)" to the preferred content expressions!
For most special remotes, just sucking the data from them is sufficient to pretty well delete them. You'd want to delete an Amazon bucket or glacier once it's empty, and git repositories need to be fully deleted. Since this would need unique code for each type of special remote, and it would be code that a) deletes possibly large quantities of data with no real way to sanity check it and b) doesn't get run and tested very often; it's not something I'm thrilled about fully automating. However, I would like to make the assistant detect when all the content has been sucked out of a remote, and pop up at least a message prompting to finish the deletion. Future work.
[1] I really, really wanted to mark it dead, but letting puns drive code is probably a bad idea. I had no idea I'd get here when I started developing this feature this morning.. Honest!
Built a feature for power users today. annex.largefiles can be
configured to specify what files git annex add and the assistant should
put into the annex. It uses the same syntax as preferred content,
so arbitrarily complex expressions can be built.
For example, a game written in C with some large data files could include only 100kb or larger files, that are not C code:
annex.largefiles = largerthan=100kb and not (include=*.c or include=*.h)
The assistant will commit small files to git directly!
git annex add, being a lower level tool, skips small files
and leaves it up to you to git add them as desired.
It's even possible to tell the assistant that no file is too large to be
committed directly to git. git config annex.largefiles 'exclude=*'
The result should be much like using SparkleShare or dvcs-autosync.
Also today, made the remote ssh server checking code in the webapp deal with servers where the default shell is csh or some other non-POSIX shell.
Went out and tried for the second time to record a screencast demoing
setting up syncing between two computers using just Jabber and a cloud
remote. I can't record this one at home, or viewers would think git-annex
was crazy slow, when it's just my dialup. But once again I encountered
bugs, and so I found myself working on progress bars today, unexpectedly.
Seems there was confusion in different parts of the progress bar code about whether an update contained the total number of bytes transferred, or the delta of bytes transferred since the last update. One way this bug showed up was progress bars that seemed to stick at 0% for a long time. Happened for most special remotes, although not for rsync or git remotes. In order to fix it comprehensively, I added a new BytesProcessed data type, that is explicitly a total quantity of bytes, not a delta. And checked and fixed all the places that used a delta as that type was knitted into the code.
(Note that this doesn't necessarily fix every problem with progress bars. Particularly, buffering can now cause progress bars to seem to run ahead of transfers, reaching 100% when data is still being uploaded. Still, they should be a lot better than before.)
I've just successfully run through the Jabber + Cloud remote setup process again, and it seems to be working great now. Maybe I'll still get the screencast recorded by the end of March.
Back from my trip. Spent today getting caught up.
Didn't do much while I was away. Pushed out a new release on Saturday.
Made git annex usage display nicer.
Fixed some minor webapp bugs today. The interesting bug was a race that sometimes caused alerts or other notifications to be missed and not be immediately displayed if they occurred while a page was loading. You sometimes had to hit reload to see them, but not anymore!
Checked if the push.default=simple change in upcoming git release will
affect git-annex. It shouldn't affect the assistant, or git annex sync,
since they always list all branches to push explicitly. But if you git push
manually, when the default changes that won't include the git-annex branch
in the push any longer.
Was unsure yesterday if my transferrer pools code would just work, or would be horribly broken and need a lot of work to get going. It was a complex change involving both high-level STM code and low-level pipes and fds. Well, it almost worked 100% first time, I just had a minor issue in my fd setup to fix. Everything else seems to work perfectly. Very happy how that went!
Improved support and documentation for using the OSX app and Linux
standalone tarball at the command line. Now it's sufficient to just put
their directory into PATH, rather than using runshell.
The webapp's form for adding a removable drive now allows specifying the directory to use within the drive (default "annex").
When the drive's repository already exists, and it's not a repository that git-annex knows about, it confirms that the user wants to combine its contents into their repository.
(Should probably implement this same check when adding a ssh remote.)
Off to Boston!
I've been running some large transfers with the assistant, and looking at ways to improve performance. (I also found and fixed a zombie process leak.)
One thing I noticed is that the assistant pushes changes to the git-annex location log quite frequently during a batch transfer. If the files being transferred are reasonably sized, it'll be pushing once per file transfer. It would be good to reduce the number of pushes, but the pushes are important in some network topologies to inform other nodes when a file gets near to them, so they can get the file too.
Need to see if I can find a smart way to avoid some of the pushes. For example, if we've just downloaded a file, and are queuing uploads of the file to a remote, we probably don't need to push the git-annex branch to the remote.
Another performance problem is that having the webapp open while transfers
are running uses significant CPU just for the browser to update the progress
bar. Unsurprising, since the webapp is sending the browser a new <div>
each time. Updating the DOM instead from javascript would avoid that;
the webapp just needs to send the javascript either a full <div> or a
changed percentage and quantity complete to update a single progress bar.
I'd prefer to wait on doing that until I'm able to use Fay to generate Javascript from Haskell, because it would be much more pleasant.. will see.
Also a performance problem when performing lots of transfers, particularly
of small files, is that the assistant forks off a git annex transferkey
for each transfer, and that has to in turn start up several git commands.
Today I have been working to change that, so the assistant maintains a
pool of transfer processes, and dispatches each transfer it wants to make
to a process from the pool. I just got all that to build, although untested
so far, in the transferpools branch.
Triaged some of the older bugs and was able to close a lot of them.
Should mention that I will be in Boston this weekend, attending
LibrePlanet 2013.
Drop by and find me, I'll have git-annex stickers!
Did some UI work on the webapp. Minor stuff, but stuff that needed to be fixed up. Like inserting zero-width spaces into filenames displayed in it so very long filenames always get reasonably wrapped by the browser. (Perhaps there's a better way to do that with CSS?)
Is what I planned to do on git-annex today. Instead I fixed several bugs, but I'm drawing the line at blogging. Oops.
A long time ago I made Remote be an instance of the Ord typeclass, with an implementation that compared the costs of Remotes. That seemed like a good idea at the time, as it saved typing.. But at the time I was still making custom Read and Show instances too. I've since learned that this is not a good idea, and neither is making custom Ord instances, without deep thought about the possible sets of values in a type.
This Ord instance came around and bit me when I put Remotes into a Set, because now remotes with the same cost appeared to be in the Set even if they were not. Also affected putting Remotes into a Map. I noticed this when the webapp got confused about which Remotes were paused.
Rarely does a bug go this deep. I've fixed it comprehensively, first removing the Ord instance entirely, and fixing the places that wanted to order remotes by cost to do it explicitly. Then adding back an Ord instance that is much more sane. Also by checking the rest of the Ord (and Eq) instances in the code base (which were all ok).
While doing that, I found lots of places that kept remotes in Maps and Sets. All of it was probably subtly broken in one way or another before this fix, but it would be hard to say exactly how the bugs would manifest.
Also fought some with Google Talk today. Seem to be missing presence messages sometimes. Ugh. May have fixed it, but I've thought that before..
Made --debug include a sanitized dump of the XMPP protocol.
Made UI changes to encourage user to install git-annex on the server when adding a ssh server, rather than just funneling them through to rsync.
Fixed UI glitches in XMPP username/password prompt.
Switched all forms in the webapp to use POST, to avoid sensitive information leaking on the url bar.
Added an incremental backup group. Repositories in this group only want files that have not been backed up somewhere else yet.
I've reworked the UI of the webapp's dashboard. Now the repository list is included, above the transfers. I found I was spending a lot of time switching between the dashboard and repository list, so might as well combine them into a single screen. Yesod's type safe urls and widgets made this quite easy to do, despite it being a thousand line commit. Liking the result ... Even though it does make all my screencasts dated.
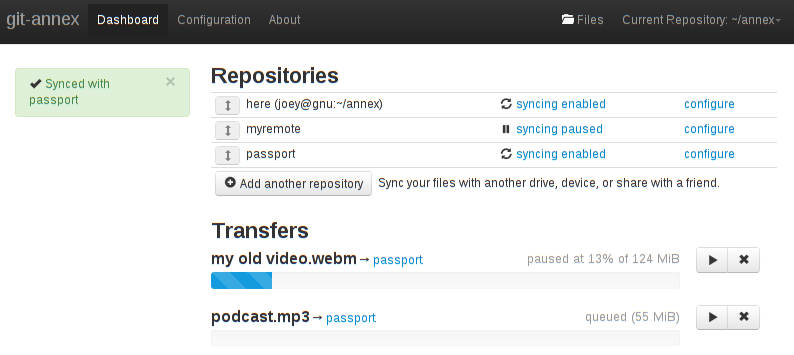
Rest of my time was spent on XMPP pairing UI. Using the same pages for both pairing with a friend and for self-pairing was confusing, so now the two options are split.
Now every time an XMPP git push is received or sent, it checks if there's a cloud repository configured, which is needed to send the contents of files. If not, it'll display this alert. Hopefully this will be enough to get users fully set up.

At this point I'm finally happy enough with the XMPP pairing + cloud repository setup process to film a screencast of it. As soon as I have some time & bandwidth someplace quiet. Expect one by the end of the month.
Fighting with javascript all day and racing to get a release out. Unstuck the OSX and Android autobuilders. Got drag and drop repository list reordering working great. Tons of changes in this release!
Also put up a new podcast.
Got the assistant to check again, just before starting a transfer, if the remote still wants the object. This should be all that's needed to handle the case where there is a transfer remote on the internet somewhere, and a locally paired client on the LAN. As long as the paired repository has a lower cost value, it will be sent any new file first, and if that is the only client, the file will not be sent to the transfer remote at all.
But.. locally paired repos did not have a lower cost set, at all. So I made their cost be set to 175 when they're created. Anyone who already did local pairing should make sure the Repositories list shows locally paired repositories above transfer remotes.
Which brought me to needing an easy way to reorder that list of remotes, which I plan to do by letting the user drag and drop remotes around, which will change their cost accordingly. Implementing that has two pain points:
Often a lot of remotes will have the same default cost value. So how to insert a remote in between two that have cost 100? This would be easy if git-annex didn't have these cost numbers, and instead just had an ordered list of remotes.. but it doesn't. Instead, dragging remotes in the list will sometimes need to change the costs of others, to make room to insert them in. It's BASIC renumbering all over again. So I wrote some code to do this with as little bother as possible.
Drag and drop means javascript. I got the basics going quickly with jquery-ui, only to get stuck for over an hour on some CSS issue that made lines from the list display all weird while being dragged. It is always something like this with javascript..
So I've got these 2 peices working, and even have the AJAX call firing, but it's not quite wired up just yet. Tomorrow.
Last night, revamped the web site, including making a videos page, which includes a new screencast introducing the git-annex assistant.
Worked on improving my Haskell development environment in vim.
hdevtools is an excellent but tricky thing to get working. Where before
it took around 30 seconds per compile for me to see type errors,
I now see them in under a second each time I save, and can also look up
types of any expression in the file. Since programming in Haskell is
mostly driven by reacting to type errors this should speed me up a lot,
although it's not perfect. Unfortunatly, I got really caught up in tuning
my setup, and only finished doing that at 5:48 am.
Disasterously late this morning, fixed the assistant's
~/.ssh/git-annex-shell wrapper so it will work when the ssh key does
not force a command to be run. Also made the webapp behave better
when it's told to create a git repository that already exists.
After entirely too little sleep, I found a puzzling bug where copying files to a local repo fails once the inode cache has been invalidated. This turned out to involve running a check in the state monad of the wrong repository. A failure mode I'd never encountered before.
Only thing I had brains left to do today was to record another screencast, which is rendering now...
Got renaming fully optimised in the assistent in direct mode. I even got it to work for whole directory renames. I can drag files around all day in the file manager and the assistant often finishes committing the rename before the file manager updates. So much better than checksumming every single renamed file! Also, this means the assistant makes just 1 commit when a whole directory is renamed.
Last night I added a feature to git annex status. It can now be asked to
only show the status of a single directory, rather than the whole annex.
All the regular file filtering switches work, so some neat commands
are possible. I like git annex status . --in foo --not --in bar to see
how much data is in one remote but not another.
This morning, an important thought about ?smarter flood filling, that will avoid unnecessary uploads to transfer remotes when all that's needed to get the file to its destination is a transfer over the LAN. I found an easy way to make that work, at least in simple cases. Hoping to implement it soon.
Less fun, direct mode turns out to be somewhat buggy when files with
duplicate content are in the repository. Nothing fails, but git annex
sync will re-checksum files each time it's run in this situation, and the
assistant will re-checksum files in certian cases. Need to work on this
soon too.
Trying to record screencasts demoing the assistant is really helping me see things that need to be fixed.
Got the version of the haskell TLS library in Debian fixed, backporting some changes to fix a botched security fix that made it reject all certificates. So WebDAV special remotes will work again on the next release.
Fixed some more problems around content being dropped when files are moved to archive directories, and gotten again when files are moved out.
Fixed some problems around USB drives. One was a real jaw-dropping bug: "git annex drop --from usbdrive" when the drive was not connected still updated the location log to indicate it did not have the file anymore! (Thank goodness for fsck..)
I've noticed that moving around files in direct mode repos is inneficient, because the assistant re-checksums the "new" file. One way to avoid that would be to have a lookup table from (inode, size, mtime) to key, but I don't have one, and would like to avoid adding one.
Instead, I have a cunning plan to deal with this heuristically. If the assistant can notice a file was removed and another file added at the same time, it can compare the (inode, size, mtime) to see if it's a rename, and avoid the checksum overhead.
The first step to getting there was to make the assistant better at batching together delete+add events into a single rename commit. I'm happy to say I've accomplished that, with no perceptable delay to commits.
And so we waited. Tick-tock, blink-blink, thirty seconds stretched themselves out one by one, a hole in human experience. -- The Bug
I think I've managed to fully track down the ?webapp hang. It is, apparently, a bug in the Warp web server's code intended to protect against the Slowloris attack. It assumes, incorrectly, that a web browser won't reuse a connection it's left idle for 30 seconds. Some bad error handling keeps a connection open with no thread to service it, leading to the hang. https://github.com/yesodweb/wai/issues/146
Have put a 30 minute timeout into place as a workaround, and, unless a web browser sits on an idle connection for a full 30 minutes and then tries to reuse it, this should be sufficient.
I was chasing that bug, quietly, for 6 months. Would see it now and then, but not be able to reproduce it or get anywhere with analysis. I had nearly given up. If you enjoy stories like that, read Ellen Ullman's excellent book The Bug.
To discover that between the blinks of the machine’s shuttered eye—going on without pause or cease; simulated, imagined, but still not caught—was life.
Fixed the last XMPP bug I know of. Turns out it was not specific to XMPP at all; the assistant could forget to sync with any repository on startup under certain conditions.
Also fixed bugs in git annex add and in the glob matching, and some more.
I've been working on some screencasts. More on them later.. But while doing them I found a perfect way to reliably reproduce the webapp hang that I've been chasing for half a year, and last saw at my presentation in Australia. Seems the old joke about bugs only reproducible during presentations is literally true here!
I have given this bug its ?own page at last, and have a tcpdump of it happening and everything. Am working on an hypotheses that it might be caused by Warp's slowloris attack prevention code being falsely triggered by the repeated hits the web browser makes as the webapp's display is updated.
More XMPP fixes. The most important change is that it now stores important messages, like push requests, and (re)sends them when a buddy's client sends XMPP presence. This makes XMPP syncing much more robust, all the clients do not need to already be connected when messages are initially sent, but can come and go. Also fixed a bug preventing syncing from working immediately after XMPP pairing. XMPP seems to be working well now; I only know of one minor bug.
Yesterday was all bug fixes, nothing to write about really.
Today I've been working on getting XMPP remotes to sync more reliably. I left some big holes when I stopped work on it in November:
- The assistant did not sync with XMPP remotes when it started up.
- .. Or when it detected a network reconnection.
- There was no way to trigger a full scan for transfers after receiving a push from an XMPP remote.
The asynchronous nature of git push over XMPP complicated doing this, but I've solved all 3 issues today.
Tracked down the bug that's been eluding me for days. It was indeed a race, and could result in a file being transferred into a direct mode repository and ending up in indirect mode. Was easy to fix once understood, just needed to update the direct mode mapping before starting the transfer.
While I was in there, I noticed another potential race, also in direct mode, where the watcher could decide to rewrite a symlink to fix its target, and at just the wrong time direct mode content could arrive in its place, and so get deleted. Fixed that too.
Seems likely there are some other direct mode races. I spent quite a while hammering on dealing with the indirect mode races with the assistant originally.
Next on my list is revisiting XMPP.
Verified that git push over XMPP works between multiple repositories that are sharing the same XMPP account. It does.
Seeing the XMPP setup process with fresh eyes, I found several places wording could be improved. Also, when the user goes in and configures (or reconfigures) an XMPP account, the next step is to do pairing, so it now redirects directly to there.
Next I need to make XMPP get back into sync after a network disconnection or when the assistant is restarted. This currently doesn't happen until a XMPP push is received due to a new change being made.
back burner: yesod-pure
Last night I made a yesod-pure branch, and did some exploratory conversion away from using Hamlet, of the Preferences page I built yesterday.
I was actually finding writing pure Blaze worked better than Hamlet, at first. Was able to refactor several things into functions that in Hamlet are duplicated over and over in my templates, and built some stuff that makes rendering type safe urls in pure Blaze not particularly ungainly. For example, this makes a submit button and a cancel button that redirects to another page:
buttons = toWidget $ \redir ->
"Save Preferences" <>|<> redir ConfigurationR []
The catch is how to deal with widgets that need to be nested inside other html. It's not possible to do this both cleanly and maximally efficiently, with Blaze. For max efficiency, all the html before the widget should be emitted, and then the widget run, and then all html after it be emitted. To use Blaze, it would have to instead generate the full html, then split it around the widget, and then emit the parts, which is less efficient, doesn't stream, etc.
I guess that's the core of what Hamlet does; it allows a clean representation and due to running TH at build time, can convert this into an efficient (but ugly) html emitter.
So, I may give up on this experiment. Or I may make the webapp less than maximally fast at generating html and go on with it. After all, these sorts of optimisations are mostly aimed at high-volume websites, not local webapps.
Stuck on a bug or two, I instead built a new Preferences page:
The main reason I wanted that was to allow enabling debug logging at runtime. But I've also wanted to expose annex.diskreserve and annex.numcopies settings to the webapp user. Might as well let them control whether it auto-starts too.
Had some difficulty deciding where to put this. It could be considered additional configuration for the local repository, and so go in the local repository edit form. However, this stuff can only be configured for local repositories, and not remotes, and that same form is used to edit remotes, which would lead to inconsistent UI and complicate the code. Also, it might grow to include things not tied to any repository, like choice of key/value backends. So, I put the preferences on their own page.
Also, based on some useful feedback from testing the assistant with a large number of files, I made the assistant disable git-gc auto packing in repositories it sets up. (Like fsck, git-gc always seems to run exactly when you are in a hurry.) Instead, it'll pack at most once a day, and with a rather higher threshold for the number of loose objects.
I got yesod-pure fully working on Android...
[[!img Error: "design/assistant/blog/day_201__real_Android_wrapup/fib.png" does not seem to be a valid png file]]
As expected, this involved manually splicing some template haskell. I'm now confident I can port the git-annex webapp to Android this way, and that it will take about a week. Probably will start on that in a month or so. If anyone has some spare Android hardware they'd like to loan me, possibly sooner. (Returning loaner Asus Transformer tomorrow; thanks Mark.) Although I'm inclined to let the situation develop; we may just get a ghc-android that supports TH..
Also:
- Fixed several bugs in the Android installation process.
- Committed patches for all Haskell libraries I've modified to the git-annex git repo.
- Ran the test suite on Android. It found a problem; seems
git cloneof a local repository is broken in the Android environment.
Non-Android:
- Made the assistant check every hour if logs have grown larger than a megabyte, and rotate them to avoid using too much disk space.
- Avoided noise in log about typechanged objects when running
git commit in direct mode repositories. Seems
git commithas no way to shut that up, so I had to /dev/null it. - When run with
--debug, the assistant now logs more information about why it transfers or drops objects. - Found and fixed a case where moving a file to an archive directory would not cause its content to be dropped.
- Working on a bug with the assistant where moving a file out of an archive directory in direct mode sometimes ends up with a symlink rather than a proper direct mode file. Have not gotten to the bottom of it entirely, but it's a race, and I think the race is between the direct mode mapping being updated, and the file being transferred.
Seems I am not done with the Android porting just yet after all. One more porting day..
Last night I managed to get all of Yesod to build for Android. I even successfully expanded some Template Haskell used in yesod-form. And am fairly confident I could manually expand all the TH in there, so it's actually useable without TH. Most of the TH is just commented out for now.
However, programs using Yesod didn't link; lots of missing symbols. I have been fighting to fix those all day today.
Finally, I managed to build the yesod-pure demo server,
and I have a working web server on Android! It listens for requests, it logs
them correctly, and it replies to requests. I did cripple yesod's routing
code in my hack-n-slash port of it, so it fails to display any pages,
but never has "Internal Server Error" in a web browser been such a sweet
sight.
At this point, I estimate about 1 or 2 weeks work to get to an Android webapp. I'd need to:
- More carefully port Yesod, manually expanding all Template Haskell as I went, rather than commenting it all out like I did this time.
- Either develop a tool to automatically expand Hamlet TH splices (preferred; seems doable), or convert all the webapp's templates to not use Hamlet.
I've modified 38 Haskell libraries so far to port them to Android. Mostly small hacks, but eep this is a lot of stuff to keep straight.
As well as making a new release, I rewrote most of the Makefile, so that it uses cabal to build git-annex. This avoids some duplication, and most importantly, means that the Makefile can auto-detect available libraries rather than needing to juggle build flags manually. Which was becoming a real pain.
I had avoided doing this before because cabal is slow for me on my little netbook. Adding ten seconds to every rebuild really does matter! But I came up with a hack to let me do incremental development builds without the cabal overhead, by intercepting and reusing the ghc command that cabal runs.
There was also cabal "fun" to get the Android build working with cabal.
And more fun involving building the test suite. For various reasons, I
decided to move the test suite into the git-annex binary. So you can run
git annex test at any time, any place, and it self-tests. That's a neat
trick I've seen one or two other programs do, and probably the nicest thing
to come out of what was otherwise a pretty yak shaving change that involved
babysitting builds all day.
An Android autobuilder is now set up to run nightly. At this point I don't see an immediate way to getting the webapp working on Android, so it's best to wait a month or two and see how things develop in Haskell land. So I'm moving on to other things.
Today:
- Fixed a nasty regression that made
*not match files in subdirectories. That broke the preferred content handling, among other things. I will be pushing out a new release soon. - As a last Android thing (for now), made the Android app automatically
run
git annex assistant --autostart, so you can manually set up an assistant-driven repository on Android, listing the repository in.config/git-annex/autostart - Made the webapp display any error message from
git initif it fails. This was the one remaining gap in the logging. One reason it could fail is if the system has a newer git in use, and~/.gitconfigis configured with some options the older git bundled with git-annex doesn't like. - Bumped the major version to 4, and annex.version will be set to 4 in new direct mode repositories. (But version 3 is otherwise still used, to avoid any upgrade pain.) This is to prevent old versions that don't understand direct mode from getting confused. I hope direct mode is finally complete, too, after the work to make it work on crippled filesystems this month.
- Misc other bugfixes etc. Backlog down to 43.
Wrote a C shim to get the Android app started. This avoids it relying on the Android /system/bin/sh to run its shell script, or indeed relying on any unix utilities from Android at all, which may help on some systems. Pushed a new build of the Android app.
Tracked down a failure a lot of people are reporting with WebDAV support to a backported security fix in the TLS library, and filed an upstream bug about it.
Various other misc fixing and stuff. My queue of bug reports and stuff only has 47 items in it now. Urk..
Set up an autobuilder for the linux standalone binaries. Did not get an Android autobuilder set up yet, but I did update the Android app with recent improvements, so upgrade.
Investigated further down paths to getting the webapp built for Android.
Since recent ghc versions support ghci and thus template haskell on arm, at least some of the time, I wonder what's keeping the ghc-android build from doing so? It might be due to it being a cross compiler. I tried recompiling it with the stage 2, native compiler enabled. While I was able to use that ghc binary on Android, it refused to run --interactive, claiming it was not built with that enabled. Don't really understand the ghc build system, so might have missed something.
Maybe I need to recompile ghc using the native ghc running on Android. But that would involve porting gcc and a lot of libraries and toolchain stuff to Android.
yesod-pure is an option, and I would not mind making all the code changes to use it, getting rid of template haskell entirely. (Probably around 1 thousand lines of code would need to be written, but most of it would be trivial conversion of hamlet templates.)
Question is, will yesod install at all without template haskell? Not easily.
vector,monad-logger,aeson,shakespeare,shakespeare-css,shakespeare-js,shakespeare-i18n,hamletall use TH at build time. Hacked them all to just remove the TH parts.The hack job on
yesod-corewas especially rough, involving things like 404 handlers. Did get it to build tho!Still a dozen packages before I can build yesod, and then will try building this yesod-pure demo.
So it seems the Android app works pretty well on a variety of systems. Only report of 100% failure so far is on Cyanogenmod 7.2 (Android 2.3.7).
Worked today on some of the obvious bugs.
- Turns out that getEnvironment is broken on Android, returning no
environment, which explains the weird git behavior where it complains
that it cannot determine the username and email (because it sees no USER
or HOST), and suggests setting them in the global git config (which it
ignores, because it sees no HOME). Put in a work around for this
that makes
git annex initmore pleasant, and opened a bug report on ghc-android. - Made the Android app detect when it's been upgraded, and re-link all the commands, etc.
- Fixed the bug that made
git-annex assistanton Android re-add all existing files on startup. - Enabled a few useful things in busybox. Including vi.
- Replaced the service notification icon with one with the git-annex logo.
- Made the terminal not close immediately when the shell exits, which should aid in debugging of certain types of crashes.
I want to set up an autobuilder for Android, but to do that I need to
install all the haskell libraries on my server. Since getting them built
for Android involved several days of hacking the first time, this will
be an opportunity to make sure I can replicate that. Hopefully in less time.
Well, it's built. Real Android app for git-annex.
When installed, this will open a terminal in which you have access to git-annex and all the git commands and busybox commands as well. No webapp yet, but command line users should feel right at home.
?terminal.png
{kind=link}
Please test it out, at least as far as installing it, opening the terminal,
and checking that you can run git annex; I've only been able to test on
one Android device so far. I'm especially keen to know if it works with
newer versions of Android than 4.0.3. (I know it only supports arm based
Android, no x86 etc.) Please comment if you tried it.
Building this went mostly as planned, although I had about 12 builds of the app in the middle which crashed on startup with no error message ora logs. Still, it took only one day to put it all together, and I even had time to gimp up a quick icon. (Better icons welcome.)
Kevin thinks that my space-saving hack won't work on all Androiden, and he
may be right. If the lib directory is on a different filesystem on some
devices, it will fail. But I used it for now anyhow. Thanks to the hack,
the 7.8 mb compressed .apk file installs to use around 23 mb of disk space.
Tomorrow: Why does git-annex assistant on Android re-add all existing
files on startup?
Today's work:
- Fixed
git annex addof a modified file in direct mode. - Fixed bugs in the inode sentinal file code added yesterday.
With some help from Kevin Boone, I now understand how KBOX works and how to use similar techniques to build my own standalone Android app that includes git-annex.
Kevin is using a cute hack; he ships a tarball and some other stuff as (pseudo-)library files (
libfoo.so), which are the only files the Android package manager deigns to install. Then the app runs one of these, which installs the programs.This avoids needing to write Java code that extracts the programs from one of its assets and writes it to an executable file, which is the canonical way to do this sort of thing. But I noticed it has a benefit too (which KBOX does not yet exploit). Since the pseudo-library file is installed with the X bit set, if it's really a program, such as busybox or git-annex, that program can be run without needing to copy it to an executable file. This can save a lot of disk space. So, I'm planning to include all the binaries needed by git-annex as these pseudo-libraries.
- Got the Android Terminal Emulator to build. I will be basing my first git-annex Android app on this, since a terminal is needed until there's a webapp.
- Wasted several hours fighting with
Android.mkfiles to include my pseudo shared library. This abuse of Makefiles by the NDK is what CDBS wants to grow up to be.. or is it the other way around? Anyway, it sucks horribly, and I finally found a way to do it without modifying the file at all. Ugh. - At this point, I can build a
git-annex.apkfile containing alibgit-annex.so, and alibbusybox.so, that can both be directly run. The plan from here is to give git-annex the ability to auto-install itself, and the other pseudo-libraries, when it's run aslibgit-annex.so.
Felt spread thin yesterday, as I was working on multiple things concurrently & bouncing around as compiles finished. Been working to get openssh to build for Android, which is quite a pain, starting with getting openssl to build and then dealing with the Cyanogenmod patches, some of which are necessary to build on Android and some of which break builds outside Cyanogenmod. At the same time was testing git-annex on Android. Found and fixed several more portability bugs while doing that. And on the back burner I was making some changes to the webapp..
(Forgot to commit my blog post yesterday too..)
Today, that all came together.
- When adding another local repository in the webapp, it now allows you to choose whether it should be combined with your current repository, or kept separate. Several people had requested a way to add local clones with the webapp, for various reasons, like wanting a backup repository, or wanting to make a repository on a NFS server, and this allows doing that.

More porting fun. FAT filesystems and other things used on Android can get all new inode numbers each time mounted. Made git-annex use a sentinal file to detect when this has happened, since in direct mode it compares inodes. (As a bonus this also makes copying direct mode repositories between filesystems work.)
Got openssh building for Android. Changed it to use $HOME/.ssh rather than trusting pwent.
Got git-annex's ssh connection caching working on Android. That needs a place where it can create a socket. When the repository is on a crippled filesystem, it instead puts the socket in a temporary directory set up on the filesystem where the git-annex program resides.
With ssh connection caching, transferring multiple files off my Android tablet screams! I was seeing 6.5 megabytes transferred per second, sustained over a whole month's worth of photos.
Next problem: git annex assistant on Android is for some reason crashing
with a segfault on startup. Especially odd since git annex watch works.
I'm so close to snap-photo-and-it-syncs-nirvana, but still so far away...
Pushed out a release yesterday mostly for a bug fix. I have to build git-annex 5 times now when releasing. Am wondering if I could get rid of the Linux 64 bit standalone build. The 32 bit build should run ok on 64 bit Linux systems, since it has all its own 32 bit libraries. What I really need to do is set up autobuilders for Linux and Android, like we have for OSX.
Today, dealt with all code that creates or looks at symlinks. Audited every bit of it, and converted all relevant parts to use a new abstraction layer that handles the pseudolink files git uses when core.symlinks=false. This is untested, but I'm quite happy with how it turned out.
Where next for Android? I want to spend a while testing command-line git-annex. After I'm sure it's really solid, I should try to get the webapp working, if possible.
I've heard rumors that Ubuntu's version of ghc somehow supports template haskell on arm, so I need to investigate that. If I am unable to get template haskell on arm, I would need to either wait for further developments, or try to expand yesod's template haskell to regular haskell and then build it on arm, or I could of course switch away from hamlet (using blaze-html instead is appealing in some ways) and use yesod in non-template-haskell mode entirely. One of these will work, for sure, only question is how much pain.
After getting the webapp working, there's still the issue of bundling it all up in an Android app that regular users can install.
Finished crippled filesystem support, except for symlink handling.
This was straightforward, just got lsof working in that mode, made
migrate copy key contents, and adapted the rsync special remote to
support it. Encrypted rsync special remotes have no more overhead on
crippled filesystems than normally. Un-encrypted rsync special remotes
have some added overhead, but less than encrypted remotes. Acceptable
for now.
I've now successfully run the assistant on a FAT filesystem.
Git handles symlinks on crippled filesystems by setting
core.symlinks=false and checking them out as files containing the link
text. So to finish up crippled filesystem support, git-annex needs to
do the same whenever it creates a symlink, and needs to read file contents
when it normally reads a symlink target.
There are rather a lot of calls to createSymbolicLink,
readSymbolicLink, getSymbolicLinkStatus, isSymbolicLink, and isSymLink
in the tree; only ones that are used in direct mode
need to be converted. This will take a while.
Checking whether something is a symlink, or where it points is especially tricky. How to tell if a small file in a git working tree is intended to be a symlink or not? Well, it can look at the content and see if it makes sense as a link text pointing at a git-annex key. As long as the possibility of false positives is ok. It might be possible, in some cases, to query git to verify if the object stored for that file is really a symlink, but that won't work if the file has been renamed, for example.
Converted some of the most commonly used symlink code to handle this.
Much more to do, but it basically works; I can git annex get and git
annex drop on FAT, and it works.
Unfortunately, got side-tracked when I discovered that the last release introduced a bug in direct mode. Due to the bug, "git annex get file; git annex drop file; git annex get file" would end up with the file being an indirect mode symlink to the content, rather than a direct mode file. No data loss, but not right. So, spent several hours fixing that reversion, which was caused by me stupidly fixing another bug at 5 am in the morning last week.. and I'll probably be pushing out another release tomorrow with the fix.
There are at least three problems with using git-annex
on /sdcard on Android, or on a FAT filesystem, or on (to a first
approximation) Windows:
- symlinks
- hard links
- unix permissions
So, I've added an annex.crippledfilesystem setting. git annex init now
probes to see if all three are supported, and if not, enables that, as well
as direct mode.
In crippled filesystem mode, all the permissions settings are skipped. Most of them are only used to lock down content in the annex in indirect mode anyway, so no great loss.
There are several uses of hard links, most of which can be dealt with by making copies. The one use of permissions and hard links I absolutely needed to deal with was that they're used to lock down a file as it's being ingested into the annex. That can't be done on crippled filesystems, so I made it instead check the metadata of the file before and after to detect if it changed, the same way direct mode detects when files are modified. This is likely better than the old method anyway.
The other reason files are hardlinked while they're being ingested is that this allows running lsof on a single directory of files that are in the process of being added, to detect if anything has them open for write. I still need to adjust the lsof check to work in crippled filesystem mode. It seems this won't make it much slower to run lsof on the whole repository.
At this point, I can use git-annex with a repository on /sdcard or a FAT
filesystem, and at least git annex add works.
Still several things on the TODO list before crippled filesystem mode is
complete. The only one I'm scared about is making git merge do something
sane when it wants to merge two trees full of symlinks, and the filesystem
doesn't let it create a symlink..
Ported all the utilities git-annex needs to run on Android: git, rsync, gnupg, dropbear (ssh client), busybox. Built a Makefile that can download, patch, and cross build these from source.
While all the utilities work, dropbear doesn't allow git-annex to use ssh connection caching, which is rather annoying especially since these systems tend to be rather slow and take a while to start up ssh connections. I'd sort of like to try to get openssh's client working on Android instead. Don't know how realistic that is.
Dealt with several parts of git-annex that assumed /bin/sh exists,
so it instead uses /system/bin/sh on Android. Also adapted runshell
for Android.
Now I have a 8 mb compressed tarball for Android. Uncompressed it's 25 mb. This includes a lot of git and busybox commands that won't be used, so it could be trimmed down further. 16 mb of it is git-annex itself.
Instructions for using the Android tarball
This is for users who are rather brave, not afraid of command line and
keyboard usage. Good first step.
I'm now successfully using git-annex at the command line on Android.
git annex watch works too.
For now, I'm using a git repository under /data, which is on a real,
non-cripped filesystem, so symlinks work there.
There's still the issue of running without any symlinks on /mnt/sdcard.
While direct mode gets most of the way, it still uses symlinks in a few
places, so some more work will be needed there. Also, git-annex uses hard
links to lock down files, which won't work on cripped filesystems.
Besides that, there's lots of minor porting, but no big show-stoppers currently.. Some of today's porting work:
Cross-compiled git for Android. While the Terminal IDE app has some git stuff, it's not complete and misses a lot of plumbing commands git-annex uses. My git build needs some tweaks to be relocatable without setting
GIT_EXEC_PATH, but it works.Switched git-annex to use the Haskell glob library, rather than PCRE. This avoids needing libpcre, which simplifies installation on several platforms (including Android).
Made git-annex's
configurehardcode some settings when cross-compiling for Android, rather than probing the build system.Android's built-in
lsofdoesn't support the -F option to use a machine-readable output format. So wrote a separate lsof output parser for the standard lsof output format. Unfortunatly, Android's lsof does not provide any information about where a file is open for read or write, so for safety, git-annex has to assume any file that's open might be written to, and avoid annexing it. It might be better to provide my own lsof eventually.
Thanks to hhm, who pointed me at KBOX, I have verified that I can build haskell programs that work on Android.
After hacking on it all day, I've succeeded in making an initial build of git-annex for Android. It links! It runs!
Which is not to say it's usable yet; for one thing I need to get a port of git before it can do anything useful. (Some of the other things git-annex needs, like ssh and sha256sum, are helpfully provided by KBOX.)
Next step will be to find or built a git port for Android. I know there's one in the "Terminal IDE" app. Once I can use git-annex at the command line on Android, I'll be able to test it out some (I can also port the test suite program and run it on Android), and get a feeling for what is needed to get the port to a usable command-line state.
And then on to the webapp, and an Android app, I suppose. So far, the port doesn't include the webapp, but does include the assistant. The webapp needs ghci/template haskell for arm. A few people have been reporting they have that working, but I don't yet.
Have been working on getting all the haskell libraries git-annex uses built with the android cross compiler. Difficulties so far are libraries that need tweaks to work with the new version of ghc, and some that use cabal in ways that break cross compilation. Haskell's network library was the last and most challenging of those.
At this point, I'm able to start trying to build git-annex for android. Here's the first try!
joey@gnu:~/src/git-annex>cabal install -w $HOME/.ghc-android-14-arm-linux-androideabi-4.7/bin/arm-unknown-linux-androideabi-ghc --with-ghc-pkg=$HOME/.ghc-android-14-arm-linux-androideabi-4.7/bin/arm-unknown-linux-androideabi-ghc-pkg --with-ld=$HOME/.ghc-android-14-arm-linux-androideabi-4.7/bin/arm-linux-androideabi-ld --flags="-Webapp -WebDAV -XMPP -S3 -Dbus"
Resolving dependencies...
Configuring git-annex-3.20130207...
Building git-annex-3.20130207...
Preprocessing executable 'git-annex' for git-annex-3.20130207...
on the commandline: Warning:
-package-conf is deprecated: Use -package-db instead
Utility/libdiskfree.c:28:26:
fatal error: sys/statvfs.h: No such file or directory
compilation terminated.
Should not be far from a first android build now..
While I already have Android "hello world" executables to try, I have not yet been able to run them. Can't seem to find a directory I can write to on the Asus Transformer, with a filesystem that supports the +x bit. Do you really have to root Android just to run simple binaries? I'm crying inside.
It seems that the blessed Android NDK way would involve making a Java app, that pulls in a shared library that contains the native code. For haskell, the library will need to contain a C shim that, probably, calls an entry point to the Haskell runtime system. Once running, it can use the FFI to communicate back to the Java side, probably. The good news is that CJ van den Berg, who already saved my bacon once by developing ghc-android, tells me he's hard at work on that very thing.
In the meantime, downloaded the Android SDK. Have gotten it to build a
.apk package from just javascript code, and managed to do it without
using eclipse (thank god). Will need this later, but for now want to wash
my brain out with soap after using it.
Have not tried to run my static binary on Android yet, but I'm already working on a plan B in case that doesn't work. Yesterday I stumbled upon https://github.com/neurocyte/ghc-android, a ghc cross-compiler for Android that uses the Android native development kit. It first appeared on February 4th. Good timing!
I've gotten it to build and it emits arm executables, that seem to use the Android linker. So that's very promising indeed.
I've also gotten cabal working with it, and have it chewing through installing git-annex's build dependencies.
Also made a release today, this is another release that's mostly bugfixes, and a few minor features. Including one bug fixed at 6 am this morning, urk.
I think I will probably split my days between working on Android porting and other git-annex development.
I need an Android development environment. I briefly looked into rooting the Asus Transformer so I could put a Debian chroot on it and build git-annex in there, but this quickly devolved to the typical maze of forum posts all containing poor instructions and dead links. Not worth it.
Instead, I'm doing builds on my Sheevaplug, and once I have a static armel binary, will see what I need to do to get it running on Android.
Fixed building with the webapp disabled, was broken by recent improvements. I'll be building without the webapp on arm initially, because ghci/template haskell on arm is still getting sorted out. (I tried ghc 7.6.2 and ghci is available, but doesn't quite work.)
From there, I got a binary built pretty quickly (well, it's arm, so not too
quickly). Then tried to make it static by appending
-optl-static -optl-pthread to the ghc command line.
This failed with a bunch of errors:
/usr/lib/gcc/arm-linux-gnueabi/4.6/../../../arm-linux-gnueabi/libxml2.a(nanohttp.o): In function `xmlNanoHTTPMethodRedir': (.text+0x2128): undefined reference to `inflateInit2_' /usr/lib/gcc/arm-linux-gnueabi/4.6/../../../arm-linux-gnueabi/libxml2.a(xzlib.o): In function `xz_decomp': (.text+0x36c): undefined reference to `lzma_code' ...
Disabling DBUS and (temporarily) XMPP got around that.
Result!
joey@leech:~/git-annex>ldd tmp/git-annex
not a dynamic executable
joey@leech:~/git-annex>ls -lha tmp/git-annex
-rwxr-xr-x 1 joey joey 18M Feb 6 16:23 tmp/git-annex*
Next: Copy binary to Android device, and watch it fail in some interesting way.
Repeat.
Also more bug triage this morning...
Got the pre-commit hook to update direct mode mappings.
Uses git diff-index HEAD to find out what's changed. The only
tricky part was detecting when HEAD doesn't exist yet. Git's
plumbing is deficient in this area. Anyway, the mappings get updated
much better now.
Fixed a wacky bug where git annex uninit behaved badly on a filesystem
that does not support hardlinks.
Got fairly far along in my triage of my backlog, looking through everything that happened after January 23rd. Still 39 or so items to look at.
There have been several reports of problems with ssh password prompts.
I'm beginning to think the assistant may need to prompt for the password
when setting up a ssh remote. This should be handled by ssh-askpass or
similar, but some Linux users probably don't have it installed, and there
seems to be no widely used OSX equivalent.
Fixed several bugs today, all involving (gasp) direct mode.
The tricky one involved renaming or deleting files in direct mode. Currently nothing removes the old filename from the direct mode mapping, and this could result in the renamed or deleted file unexpectedly being put back into the tree when content is downloaded.
To deal with this, it now assumes that direct mode mappings may be out of
date compared to the tree, and does additional checks to catch
inconsistencies. While that works well enough for the assistant,
I'd also like to make the pre-commit hook update the mappings for files
that are changed. That's needed to handle things like git mv.
Back from Australia. Either later today or tomorrow I'll dig into the messages I was not able to get to while traveling, and then the plan is to get into the Android port.
Video of my LCA2013 git-annex talk is now available. I have not watched it yet, hope it turned out ok despite some technical difficulties!
Not doing significant coding here at LCA2013, but stuff is still happening:
- I'll be giving a talk and demo of git-annex and the assistant tomorrow. Right after a keynote by Tim Berners-Lee! There's no streaming, but a recording will be available later.
- I've met numerous git-annex users and git-annex curious folk from down under.
- I had a suggestion that direct mode rename the
.gitdirectory to something else, to prevent foot-shooting git commands being used. A wrapper around git could be used to run git commands, and limit to safe ones. Under consideration. - I finally updated the OSX 10.8.2 build to last week's release. Been having some problems with the autobuilder, but it finally spat out a build. Hopefully this build is good, and it should fix the javascript issues with Safari and the webapp.
- Ulrik Sverdrup has written https://github.com/blake2-ppc/git-remote-gcrypt, which allows using gpg encrypted ssh remotes with git. The same idea could be expanded to other types of remotes, like S3. I'm excited about adding encrypted git remote support to the assistant!
Hacking on a bus to Canberra for LCA2013, I made the webapp's UI for pausing syncing to a repository also work for the local repository. This pauses the watcher thread. (There's also an annex.autocommit config setting for this.)
Ironically, this didn't turn out to the use the thread manager I built yesterday. I am not sure that a ThreadKilled exception would never be masked in the watcher thread. (There is some overly broad exception handling in git-annex that dates to back before I quite understood haskell exceptions.)
Got back to hacking today, and did something I've wanted to do for some time. Made all the assistant's threads be managed by a thread manager. This allows restarting threads if they crash, by clicking a button in the webapp. It also will allow for other features later, like stopping and starting the watcher thread, to pause the assistant adding local files.
I added the haskell async library as a dependency, which made this pretty easy to implement. The only hitch is that async's documentation is not clear about how it handles asyncronous exceptions. It took me quite a while to work out why the errors I'd inserted into threads to test were crashing the whole program rather than being caught!
15 hours in a plane with in-seat power. Ok, time for some new features!
Added two new repository groups.
"manual" can be used to avoid the assistant downloading any file contents
on its own. It'll still upload and otherwise sync data. To download files,
you can use git annex get while the assistant is running. You can also
drop files using the command line.
"source" is for repositories that are the source of new files, but don't need to retain a copy once the file has been moved to another repository. A camera would be a good example.
Ok, those were easy features to code; I suck at being productive on planes. Release coming up with those, once I find enough bandwidth here in AU.
On Friday, worked on several bugs in direct mode mapping code. Fixed it to not crash on invalid unicode in filenames. Dealt with some bugs when mappings were updated in subdirectories of the repository.
Those bugs could result in inconsistent mapping files, so today I
made fsck check mapping files for consistency.
Leaving for Australia tomorrow, but I also hope to get another bugfix release out before my flight leaves. Then will be on vacation for several days, more or less. Then at Linux Conf Australia, where there will be a git-annex presentation on February 1st.
BTW, I've lined up my Android development hardware for next month. I will be using an Asus Transformer, kindly lent to me by Mark H. This has the advantage of having a real keyboard, and running the (currently) second most widely used version of Android, 4.0.x. I have already experienced frustration getting photos off the thing and into my photo annex; the file manager is the worst I've seen since the 80's. I understand why so many want an Android port!
Interestingly, its main user filesystem is a FUSE mount point on /sdcard
backed by an ext4 filesystem on /data that a regular user is not allowed
to access. Whatever craziness this entails does not support symlinks.
When I wasn't dealing with the snowstorm today, I was fixing more bugs. Rather serious bugs.
One actually involved corruption to git-annex's location tracking info, due to a busted three-way merge. Takes an unusual set of circumstances for that bug to be triggered, which is why it was not noticed before now. Also, since git-annex is designed to not trust its location tracking info, and recover from it becoming inconsistent, someone could have experienced the bug and not really noticed it. Still it's a serious problem and I'm in debt to user a-or-b for developing a good test case that let me reproduce it and fix it. (Also added to the test suite.) ?This is how to make a perfect bug report
Another bug made git add; git commit cause data loss in direct mode.
I was able to make that not lose data, although it still does something
that's unlikely to be desired, unless the goal is to move a file from an
annexed direct mode file to having its entire contents stored in git.
Also found a bug with sync's automatic resolution of git conflicts. It
failed when two repositories both renamed a file to different names.
I had neglected to explicitly git rm the old file name, which is
necessary to resolve such a conflict.
Only one bug fix today, but it was a doozie. It seems that gpg2 has an incompatibility with the gpg 1.x that git-annex was written for, that causes large numbers of excess passphrase prompts, when it's supposed to be using a remote's symmetric encryption key. Adding the --batch parameter fixed this.
I also put together a page listing related software to git-annex.
I've also updated direct mode's documentation, about when it's safe to
use direct mode. The intuition I've developed about direct mode is that if
you don't need full versioning of files (with the ability to get back old
versions), direct mode is fine and safe to use. If you want full
versioning, it's best to not use direct mode. Or a reasonable compromise is
to git annex untrust the direct mode repository and set up a backup remote.
With this compromise, only if you edit a file twice in a row might the old
version get lost before it can be backed up.
Of course, it would be possible to make direct mode fully version preserving, but it'd have to back up every file in the repository locally to do so. Going back to two local copies of every file, which is part of git that git-annex happily avoids. Hmm, it might be possible to only back up a file locally until it reaches the backup remote..
I've noticed people have some problems getting me logs when there'a a bug, so I worked on improving the logging of the assistant.
While the assistant logged to .git/annex/daemon.log when started as a
daemon, when the webapp ran it didn't log there. It's somewhat tricky to
make the webapp redirect messages to the log, because it may start a web
browser that wants to write to the console. Took some file descriptor
juggling, but I made this work. Now the log is even used when the assistant
is started for the first time in a newly created repository. So, we have
total log coverage.
Next, I made a simple page in the webapp to display the accumulated logs.
It does not currently refresh as new things are logged. But it's easier
for me to tell users to click on Current Repository -> View log than
ask for them to look for the daemon.log file.
Finally, I made all the webapp's alerts also be written to the log.
Also did the requisite bug fixes.
Fixed a goodly amount of bugs today.
The most interesting change was that in direct mode, files using the same key are no longer hardlinked, as that could cause a surprising behavior if modifying one, where the other would also change.
Made a release, which is almost entirely bug fixes. Debian amd64 build
included this time.
I've finished making direct mode file transfers safe. The last piece of the
puzzle was making git-annex-shell recv-key check data it's received from
direct mode repositories. This is a bit expensive, but avoids adding
another round-trip to the protocol. I might revisit this later, this was
just a quick fix.
The poll was quite useful. Some interesting points:
- 14% have been reading this blog, and rightly don't trust direct mode to be safe. Which is why I went ahead with a quick fix to make it safe.
- 6% want an Ubuntu PPA. I don't anticipate doing this myself, but if anyone who develops for Ubuntu wants to put together a PPA with a newer version, I can help you pick the newer haskell packages you'll need from Debian, etc.
- 9% just need me to update the amd64 build in Debian sid. I forgot to include it in the last release, and the Debian buildds cannot currently autobuild git-annex due to some breakage in the versions of haskell libraries in unstable. Hopefully I'll remember to include an amd64 build in my next release.
And lots of other interesting stuff, I have a nice new TODO list now.
This month's theme is supposed to be fixing up whatever might prevent users from using the assistant. To that end, I've posted an open-ended poll, what is preventing me from using git-annex assistant. Please go fill it out so I can get an idea of how many people are using the assistant, and what needs to be done to get the rest of you, and your friends and family able to use it.
In the meantime, today I fixed several bugs that were recently reported in the webapp and assistant. Getting it working as widely as possible, even on strange IPv6 only systems, and with browsers that didn't like my generated javascript code is important, and fits right into this month's theme. I'm happy to see lots of bugs being filed, since it means more users are trying the assistant out.
Also continued work on making direct mode transfers safe. All transfers to local git remotes (wish I had a better phrase!) are now safe in direct mode. Only uploading from a direct mode repository over ssh to another git repository is still potentially unsafe.
Well underway on making direct mode transfers roll back when the file is modified while it's transferred.
As expected, it was easy to do for all the special remotes ... Except for bup, which does not allow deleting content. For bup it just removes the git ref for the bad content, and relies on bup's use of git delta compression to keep space use sane.
The problem is also handled by git-annex-shell sendkey.
But not yet for downloads from other git repositories. Bit stuck on that.
Also: A few minor bug fixes.
I was up at the crack of dawn wrestling 100 pound batteries around for 3 hours and rewiring most of my battery bank, so today is a partial day... but a day with power, which is always nice.
Did some design work on finally making transfers of files from direct mode repositories safe, even if a file is modified as it's being uploaded. This seems easily doable for special remotes; git to git repository transfers are harder, but I think I see how to do it without breaking backwards compatability.
(An unresolved problem is that a temp file would be left behind when a transfer failed due to a file being changed. What would really be nice to do is to use that temp file as the rsync basis when transferring the new version of a file. Although this really goes beyond direct mode, and into deltas territory.)
Made fsck work better in direct mode repositories. While it's expected for files to change at any time in direct mode, and so fsck cannot complain every time there's a checksum mismatch, it is possible for it to detect when a file does not seem to have changed, then check its checksum, and so detect disk corruption or other data problems.
Also dealt with several bug reports. One really weird one involves git
cat-file failing due to some kind of gpg signed data in the git-annex
branch. I don't understand that at all yet.
(Posted a day late.) [[!meta Error: cannot parse date/time: Mon Jan 7 16:05:13 JEST 2013]]
Got git annex add (and addurl) working in direct mode. This allowed me
to make git annex sync in direct mode no longer automatically add new
files.
It's also now safe to mix direct mode annexed files with regular files in
git, in the same repository. Might have been safe all along, but I've
tested it, and it certainly works now. You just have to be careful to not
use git commit -a to commit changes to such files, since that'll also
stage the entire content of direct mode files.
Made a minor release for these recent changes and bugfixes. Recommended if you're using direct mode. Had to chase down a stupid typo I made yesterday that caused fsck to infinite loop if it found a corrupted file. Thank goodness for test suites.
Several bugfixes from user feedback today.
Made the assistant detect misconfigured systems where git will fail to commit because it cannot determine the user's name or email address, and dummy up enough info to get git working. It makes sense for git and git-annex to fail at the command line on such a misconfigured system, so the user can fix it, but for the assistant it makes sense to plow on and just work.
I found a big gap in direct mode -- all the special remotes expected to find content in the indirect mode location when transferring to the remote. It was easy to fix once I noticed the problem. This is a big enough bug that I will be making a new release in a day or so.
Also, got fsck working in direct mode. It doesn't check as many things as in indirect mode, because direct mode files can be modified at any time. Still, it's usable, and useful.
There was a typo in cabal file that broke building the assistant on OSX. This didn't affect the autobuilds of the app, but several users building by hand reported problems. I made a new minor release fixing that typo, and also a resouce leak bug.
Got a restart UI working after all. It's a hack though. It opens a new tab for the new assistant instance, and as most web browsers don't allow javascript to close tabs, the old tab is left open. At some point I need to add a proper thread manager to the assistant, which the restart code could use to kill the watcher and committer threads, and then I could do a clean restart, bringing up the new daemon and redirecting the browser to it.
Found a bug in the assistant in direct mode -- the expensive transfer scan
didn't queue uploads needed to sync to other repos in direct mode, although
it did queue downloads. Fixing this laid some very useful groundwork for
making more commands support direct mode, too. Got stuck for a long time
dealing with some very strange git-cat-file behavior while making this
work. Ended up putting in a workaround.
After that, I found that these commands work in direct mode, without needing any futher changes!
git annex findgit annex whereisgit annex copygit annex movegit annex dropgit annex log
Enjoy! The only commands I'd like to add to this are fsck, add,
and addurl...
Installed a generator, so I'll have more power and less hibernation.
Added UI in the webapp to shut down the daemon. Would like to also have restart UI, but that's rather harder to do, seems it'd need to start another copy of the webapp (and so, of the assistant), and redirect the browser to its new url. ... But running two assistants in the same repo at the same time isn't good. Anyway, users can now use the UI to shut it down, and then use their native desktop UI to start it back up.
Spiffed up the control menu. Had to stop listing other local repositories in the menu, because there was no way to notice when a new one was added (without checking a file on every page load, which is way overkill for this minor feature). Instead added a new page that lists local repositories it can switch to.
Released the first git-annex with direct mode today. Notably, the assistant enables direct mode in repositories it creates. All builds are updated to 3.20130102 now.
My plan for this month is to fix whatever things currently might be preventing you from using the git-annex assistant. So bugfixes and whatever other important gaps need to be filled, but no major new feature developments.
A few final bits and pieces of direct mode. Fixed a few more bugs in the assistant. Made all git-annex commands that don't work at all, or only partially work in direct mode, refuse to run at all. Also, some optimisations.
I'll surely need to revisit direct mode later and make more commands
support it; fsck and add especially.
But the only thing I'd like to deal with before I make a release with direct
mode is the problem of files being able to be modified while they're
being transferred, which can result in data loss.
Short day today, but I spent it all on testing the new FSEvents code, getting it working with the assistant in direct mode. This included fixing its handling of renaming, and various other bugs.
The assistant in direct mode now seems to work well on OSX. So I made the assistant default to making direct mode repositories on OSX.
That'll presumably flush out any bugs. More importantly,
it let me close several OSX-specific bugs to do with interactions between
git-annex's symlinks and OSX programs that were apparently written under the
misprehension that it's a user-mode program's job to manually follow symlinks.
Of course, defaulting to direct mode also means users can just modify files as they like and the assistant will commit and sync the changed files. I'm waiting to see if direct mode becomes popular enough to make it the default on all OS's.
Investigated using the OSX fsevents API to detect when files are modified, so they can be committed when using direct mode. There's a haskell library and even a sample directory watching program. Initial tests look good...
Using fsevents will avoid kqueue's problems with needing enough file descriptors to open every subdirectory. kqueue is a rather poor match for git-annex's needs, really. It does not seem to provide events for file modifications at all, unless every file is individually opened. While I dislike leaving the BSD's out, they need a better interface to be perfectly supported by git-annex, and kqueue will still work for indirect mode repositories.
Got the assistant to use fsevents. It seems to work well!
The only problem I know of is that it doesn't yet handle whole directory renames. That should be easy to fix later.
Over Christmas, I'm working on making the assistant support direct mode. I like to have a fairly detailed plan before starting this kind of job, but in this case, I don't. (Also I have a cold so planning? Meh.) This is a process of seeing what's broken in direct mode and fixing it. I don't know if it'll be easy or hard. Let's find out..
First, got direct mode adding of new files working. This was not hard, all the pieces I needed were there. For now, it uses the same method as in indirect mode to make sure nothing can modify the file while it's being added.
An unexpected problem is that in its startup scan, the assistant runs
git add --updateto detect and stage any deletions that happened while it was not running. But in direct mode that also stages the full file contents, so can't be used. Had to switch to using git plumbing to only stage deleted files. Happily this also led to fixing a bug; deletions were not always committed at startup when using the old method; with the new method it can tell when there are deletions and trigger a commit.Next, got it to commit when direct mode files are modified. The Watcher thread gets a inotify event when this happens, so that was easy. (Although in doing that I had to disable a guard in direct mode that made annexed files co-exist with regular in-git files, so such mixed repositories probably won't work in direct mode yet.)
However, naughty kqueue is another story, there are no kqueue events for file modifications. So this won't work on OSX or the BSDs yet. I tried setting some more kqueue flags in hope that one would make such events appear, but no luck. Seems I will need to find some other method to detect file modifications, possibly an OSX-specific API.
Another unexpected problem: When an assistant receives new files from one of its remotes, in direct mode it still sets up symlinks to the content. This was because the Merger thread didn't use the
synccommand's direct mode aware merge code.. so fixed that.Finally there was some direct mode bookeeping the assistant has to get right. For example, when a file is modified, the old object has to be looked up, and be marked as not locally present any longer. That lookup relies on the already running
git cat-file --batch, so it's not as fast as it could be, if I kept a local cache of the mapping between files and objects. But it seems fast enough for now.
At this point the assistant seems to work in direct mode on Linux! Needs more testing..
Finished getting automatic merge conflict resolution working in direct mode. Turned out I was almost there yesterday, just a bug in a filename comparison needed to be fixed.
Fixed a bug where the assistant dropped a file after transferring it, despite the preferred content settings saying it should keep its copy of the file. This turned out to be due to it reading the transfer info incorrectly, and adding a "\n" to the end of the filename, which caused the preferred content check to think it wasn't wanted after all. (Probably because it thought 0 copies of the file were wanted, but I didn't look into this in detail.)
Worked on my test suite, particularly more QuickCheck tests. I need to use QuickCheck more, particularly when I've pairs of functions, like encode and decode, that make for easy QuickCheck properties.
Got merging working in direct mode!
Basically works as outlined yesterday, although slightly less clumsily.
Since there was already code that ran git diff-tree to update the
associated files mappings after a merge, I was able to adapt that same code
to also update the working tree.
An important invariant for direct mode merges is that they should never
cause annexed objects to be dropped. So if a file is deleted by a merge,
and was a direct mode file that was the only place in the working copy
where an object was stored, the object is moved into .git/annex/objects.
This avoids data loss and any need to re-transfer objects after a merge.
It also makes renames and other move complex tree manipulations always end
up with direct mode files, when their content was present.
Automatic merge conflict resoltion doesn't quite work right yet in direct mode.
Direct mode has landed in the master branch, but I still consider it
experimental, and of course the assistant still needs to be updated to
support it.
As winter clouds set in, I have to ration my solar power and have been less active than usual.
It seems that the OSX 10.8.2 git init hanging issue has indeed been
resolved, by building the app on 10.8.2. Very good news! Autobuilder setup is
in progress.
Finally getting stuck in to direct mode git-merge handling. It's
not possible to run git merge in a direct mode tree, because it'll
see typechanged files and refuse to do anything.
So the only way to use git merge, rather than writing my own merge engine,
is to use --work-tree to make it operate in a temporary work tree directory
rather than the real one.
When it's run this way, any new, modified, or renamed files will be added
to the temp dir, and will need to be moved to the real work tree.
To detect deleted files, need to use git ls-files --others, and
look at the old tree to see if the listed files were in it.
When a merge conflict occurs, the new version of the file will be in the temp directory, and the old one in the work tree. The normal automatic merge conflict resolution machinery should work, with just some tweaks to handle direct mode.
Fixed a bug in the kqueue code that made the assistant not notice when a
file was renamed into a subdirectory. This turned out to be because the
symlink got broken, and it was using stat on the file. Switching to
lstat fixed that.
Improved installation of programs into standalone bundles. Now it uses the programs detected by configure, rather than a separate hardcoded list. Also improved handling of lsof, which is not always in PATH.
Made a OSX 10.8.2 build of the app, which is nearly my last gasp attempt
at finding a way around this crazy git init spinning problem with Jimmy's
daily builds are used with newer OSX versions. Try it here:
http://downloads.kitenet.net/tmp/git-annex.dmg.bz2
Mailed out the Kickstarter T-shirt rewards today, to people in the US. Have to fill out a bunch of forms before I can mail the non-US ones.
Built git annex direct and git annex indirect to toggle back and forth
between direct mode. Made git annex status show if the repository is in
direct mode. Now only merging is needed for direct mode to be basically
usable.
I can do a little demo now. Pay attention to the "@" ls shows at the end of symlinks.
joey@gnu:~/tmp/bench/rdirect>ls
myfile@ otherfile@
joey@gnu:~/tmp/bench/rdirect>git annex find
otherfile
# So, two files, only one present in this repo.
joey@gnu:~/tmp/bench/rdirect>git annex direct
commit
# On branch master
# Your branch is ahead of 'origin/master' by 7 commits.
#
nothing to commit (working directory clean)
ok
direct myfile ok
direct otherfile ok
direct ok
joey@gnu:~/tmp/bench/rdirect>ls
myfile@ otherfile
# myfile is still a broken symlink because we don't have its content
joey@gnu:~/tmp/bench/rdirect>git annex get myfile
get myfile (from origin...) ok
(Recording state in git...)
joey@gnu:~/tmp/bench/rdirect>ls
myfile otherfile
joey@gnu:~/tmp/bench/rdirect>echo "look mom, no symlinks" >> myfile
joey@gnu:~/tmp/bench/rdirect>git annex sync
add myfile (checksum...) ok
commit
(Recording state in git...)
[master 0e8de9b] git-annex automatic sync
...
ok
joey@gnu:~/tmp/bench/rdirect>git annex indirect
commit ok
indirect myfile ok
indirect otherfile ok
indirect ok
joey@gnu:~/tmp/bench/rdirect>ls
myfile@ otherfile@
I'd like git annex direct to set the repository to untrusted, but
I didn't do it. Partly because having git annex indirect set it back to
semitrusted seems possibly wrong -- the user might not trust a repo even in
indirect mode. Or might fully trust it. The docs will encourage users to
set direct mode repos to untrusted -- in direct mode you're operating
without large swathes of git-annex's carefully constructed safety net.
(When the assistant later uses direct mode, it'll untrust the repository
automatically.)
Made git annex sync update the file mappings in direct mode.
To do this efficiently, it uses git diff-tree to find files that are
changed by the sync, and only updates those mappings. I'm rather happy
with this, as a first step to fully supporting sync in direct mode.
Finished the overhaul of the OSX app's library handling. It seems to work well, and will fix a whole class of ways the OSX app could break.
Fixed a bug in the preferred content settings for backup repositories, introduced by some changes I made to preferred content handling 4 days ago.
Fixed the Debian package to build with WebDAV support, which I forgot to turn on before.
Planning a release tomorrow.
Got object sending working in direct mode. However, I don't yet have a reliable way to deal with files being modified while they're being transferred. I have code that detects it on the sending side, but the receiver is still free to move the wrong content into its annex, and record that it has the content. So that's not acceptable, and I'll need to work on it some more. However, at this point I can use a direct mode repository as a remote and transfer files from and to it.
Automated updating of the cached mtime, etc data. Next I need to automate
generation of the key to filename mapping files. I'm thinking that I'll make
git annex sync do it. Then, once I get committing and
merging working in direct mode repositories (which is likely to be a
good week's worth of work), the workflow for using these repositories
will be something like this:
git config annex.direct true
git annex sync # pulls any changes, merges, updates maps and caches
git annex get
# modify files
git annex sync # commits and pushes changes
And once I get direct mode repositories working to this degree at the command line, I can get on with adding support to the assistant.
Also did some more work today on the OSX app. Am in the middle of getting it to modify the binaries in the app to change the paths to the libraries they depend on. This will avoid the hacky environment variable it is currently using, and make runshell a much more usable environment. It's the right way to do it. (I can't believe I just said RPATH was the right way to do anything.)
In the middle of this, I discovered http://hackage.haskell.org/package/cabal-macosx, which does the same type of thing.
Anyway, I have to do some crazy hacks to work around short library name fields in executables that I don't want to have to be specially rebuilt in order to build the webapp. Like git.
Started laying the groundwork for desymlink's direct mode. I got rather far!
A git repo can be configured with annex.direct and all actions that
transfer objects to it will replace the symlinks with regular files.
Removing objects also works (and puts back a broken symlink),
as does checking if an object is present, which even detects if a file
has been modified.
So far, this works best when such a direct mode repository is used as a git remote of another repository. It is also possible to run a few git-annex commands, like "get" in a direct mode repository, though others, like "drop" won't work because they rely on the symlink to map back to the key.
Direct mode relies on map files existing for each key in the repository, that tell what file(s) use it. It also relies on cache files, that contain the last known mtime, size, and inode of the file. So far, I've been setting these files up by hand.
The main thing that's missing is support for transferring objects from direct mode repositories. There's no single place I can modify to support that (like I could for the stuff mentioned above), and also it's difficult to do safely, since files could be modified at any time.
So it'll need to quarantine files, to prevent a modified version from
getting sent out. I could either do this by copying the file, or by
temporarily git annex locking it. Unsure which choice would be less
annoying..
Also did some investigation with Jimmy of the OSX app git-config hang. Seems to be some kind of imcompatability between the 10.7 autobuilder and 10.8. Next step is probably to try to build on 10.8. Might also be worth trying http://macdylibbundler.sourceforge.net/, although my own scripts do more or less the same thing to build the app.
Biding my time while desymlink gells in my head..
Fixed a bug in the assistant's local pairing that rejected ssh keys with a period in the comment.
Fixed a bug in the assistant that made it try to drop content from remotes that didn't have it, and avoided a drop failure crashing a whole assistant thread.
Made --auto behave better when preferred content is set.
Looked into making the transfer queue allow running multiple transfers at the same time, ie, one per remote. This seems to essentially mean splitting the queue into per remote queues. There are some complexities, and I decided not to dive into working through it right now, since it'd be a distraction from thinking about desymlink. Will revisit it later.
Allow specifying a port when setting up a ssh remote.
While doing that, noticed that the assistant fails to transfer files to sync to a ssh remote that was just added. That got broken while optimising reconnecting with a remote; fixed it.
One problem with the current configurators for remotes is they have a lot of notes and text to read at the top. I've worked on cut that down somewhat, mostly by adding links and help buttons next to fields in the form.
I also made each form have a check box controlling whether encryption is enabled. Mostly as a way to declutter the text at the top, which always had to say encryption is enabled.
I have a fairly well worked out design for desymlink. Will wait a few days to work on it to let it jell.
Made the webapp show runtime errors on a prettified page that includes version info, a bug reporting link, etc.
Dealt with a bad interaction between required fields and the bootstrap modals displayed when submitting some configuration forms. This was long, complex, and had lots of blind alleys. In the end, I had to derive new password and text fields in yesod that don't set the required attribute in the generated html.
Yesterday, I woke up and realized I didn't know what I needed to work on in git-annex. Added a poll, Android to help me decide what major thing to work on next.
More flailing at the OSX monster. (A species of gelatinous cube?) Current fun seems to involve git processes spinning if git-annex was started without a controlling TTY. I'm befuddled by this.
Made the S3 and Glacier configurators have a list of regions, rather than requiring a the region's code be entered correctly. I could not find a list of regions, or better, an API to get a list, so I'll have to keep updating as Amazon adds services in new regions.
Spent some time trying to get WebDAV to work with livedrive.com. It doesn't like empty PROPPATCH. I've developed a change to the haskell DAV library that will let me avoid this problem.
Just filling in a few remaining bits and pieces from this month's work.
- Made the assistant periodically check glacier-cli for archives that are ready, and queue downloads of them.
- The box.com configurator defaults to embedding the account info, allowing one-click enabling of the repository. There's a check box to control this.
- Fix some bugs with how the standalone images run git-annex.
- Included ssh in the standalone images.
- Various other bug fies.
I had planned to do nothing today; I can't remember the last time I did that. Twas not to be; instead I had to make a new release to fix a utterly stupid typo in the rsync special remote. I'm also seeing some slightly encouraging signs of the OSX app being closer to working and this release has a further fix toward that end; unsetting all the environment variables before running the system's web browser.
New release today, the main improvements in this one being WebDAV, Box.com, and Amazon glacier support.
Collected together all the OSX problem reports into one place at ?OSX, to make it easier to get an overview of them.
Did some testing of the OSX standalone app and found that it was missing
some libraries. It seems some new libraries it's using themselves depend on
other libraries, and otool -L doesn't recursively resolve this.
So I converted the simplistic shell script it was using to install libraries into a haskell progream that recursively adds libraries until there are no more to add. It's pulling in quite a lot more libraries now. This may fix some of the problems that have been reported with the standalone app; I don't really know since I can only do very limited testing on OSX.
Still working on getting the standalone builds for this release done, should be done by the end of today.
Also found a real stinker of a bug in dirContentsRecursive, which was
just completely broken, apparently since day 1. Fixing that has certainly
fixed buggy behavior of git annex import. It seems that the other
user of it, the transfer log code, luckily avoided the deep directory
trees that triggered the bug.
Got progress bars working for glacier. This needed some glacier-cli changes, which Robie helpfully made earlier.
Spent some hours getting caught up and responding to bug reports, etc.
Spent a while trying to make git-annex commands that fail to find any matching files to act on print a useful warning message, rather than the current nothing. Concluded this will be surprisingly hard to do, due to the multiple seek passes some commands perform. Update: Thought of a non-invasive and not too ugly way to do this while on my evening walk, and this wart is gone.
Added a configurator for Glacier repositories to the webapp. That was the last cloud repository configurator that was listed in the webapp and wasn't done. Indeed, just two more repository configurators remain to be filled in: phone and NAS.
By default, Glacier repositories are put in a new "small archive" group. This makes only files placed in "archive" directories be sent to Glacier (as well as being dropped from clients), unlike the full archive group which archives all files. Of course you can change this setting, but avoiding syncing all data to Glacier seemed like a good default, especially since some are still worried about Glacier's pricing model.
Fixed several bugs in the handling of archive directories, and the webapp makes a toplevel archive directory when an archive remote is created, so the user can get on with using it.
Made the assistant able to drop local files immediately after transferring them to glacier, despite not being able to trust glacier's inventory. This was accomplished by making the transferrer, after a successful upload, indicate that it trusts the remote it just uploaded to has the file, when it checks if the file should be dropped.
Only thing left to do for glacier is to make the assistant retry failed downloads from it after 4 hours, or better, as soon as they become available.
Got Amazon Glacier working as a full-fledged special remote.
(Well, I think it works... Since it takes 4 hours to get data out, which is longer than the time it took me to sign up for Glacier and write the special remote ... I've yet to fully test it!)
Thanks to Robie Basak for writing glacier-cli, and developing the intial hook remote support. Also thanks to Peter Todd for pointing out that Glacier cannot store empty files, which had to be worked around in the special remote.
Of course the 4 hour delay on retreval makes Glacier interesting. For now, you have to run "git annex get" twice, once to queue the retrieval, and a second time in 4 hours to get the file(s). There is a helpful example in using Amazon Glacier.
The real complication though, is that Glacier's inventories take a long
time to get, and can be out of date. So glacier-cli caches inventory info.
I didn't feel comfortable making git-annex trust that information,
so it'll refuse to trust that Glacier has a copy of a file when dropping
it. There's a --trust-glacier switch to override this default paranoid
behavior when dropping files.
Tomorrow ... er, tomorrow is Thanksgiving trip start.
Next weekend: Webapp configurator for glacier, and maybe something to get the assistant to detect when jobs are complete and finish retrievals from Glacier, automatically.
Changed how the directory and webdav special remotes store content. The new method uses less system calls, is more robust, and leaves any partially transferred key content in a single tmp directory, which will make it easier to clean that out later.
Also found & fixed a cute bug in the directory special remote when the chunksize is set to a smaller value than the ByteString chunk size, that caused it to loop forever creating empty files.
Added an embedcreds=yes option when setting up special remotes. Will put UI for it into the webapp later, but rather than work on that tomorrow, I plan to work on glacier.
Unexpectedly today, I got progress displays working for uploads via WebDAV.
The roadblock had been that the interface of for uploading to S3 and WebDAV
is something like ByteString -> IO a. Which doesn't provide any hook to
update a progress display as the ByteString is consumed.
My solution to this was to create a hGetContentsObserved, that's similar
to hGetContents, but after reading each 64kb chunk of data from the
Handle to populate the ByteString, it runs some observing action. So when
the ByteString is streamed, as each chunk is consumed, the observer
runs. I was able to get this to run in constant space, despite not having
access to some of the ByteString internals that hGetContents is built
with.
So, a little scary, but nice. I am curious if there's not a better way to solve this problem hidden in a library somewhere. Perhaps it's another thing that conduit solves somehow? Because if there's not, my solution probably deserves to be put into a library. Any Haskell folk know?
Used above to do progress displays for uploads to S3. Also did progress display to console on download from S3. Now very close to being done with progressbars. Finally. Only bup and hook remotes need progress work.
Reworked the core crypto interface, to better support streaming data through gpg. This allowed fixing both the directory and webdav special remotes to not buffer whole files in memory when retrieving them as chunks from the remote.
Spent some time dealing with API changes in Yesod and Conduit. Some of them annoyingly gratuitous.
I needed an easy day, and I got one. Configurator in the webapp for Box.com came together really quickly and easily, and worked on the first try.
Also filed a bug on the Haskell library that is failing on portknox.com's SSL certificate. That site is the only OwnCloud provider currently offering free WebDAV storage. Will hold off on adding OwnCloud to the webapp's cloud provider lists until that's fixed.
Worked on webdav special remotes all day.
- Got encryption working,
after fixing an amusing typo that made
initremotefor webdav throw away the encryption configuration and store files unencrypted. - Factored out parts of the directory special remote that had to do with file chunking, and am using that for webdav. This refactoring was painful.
At this point, I feel the webdav special remote works better than the old davfs2 + directory special remote hack. While webdav doesn't yet have progress info for uploads, that info was pretty busted anyway with davfs2 due to how it buffers files. So ... I've merged webdav into master!
Tomorrow, webapp configurators for Box.com and any other webdav supporting sites I can turn up and get to work..
A while ago I made git-annex not store login credentials in git for special remotes, when it's only encrypting them with a shared cipher. The rationalle was that you don't want to give everyone who gets ahold of your git repo (which includes the encryption key) access to your passwords, Amazon S3 account, or whatever. I'm now considering adding a checkbox (or command-line flag) that allows storing the login credentials in git, if the user wants to. While using public key crypto is the real solution (and is fully supported by git-annex (but not yet configurable in the webapp)), this seems like a reasonable thing to do in some circumstances, like when you have a Box.com account you really do want to share with the people who use the git repo.
Two releases of the Haskell DAV library today. First release had my changes from yesterday. Then I realized I'd also need support for making WebDAV "collections" (subdirectories), and sent Clint a patch for that too, as well as a patch for querying DAV properties, and that was 0.2. Got it into Debian unstable as well. Should have everything I'll need now.
The webdav special remote is now working! Still todo: Encryption support, progress bars, large file chunking, and webapp configurators. But already, it's a lot nicer than the old approach of using davfs2, which was really flakey and slow with large data volumes.
I did notice, though, that uploading a 100 mb file made the process use 100 mb of memory. This is a problem I've struggled with earlier with S3, the Haskell http libraries are prevented from streaming data by several parts of the protocol that cause the data to be accessed more than once. I guess this won't be a problem for DAV though, since it'll probably be chunking files anyway.
Mailed out all my Kickstarter USB key rewards, and ordered the T-shirts too.
Read up on WebDAV, and got the haskell library working. Several hours were wasted by stumbling over a bug in the library, that requires a carefully crafted XML document to prevent. Such a pity about things like DAV (and XMPP) being designed back when people were gung-ho about XML.. but we're stuck with them now.
Now I'm able to send and receive files to box.com using the library. Trying to use an OwnCloud server, though, I get a most strange error message, which looks to be coming from deep in the HTTPS library stack: "invalid IV length"
The haskell DAV library didn't have a way to delete files. I've added one and sent off a patch.
Roughed in a skeleton of a webdav special remote. Doesn't do anything yet. Will soon.
Factored out a Creds module from parts of the S3 special remote and XMPP support, that all has to do with credentials storage. Using this for webdav creds storage too.
Will also need to factor out the code that's currently in the directory special remote, for chunking of files.
PS: WebDAV, for all its monstrously complicated feature set, lacks one obvious feature: The ability to check how much free space is available to store files. Eyeroll.
Dealt with post-release feedback deluge. There are a couple weird bugs that I don't understand yet. OSX app is still not working everywhere.
Got the list of repositories in the webapp to update automatically when repositories are added, including when syncing with a remote causes repositories to be discovered.
I need a plan for the rest of the month. It feels right to focus on more cloud storage support. Particularly because all the cloud providers supported so far are ones that, while often being best of breed, also cost money. To finish up the cloud story, need support for some free ones.
Looking at the results of the prioritizing special remotes poll, I suspect that free storage is a large part of why Google Drive got so many votes. Soo, since there is not yet a Haskell library for Google Drive, rather than spending a large chunk of time writing one, I hope to use a Haskell WebDAV library that my friend Clint recently wrote. A generic WebDAV special remote in git-annex will provide much better support for box.com (which has 5 to 50 gb free storage), as well as all the OwnCloud providers, at least one of which provides 5 gb free storage.
If I have time left this month after doing that, I'd be inclined to do Amazon Glacier. People have already gotten that working with git-annex, but a proper special remote should be better/easier, and will allow integrating support for it into the assistant, which should help deal with its long retrieval delays. And since, if you have a lot of data archived in Glacier, you will only want to pull out a few files at a time, this is another place besides mobile phones where a partial content retrieval UI is needed. Which is on the roadmap to be worked on next month-ish. Synergy, here I come. I hope.
Cut a new release today. It's been nearly a month since the last one, and a large number of improvements.. Be sure to read the release notes if upgrading. All the standalone builds are updated already.
I hope I'm nearly at the end of this XMPP stuff after today. Planning a new release tomorrow.
Split up the local pairing and XMPP pairing UIs, and wrote a share with a friend walkthrough.
Got the XMPP push code to time out if expected data doesn't arrive within 2 minutes, rather than potentially blocking other XMPP push forever if the other end went away.
I pulled in the Haskell async library for this, which is yes, yet another library, but one that's now in the haskell platform. It's worth it, because of how nicely it let me implement IO actions that time out.
runTimeout :: Seconds -> IO a -> IO (Either SomeException a)
runTimeout secs a = do
runner <- async a
controller <- async $ do
threadDelaySeconds secs
cancel runner
cancel controller `after` waitCatch runner
This would have been 20-50 lines of gnarly code without async, and I'm sure I'll find more uses for async in the future.
Discovered that the XMPP push code could deadlock, if both clients started a push to the other at the same time. I decided to fix this by allowing each client to run both one push and one receive-pack over XMPP at the same time.
Prevented the transfer scanner from trying to queue transfers to XMPP remotes.
Made XMPP pair requests that come from the same account we've already paired with be automatically accepted. So once you pair with one device, you can easily add more.
I got full-on git-annex assistant syncing going over XMPP today!
How well does it work? Well, I'm at the cabin behind a dialup modem. I have
two repos that can only communicate over XMPP. One uses my own XMPP server,
and the other uses a Google Talk account. I make a file in one repo, and
switch windows to the other, and type ls, and the file (not its content
tho..) has often already shown up. So, it's about as fast as syncing over
ssh, although YMMV.
Refactored the git push over XMPP code rather severely. It's quite a lot cleaner now.
Set XMPP presence priority to a negative value, which will hopefully prevent git-annex clients that share a XMPP account with other clients from intercepting chat messages. Had to change my XMPP protocol some to deal with this.
Some webapp UI work. When showing the buddy list, indicate which buddies are already paired with.
After XMPP pairing, it now encourages setting up a shared cloud repository.
I still need to do more with the UI after XMPP pairing, to help the paired users configure a shared cloud transfer remote. Perhaps the thing to do is for the ConfigMonitor to notice when a git push adds a new remote, and pop up an alert suggesting the user enable it. Then one user can create the repository, and the other one enable it.
I'm stunned and stoked to have gotten git push over XMPP working today. And am nearly out of steam, it was a wild ride..
To xmpp::joey@kitenet.net
* [new branch] master -> refs/xmpp/newmaster
The surprising part is how close my initial implementation came to just working on the first try. It had around 3 bugs, which took hours of staring at debugging output to find:
- The git push action was run in the same thread as the XMPP client, which prevented the client from continuing to run and relaying messages.
- The git-receive-pack side waited on the wrong thread, so didn't notice when the program was done.
- I accidentally used the wrong attribute name when sending a ReceivePackDone message.
But all in all, it just worked.
Here's a sample of the actual data sent when one file is added to the repository (also includes the corresponding update to the git-annex branch):
MDA4NjhhMmNmOGZjMWE3MTlkOGVjOWVmOWZiMGZiNjVlODc2NjQ1NDAyMTAgODIwNTZjMDM4
ZjU2YzE1ODdjYzllOWRhNzQzMzU0YjE4NzNjZWJlOSByZWZzL3htcHAvbmV3bWFzdGVyACBy
ZXBvcnQtc3RhdHVzIHNpZGUtYmFuZC02NGswMDAw
UEFDSwAAAAIAAAADnAx4nJXLTQ4CIQxA4T2n4AKaAqVAYoxL4y2gU+Jo5iczdeHtnSu4eMm3
ebqJ2NwgSCLmNkTBlKFCYwwhoHOtQ+scqZCwWesms9pcPffc2dXkypCFi/TSG/RGUXIiwojg
HZj60eey2cciX3uXfbeX18Hbe1SZRc9HV+tC9FgyJW9PgACGl2kaVeXfz/wArHQ81qMGeJwz
NDIAAoVUI4ZZB9RW1E8NtXp5t77/fn3hw41cl2MNIbIZqTk5+Qwerw+aJX2INjsffYndtdCz
5mZWLDdUQV5qeVpmDtCQnx/3/6s40+Q4P/7O+Y4ShS+1Ad83AwC6CirftAt4nK3MsRGDMAwF
0IkcSVgSdpkidzRUmcDWBy4pSAEFl+mzRN4A77a9Tmr7vlz06e8lzoPmmb5Mz+k+mD/SkTkl
eFHPq9eqQ+nSzFsWaDFnFmCMCEOvHgLrCrQxS7AWdvUVhv9uPwHxMbfumlvWdco1RLL4wSQF
g0uFFOKu3Q==
Git said this push took 385 bytes; after base64 encoding to transport it over XMPP as shown above, it needs 701 bytes, and the XMPP envelope and encryption adds more overhead (although the XMPP connection may also be compressed?)
Not the most efficient git transport, but still a practical one!
Big thanks by the way to meep, who posted a comment reminding me about
git-remote-helpers. This was the right thing to use for XMPP over git,
it lets the git remote be configured with url = xmpp::user@host.
Next, I need to get the assistant to use this for syncing. Currently, it only pushes a test branch.
I've finished building the XMMP side of git push over XMPP. Now I only have to add code to trigger these pushes. And of course, fix all the bugs, since none of this has been tested at all.
Had to deal with some complications, like handling multiple clients that all want to push at the same time. Only one push is handled at a time; messages for others are queued. Another complication I don't deal with yet is what to do if a client stops responding in the middle of a push. It currently will wait forever for a message from the client; instead it should time out.
Jimmy got the OSX builder working again, despite my best attempts to add dependencies and break it.
Laying the groundwork for git push over XMPP. BTW, the motivation for doing this now is that if the assistant can push git data peer-to-peer, users who are entirely using the cloud don't need to set up a git repo in the cloud somewhere. Instead, a single special remote in the cloud will be all they need. So this is a keystone in the assistant's cloud support.
I'm building the following pipeline:
git push <--> git-annex xmppgit <--> xmppPush <-------> xmpp
|
git receive-pack <--> xmppReceivePack <---------------> xmpp
A tricky part of this is git-annex xmppgit, which is run by git push
rather than the usual ssh. Rather than speak XMPP itself, that feeds the
data through the assistant daemon, using some special FDs that are set
up by the assistant when it runs git push, and communicated via
environment variables. I hoped to set up a pipe and not need it to do any
work on its own, but short of using the linux-specific splice(2), that
doesn't seem possible. It also will receive the exit status of
git receive-pack and propigate it to git push.
Also built the IO sides of xmppPush and xmppReceivePack although these
are not tested. The XMPP sides of them come next.
Stuffing lots of git-annex branded USB keys into envelopes tonight, while watching the election coverage.
Spent about 5 hours the other night in XMPP hell. At every turn Google Talk exhibited behavior that may meet the letter of the XMPP spec (or not), but varies between highly annoying and insane.
By "insane", I mean this: If a presence message is directed from one client to another client belonging to that same user, randomly leaking that message out to other users who are subscribed is just a security hole waiting to happen.
Anyway, I came out of that with a collection of hacks that worked, but I didn't like. I was using directed presence for buddy-to-buddy pairing, and an IQ message hack for client-to-client pairing.
Today I got chat messages working instead, for both sorts of pairing. These chat messages have an empty body, which should prevent clients from displaying them, but they're sent directed to only git-annex clients anyway.
And XMPP pairing 100% works now! Of course, it doesn't know how to git pull over XMPP yet, but everything else works.
Here's a real .git/config generated by the assistant after XMPP pairing.
[remote "joey"]
url =
fetch = +refs/heads/*:refs/remotes/joey/*
annex-uuid = 14f5e93e-1ed0-11e2-aa1c-f7a45e662d39
annex-xmppaddress = joey@kitenet.net
Fixed a typo that led to an infinite loop when adding a ssh git repo with the assistant. Only occurred when an absolute directory was specified, which is why I didn't notice it before.
Security fix: Added a GIT_ANNEX_SHELL_DIRECTORY environment variable that
locks down git-annex-shell to operating in only a single directory. The
assistant sets that in ssh authorized_keys lines it creates. This
prevents someone you pair with from being able to access any other git or
git-annex repositories you may have.
Next up, more craziness. But tomorrow is Nov 6th, so you in the US already knew that..
Reworked my XMPP code, which was still specific to push notification, into a more generic XMPP client, that's based on a very generic NetMessager class, that the rest of the assistant can access without knowing anything about XMPP.
Got pair requests flowing via XMPP ping, over Google Talk! And when the webapp receives a pair request, it'll pop up an alert to respond. The rest of XMPP pairing should be easy to fill in from here.
To finish XMPP pairing, I'll need git pull over XMPP, which is nontrivial, but I think I know basically how to do. And I'll need some way to represent an XMPP buddy as a git remote, which is all that XMPP pairing will really set up.
It could be a git remote using an xmpp:user@host URI for the git url, but
that would confuse regular git to no end (it'd think it was a ssh host),
and probably need lots of special casing in the parts of git-annex that
handle git urls too. Or it could be a git remote without an url set, and
use another config field to represent the XMPP data. But then git wouldn't
think it was a remote at all, which would prevent using "git pull
xmppremote" at all, which I'd like to be able to use when implementing git
pull over XMPP.
Aha! The trick seems to be to leave the url unset in git config, but temporarily set it when pulling:
GIT_SSH=git-annex git git -c remote.xmppremote.url=xmpp:client pull xmppremote
Runs git-annex with "xmpp git-upload-pack 'client'".. Just what I need.
Got the XMPP client maintaining a list of buddies, including tracking which clients are present and away, and which clients are recognised as other git-annex assistant clients. This was fun, it is almost all pure functional code, which always makes me happy.
Started building UI for XMPP pairing. So far, I have it showing a list of buddies who are also running git-annex (or not). The list even refreshes in real time as new buddies come online.

Did a lot of testing, found and fixed 4 bugs with repository setup configurators. None of them were caused by the recent code reworking.
Finished working the new assistant monad into all the assistant's code. I've changed 1870 lines of code in the past two days. It feels like more. While the total number of lines of code has gone up by around 100, the actual code size has gone down; the monad allowed dropping 3.4 kilobytes of manual variable threading complications. Or around 1% of a novel edited away, in other words.
I don't seem to have broken anything, but I'm started an extensive test of all the assistant and webapp. So far, the bugs I've found were not introduced by my monadic changes. Fixed several bugs around adding removable drives, and a few other minor bugs. Plan to continue testing tomorrow.
Spent most of the past day moving the assistant into a monad of its own that encapsulates all the communications channels for its threads. This involved modifiying nearly every line of code in the whole assistant.
Typical change:
handleConnection threadname st dstatus scanremotes pushnotifier = do
reconnectRemotes threadname st dstatus scanremotes (Just pushnotifier)
=<< networkRemotes st
handleConnection = reconnectRemotes True =<< networkRemotes
So, it's getting more readable..
Back in day 85 more foundation work, I wrote:
I suspect, but have not proven, that the assistant is able to keep repos arranged in any shape of graph in sync, as long as it's connected (of course) and each connection is bi-directional. [And each node is running the assistant.]
After today's work, many more graph topologies can be kept in sync -- the assistant now can keep repos in sync that are not directly connected, but must go through a central transfer point, which does not run the assistant at all. Major milestone!
To get that working, as well as using XMPP push notifications, it turned out to need to be more agressive about pushing out changed location log information. And, it seems, that was the last piece that was missing. Although I narrowly avoided going down a blind alley involving sending transfer notifications over XMPP. Luckily, I came to my senses.
This month's focus was the cloud, and the month is almost done. And now the assistant can, indeed be used to sync over the cloud! I would have liked to have gotten on to implementing Amazon Glacier or Google Drive support, but at least the cloud fundamentals are there.
Now that I have XMPP support, I'm tending toward going ahead and adding XMPP pairing, and git push over XMPP. This will open up lots of excellent use cases.
So, how to tunnel git pushes over XMPP? Well, GIT_SHELL can be set to
something that intercepts the output of git-send-pack and
git-receive-pack, and that data can be tunneled through XMPP to connect
them. Probably using XMPP ping.
(XEP-0047: In-Band Bytestreams would be the right way ...
but of course Google Talk doesn't support that extension.)
XMPP requires ugly encoding that will bloat the data, but the data quantities are fairly small to sync up a few added or moved files (of course, we'll not be sending file contents over XMPP). Pairing with an large git repository over XMPP will need rather more bandwidth, of course.
Continuing to flail away at this XMPP segfault, which turned out not to be fixed by bound threads. I managed to make a fairly self-contained and small reproducible test case for it that does not depend on the network. Seems the bug is gonna be either in the Haskell binding for GNUTLS, or possibly in GNUTLS itself.
Update: John was able to fix it using my testcase! It was a GNUTLS credentials object that went out of scope and got garbage collected. I think I was seeing the crash only with the threaded runtime because it has a separate garbage collection thread.
Arranged for the XMPP thread to restart when network connections change, as well as when the webapp configures it.
Added an alert to nudge users to enable XMPP. It's displayed after adding a remote in the cloud.

So, the first stage of XMPP is done. But so far all it does is push notification. Much more work to do here.
Built a SRV lookup library that can use either host or ADNS.
Worked on DBUS reconnection some more; found a FD leak in the dbus library, and wrote its long-suffering author, John Millikin (also the XMPP library author, so I've been bothering him a lot lately), who once again came through with a quick fix.
Built a XMPP configuration form, that tests the connection to the server. Getting the wording right on this was hard, and it's probably still not 100% right.
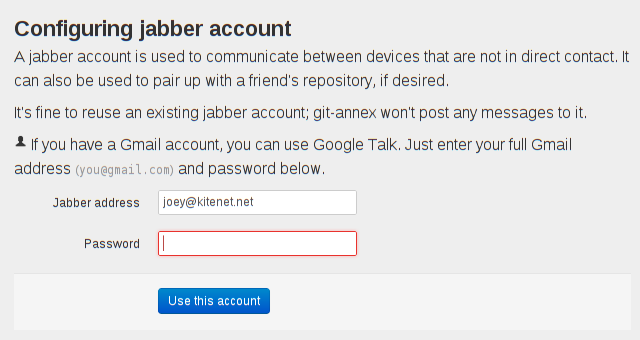
Pairing over XMPP is something I'm still thinking about. It's contingent on tunneling git over XMPP (actually not too hard), and getting a really secure XMPP connection (needs library improvements, as the library currently accepts any SSL certificate).
Had to toss out my XMPP presence hack. Turns out that, at least in Google Talk, presence info is not sent to clients that have marked themselves unavailable, and that means the assistant would not see notifications, as it was nearly always marked unavailable as part of the hack.
I tried writing a test program that uses XMPP personal eventing, only to find that Google Talk rejected my messages. I'm not 100% sure my messages were right, but I was directly copying the example in the RFC, and prosody accepted them. I could not seem to get a list of extensions out of Google Talk either, so I don't know if it doesn't support personal eventing, or perhaps only supports certian specific types of events.
So, plan C... using XMPP presence extended content. The assistant generates a presence message tagged "xa" (Extended Away), which hopefully will make it not seem present to clients. And to that presence message, I add my own XML element:
<git-annex xmlns='git-annex' push="uuid,uuid" />
This is all entirely legal, and not at all a hack. (Aside from this not really being presence info.) Isn't XML fun?
And plan C works, with Google Talk, and prosody. I've successfully gotten push notifications flowing over XMPP!
Spent some hours dealing with an unusual probolem: git-annex started segfaulting intermittently on startup with the new XMPP code.
Haskell code is not supposed to segfault..
I think this was probably due to not using a bound thread for XMPP, so if haskell's runtime system recheduled its green thread onto a different OS thread during startup, when it's setting up TLS, it'd make gnuTLS very unhappy.
So, fixed it to use a bound thread. Will wait and see if the crash is gone.
Re-enabled DBUS support, using a new version of the library that avoids the memory leak. Will need further changes to the library to support reconnecting to dbus.
Next will be a webapp configuration UI for XMPP. Various parts of the webapp will direct the user to set up XMPP, when appropriate, especially when the user sets up a cloud remote.
To make XMPP sufficiently easy to configure, I need to check SRV records to
find the XMPP server, which is an unexpected PITA because getaddrinfo
can't do that. There are several haskell DNS libraries that I could use for
SRV, or I could use the host command:
host -t SRV _xmpp-client._tcp.gmail.com
Built out the XMPP push notifier; around 200 lines of code.
Haven't tested it yet, but it just might work. It's in the xmpp branch
for now.
I decided to send the UUID of the repo that was pushed to, otherwise peers would have to speculatively pull from every repo. A wrinkle in this is that not all git repos have a git-annex UUID. So it might notify that a push was sent to an unidentified repo, and then peers need to pull from every such repo. In the common case, there will only be one or a few such repos, at someplace like at github that doesn't support git-annex. I could send the URL, but there's no guarantee different clients have the same URLs for a git remote, and also sending the URL leaks rather more data than does a random UUID.
Had a bit of a scare where it looked like I couldn't use the haskell
network-protocol-xmpp package together with the mtl package that
git-annex already depends on. With help from #haskell I found the way
to get them co-existing, by using the PackageImports extension. Whew!
Need to add configuration of the XMPP server to use in the webapp, and
perhaps also a way to create .git/annex/creds/notify-xmpp from the
command line.
Time to solve the assistant's cloud notification problem. This is really the last big road-bump to making it be able to sync computers across the big, bad internet.
So, IRC still seems a possibility, but I'm going to try XMPP first. Since Google Talk uses XMPP, it should be easy for users to get an account, and it's also easy to run your own XMPP server.
Played around with the Haskell XMPP library. Clint helpfully showed me an example of a simple client, which helped cut through that library's thicket of data types. In short order I had some clients that were able to see each other connecting to my personal XMPP server. On to some design..
I want to avoid user-visible messages. (dvcs-autosync also uses XMPP, but I checked the code and it seems to send user-visible messages, so I diverge from its lead here.) This seems very possible, only a matter of finding the right way to use the protocol, or an appropriate and widely deployed extension. The only message I need to send with XMPP, really, is "I have pushed to our git repo". One bit of data would do; being able to send a UUID of the repo that did the update would be nice.
I'd also like to broadcast my notification to a user's buddies. dvcs-autosync sends only self-messages, but that requires every node have the same XMPP account configured. While I want to be able to run in that mode, I also want to support pairs of users who have their own XMPP accounts, that are buddied up in XMPP.
To add to the fun, the assistant's use of XMPP should not make that XMPP account appear active to its buddies. Users should not need a dedicated XMPP account for git-annex, and always seeming to be available when git-annex is running would not be nice.
The first method I'm trying out is to encode the notification data inside a XMPP presence broadcast. This should meet all three requirements. The plan is two send two presence messages, the first marks the client as available, and the second as unavailable again. The "id" attribute will be set to some value generated by the assistant. That attribute is allowed on presence messages, and servers are required to preserve it while the client is connected. (I'd only send unavailable messages, but while that worked when I tested it using the prosody server, with google talk, repeated unavailable messages were suppressed. Also, google talk does not preserve the "id" attribute of unavailable presence messages.)
If this presence hackery doesn't work out, I could try XEP-0163: Personal Eventing Protocol. But I like not relying on any extensions.
Added yet another thread, the ConfigMonitor. Since that thread needs to run code to reload cached config values from the git-annex branch when files there change, writing it also let me review where config files are cached, and I found that every single config file in the git-annex branch does get cached, with the exception of the uuid.log. So, added a cache for that, and now I'm more sanguine about yesterday's removal of the lower-level cache, because the only thing not being cached is location log information.
The ConfigMonitor thread seems to work, though I have not tested it extensively. The assistant should notice and apply config changes made locally, as well as any config changes pushed in from remotes. So, for example, if you add a S3 repo in the webapp, and are paired with another computer, that one's webapp will shortly include the new repo in its list. And all the preferred content, groups, etc settings will propigate over and be used as well.
Well ... almost. Seems nothing causes git-annex branch changes to be pushed, until there's some file change to sync out.
Got preferred content checked when files are moved around. So, in repositories in the default client group, if you make a "archive" directory and move files to it, the assistant will drop their content (when possible, ie when it's reached an archive or backup). Move a file out of an archive directory, and the assistant will get its content again. Magic.
Found an intractable bug, obvious in retrospect, with the git-annex branch read cache, and had to remove that cache. I have not fully determined if this will slow down git-annex in some use cases; might need to add more higher-level caching. It was a very minimal cache anyway, just of one file.
Removed support for "in=" from preferred content expressions. That was problematic in two ways. First, it referred to a remote by name, but preferred content expressions can be evaluated elsewhere, where that remote doesn't exist, or a different remote has the same name. This name lookup code could error out at runtime. Secondly, "in=" seemed pretty useless, and indeed counterintuitive in preferred content expressions. "in=here" did not cause content to be gotten, but it did let present content be dropped. Other uses of "in=" are better handled by using groups.
In place of "in=here", preferred content expressions can now use "present", which is useful if you want to disable automatic getting or dropping of content in some part of a repository. Had to document that "not present" is not a good thing to use -- it's unstable. Still, I find "present" handy enough to put up with that wart.
Realized last night that the code I added to the TransferWatcher to check preferred content once a transfer is done is subject to a race; it will often run before the location log gets updated. Haven't found a good solution yet, but this is something I want working now, so I did put in a quick delay hack to avoid the race. Delays to avoid races are never a real solution, but sometimes you have to TODO it for later.
Been thinking about how to make the assistant notice changes to configuration in the git-annex branch that are merged in from elsewhere while it's running. I'd like to avoid re-reading unchanged configuration files after each merge of the branch.
The most efficient way would be to reorganise the git-annex branch, moving
config files into a configs directory, and logs into a logs directory. Then it
could git ls-tree git-annex configs and check if the sha of the configs
directory had changed, with git doing minimal work
(benchmarked at 0.011 seconds).
Less efficiently, keep the current git-annex branch layout, and
use: git ls-tree git-annex uuid.log remote.log preferred-content.log group.log trust.log
(benchmarked at 0.015 seconds)
Leaning toward the less efficient option, with a rate limiter so it doesn't try more often than once every minute. Seems reasonable for it to take a minute for config changes take effect on remote repos, even if the assistant syncs file changes to them more quickly.
Got unwanted content to be dropped from the local repo, as well as remotes when doing the expensive scan. I kept the scan a single pass for now, need to revisit that later to drop content before transferring more. Also, when content is downloaded or uploaded, this can result in it needing to be dropped from somewhere, and the assistant handles that too.
There are some edge cases with hypothetical, very weird preferred content expressions, where the assistant won't drop content right away. (But will later in the expensive scan.) Other than those, I think I have nearly all content dropping sorted out. The only common case I know of where unwanted content is not dropped by the assistant right away is when a file is renamed (eg, put in a "Trash" directory).
In other words, repositories put into the transfer group will now work as described, only retaining content as long as is needed to distribute it to clients. Big milestone!
I released git-annex an unprecidented two times yesterday, because just after the first release, I learned of a another zombie problem. Turns out this zombie had existed for a while, but it was masked by zombie reaping code that I removed recently, after fixing most of the other zombie problems. This one, though, is not directly caused by git-annex. When rsync runs ssh, it seems to run two copies, and one is left unwaited on as a zombie. Oddly, this only happens when rsync's stdout is piped into git-annex, for progress bar handling. I have not source-dived rsync's code to get to the bottom of this, but I put in a workaround.
I did get to the bottom of yesterday's runaway dbus library. Got lucky and found the cause of the memory leak in that library on the first try, which is nice since each try involved logging out of X. I've been corresponding with its author, and a fix will be available soon, and then git-annex will need some changes to handle dbus reconnection.
For the first time, I'm starting to use the assistant on my own personal git-annex repo. The preferred content and group settings let me configure it use the complex system of partial syncing I need. For example, I have this configured for my sound files, keeping new podcasts on a server until they land somewhere near me. And keeping any sound files that I've manually put on my laptop, and syncing new podcasts, but not other stuff.
# (for my server)
preferred-content 87e06c7a-7388-11e0-ba07-03cdf300bd87 = include=podcasts/* and (not copies=nearjoey:1)
# (for my laptop)
preferred-content 0c443de8-e644-11df-acbf-f7cd7ca6210d = exclude=*/out/* and (in=here or (include=podcasts/*))
Found and fixed a bug in the preferred content matching code, where if the assistant was run in a subdirectory of the repo, it failed to match files correctly.
More bugfixes today. The assistant now seems to have enough users that they're turning up interesting bugs, which is good. But does keep me too busy to add many more bugs^Wcode.
The fun one today made it bloat to eat all memory when logging out of a Linux desktop. I tracked that back to a bug in the Haskell DBUS library when a session connection is open and the session goes away. Developed a test case, and even profiled it, and sent it all of to the library's author. Hopefully there will be a quick fix, in the meantime today's release has DBUS turned off. Which is ok, it just makes it a little bit slower to notice some events.
I was mostly working on other things today, but I did do some bug fixing.
The worst of these is a bug introduced in 3.20121009 that breaks
git-annex-shell configlist. That's pretty bad for using git-annex
on servers, although you mostly won't notice unless you're just getting
started using a ssh remote, since that's when it calls configlist.
I will be releasing a new version as soon as I have bandwidth (tomorrow).
Also made the standalone Linux and OSX binaries build with ssh connection caching disabled, since they don't bundle their own ssh and need to work with whatever ssh is installed.
Did a fair amount of testing and bug fixing today.
There is still some buggy behavior around pausing syncing to a remote, where transfers still happen to it, but I fixed the worst bug there.
Noticed that if a non-bare repo is set up on a removable drive, its file tree will not normally be updated as syncs come in -- because the assistant is not running on that repo, and so incoming syncs are not merged into the local master branch. For now I made it always use bare repos on removable drives, but I may want to revisit this.
The repository edit form now has a field for the name of the repo,
so the ugly names that the assistant comes up with for ssh remotes
can be edited as you like. git remote rename is a very nice thing.
Changed the preferred content expression for transfer repos to this: "not (inallgroup=client and copies=client:2)". This way, when there's just one client, files on it will be synced to transfer repos, even though those repos have no other clients to transfer them to. Presumably, if a transfer repo is set up, more clients are coming soon, so this avoids a wait. Particularly useful with removable drives, as the drive will start being filled as soon as it's added, and can then be brought to a client elsewhere. The "2" does mean that, once another client is found, the data on the transfer repo will be dropped, and so if it's brought to yet another new client, it won't have data for it right away. I can't see way to generalize this workaround to more than 2 clients; the transfer repo has to start dropping apparently unwanted content at some point. Still, this will avoid a potentially very confusing behavior when getting started.
I need to get that dropping of non-preferred content to happen still. Yesterday, I did some analysis of all the events that can cause previously preferred content to no longer be preferred, so I know all the places I have to deal with this.
The one that's giving me some trouble is checking in the transfer scan. If it checks for content to drop at the same time as content to transfer, it could end up doing a lot of transfers before dropping anything. It'd be nicer to first drop as much as it can, before getting more data, so that transfer remotes stay as small as possible. But the scan is expensive, and it'd also be nice not to need two passes.
Switched the OSX standalone app to use DYLD_ROOT_PATH.
This is the third DYLD_* variable I've tried; neither
of the other two worked in all situations. This one may do better.
If not, I may be stuck modifying the library names in each executable
using install_name_tool
(good reference for doing that).
As far as I know, every existing dynamic library lookup system is broken
in some way other other; nothing I've seen about OSX's so far
disproves that rule.
Fixed a nasty utf-8 encoding crash that could occur when merging the git-annex branch. I hope I'm almost done with those.
Made git-annex auto-detect when a git remote is on a sever like github that doesn't support git-annex, and automatically set annex-ignore.
Finished the UI for pausing syncing of a remote. Making the syncing actually stop still has some glitches to resolve.
Bugfixes all day.
The most amusing bug, which I just stumbled over randomly on my own,
after someone on IRC yesterday was possibly encountering the same issue,
made git annex webapp go into an infinite memory-consuming loop on
startup if the repository it had been using was no longer a valid git
repository.
Then there was the place where HOME got unset, with also sometimes amusing results.
Also fixed several build problems, including a threaded runtime hang in the test suite. Hopefully the next release will build on all Debian architectures again.
I'll be cutting that release tomorrow. I also updated the linux prebuilt tarballs today.
Hmm, not entirely bugfixes after all. Had time (and power) to work on the repository configuration form too, and added a check box to it that can be unchecked to disable syncing with a repository. Also, made that form be displayed after the webapp creates a new repository.
today
Came up with four groups of repositories that it makes sense to define standard preferred content expressions for.
preferredContent :: StandardGroup -> String
preferredContent ClientGroup = "exclude=*/archive/*"
preferredContent TransferGroup = "not inallgroup=client and " ++ preferredContent ClientGroup
preferredContent ArchiveGroup = "not copies=archive:1"
preferredContent BackupGroup = "" -- all content is preferred
preferred content has the details about these groups, but as I was writing those three preferred content expressions, I realized they are some of the highest level programming I've ever done, in a way.
Anyway, these make for a very simple repository configuration UI:
yesterday (forgot to post this)
Got the assistant honoring preferred content settings. Although so far that only determines what it transfers. Additional work will be needed to make content be dropped when it stops being preferred.
Added a "configure" link next to each repository on the repository config page. This will go to a form to allow setting things like repository descriptions, groups, and preferred content settings.
Cut a release.
Preferred content control is wired up to --auto and working for get,
copy, and drop. Note that drop --from remote --auto drops files that
the remote's preferred content settings indicate it doesn't want;
likewise copy --to remote --auto sends content that the remote does want.
Also implemented smallerthan, largerthan, and ingroup limits,
which should be everything needed for the scenarios described in
transfer control.
Dying to hook this up to the assistant, but a cloudy day is forcing me to curtail further computer use.
Also, last night I developed a patch for the hS3 library, that should let
git-annex upload large files to S3 without buffering their whole content in
memory. I have a s3-memory-leak in git-annex that uses the new API I
developed. Hopefully hS3's maintainer will release a new version with that
soon.
Fixed the assistant to wait on all the zombie processes that would sometimes pile up. I didn't realize this was as bad as it was.
Zombies and git-annex have been a problem since I started developing it, because back then I made some rather poor choices, due to barely knowing how to write Haskell. So parts of the code that stream input from git commands don't clean up after them properly. Not normally a problem, because git-annex reaps the zombies after each file it processes. But this reaping is not thread-safe; it cannot be used in the assistant.
If I were starting git-annex today, I'd use one of the new Haskell things like Conduits, that allow for very clean control over finalization of resources. But switching it to Conduits now would probably take weeks of work; I've not yet felt it was worthwhile. (Also it's not clear Conduits are the last, best thing.)
For now, it keeps track of the pids it needs to wait on, and all the code run by the assistant is zombie-free. However, some code for fsck and unused that I anticipate the assistant using eventually still has some lurking zombies.
Solved the issue with preferred content expressions and dropping that I mentioned yesterday. My solution was to add a parameter to specify a set of repositories where content should be assumed not to be present. When deciding whether to drop, it can put the current repository in, and then if the expression fails to match, the content can be dropped.
Using yesterday's example "(not copies=trusted:2) and (not in=usbdrive)", when the local repo is one of the 2 trusted copies, the drop check will see only 1 trusted copy, so the expression matches, and so the content will not be dropped.
I've not tested my solution, but it type checks. :P I'll wire it up to
get/drop/move --auto tomorrow and see how it performs.
Would preferred content expressions be more readble if they were inverted (becoming content filtering expressions)?
- "(not copies=trusted:2) and (not in=usbdrive)" becomes "copies=trusted:2 or in=usbdrive"
- "smallerthan=10mb and include=.mp3 and exclude=junk/" becomes "largerthan=10mb or exclude=.mp3" or include=junk/"
- "(not group=archival) and (not copies=archival:1)" becomes "group=archival or copies=archival:1"
1 and 3 are improved, but 2, less so. It's a trifle weird for "include" to mean "include in excluded content".
The other reason not to do this is that currently the expressions
can be fed into git annex find on the command line, and it'll come
back with the files that would be kept.
Perhaps a middle groud is to make "dontwant" be an alias for "not". Then we can write "dontwant (copies=trusted:2 or in=usbdrive)"
A user told me this:
I can confirm that the assistant does what it is supposed to do really well. I just hooked up my notebook to the network and it starts syncing from notebook to fileserver and the assistant on the fileserver also immediately starts syncing to the [..] backup
That makes me happy, it's the first quite so real-world success report I've heard.
Started implementing transfer control. Although I'm currently calling the configuration for it "preferred content expressions". (What a mouthful!)
I was mostly able to reuse the Limit code (used to handle parameters like --not --in otherrepo), so it can already build Matchers for preferred content expressions in my little Domain Specific Language.
Preferred content expressions can be edited with git annex vicfg, which
checks that they parse properly.
The plan is that the first place to use them is not going to be inside the
assistant, but in commands that use the --auto parameter, which will use
them as an additional constraint, in addition to the numcopies setting
already used. Once I get it working there, I'll add it to the assistant.
Let's say a repo has a preferred content setting of "(not copies=trusted:2) and (not in=usbdrive)"
git annex get --autowill get files that have less than 2 trusted copies, and are not in the usb drive.git annex drop --autowill drop files that have 2 or more trusted copies, and are not in the usb drive (assuming numcopies allows dropping them of course).git annex copy --auto --to thatreporun from another repo will only copy files that have less than 2 trusted copies. (And if that was run on the usb drive, it'd never copy anything!)
There is a complication here.. What if the repo with that preferred content
setting is itself trusted? Then when it gets a file, its number of
trusted copies increases, which will make it be dropped again. 
This is a nuance that the numcopies code already deals with, but it's much harder to deal with it in these complicated expressions. I need to think about this; the three ideas I'm working on are:
- Leave it to whoever/whatever writes these expressions to write ones that avoid such problems. Which is ok if I'm the only one writing pre-canned ones, in practice..
- Transform expressions into ones that avoid such problems. (For example, replace "not copies=trusted:2" with "not (copies=trusted:2 or (in=here and trusted=here and copies=trusted:3))"
- Have some of the commands (mostly drop I think) pretend the drop has already happened, and check if it'd then want to get the file back again.
Not a lot of programming today; I spent most of the day stuffing hundreds of envelopes for this Kickstarter thing you may have heard of. Some post office is going to be very surprised with all the international mail soon.
That said, I did write 184 lines of code. (Actually rather a lot, but it was mostly pure functional code, so easy to write.) That pops up your text editor on a file with the the trust and group configurations of repositories, that's stored in the git-annex branch. Handy for both viewing that stuff all in one place, and changing it.
The real reason for doing that is to provide a nice interface for editing transfer control expressions, which I'll be adding next.
Today I revisited something from way back in day 7 bugfixes.
Back then, it wasn't practical to run git ls-files on every
file the watcher noticed, to check if it was already in git. Revisiting
this, I found I could efficiently do that check at the same point it checks
lsof. When there's a lot of files being added, they're batched up at that
point, so it won't be calling git ls-files repeatedly.
Result: It's safe to mix use of the assistant with files stored in git
in the normal way. And it's safe to mix use of git annex unlock with
the assistant; it won't immediately re-lock files. Yay!
Also fixed a crash in the committer, and made git annex status display
repository groups.
Been thinking through where to store the transfer control expressions.
Since repositories need to know about the transfer controls of other
remotes, storing them in .git/config isn't right. I thought it might be
nice to configure the expressions in .gitattributes, but it seems the
file format doesn't allow complicated multi-word attributes. Instead,
they'll be stored in the git-annex branch.
Spent a lot of time this weekend thinking about/stuck on the cloud notification problem. Currently IRC is looking like the best way for repositories to notify one-another when changes are made, but I'm not sure about using that, and not ready to start on it.
Instead, laid some groundwork for transfer control today. Added some simple commands to manage groups of repositories, and find files that are present in repositories in a group. I'm not completely happy with the syntax for that, and need to think up some good syntax to specify files that are present in all repositories in a group.
The plan is to have the assistant automatically guess at groups to put new repositories it makes in (it should be able to make good guesses), as well as have an interface to change them, and an interface to configure transfer control using these groups (and other ways of matching files). And, probably, some canned transfer control recipes for common setups.
Collected up the past week's work and made a release today. I'm probably back to making regular releases every week or two.
I hear that people want the git-annex assistant to be easy to install without messing about building it from source..
on OSX
So Jimmy and I have been working all week on making an easily installed OSX app of the assistant. This is a .dmz file that bundles all the dependencies (git, etc) in, so it can be installed with one click.
It seems to basically work. You can get it here.
Unfortunatly, the ?pasting into annex on OSX bug resurfaced while testing this.. So I can't really recommend using it on real data yet.
Still, any testing you can do is gonna be really helpful. I'm squashing OSX bugs right and left.
on Linux
First of all, the git-annex assistant is now available in Debian unstable, and in Arch Linux's AUR. Proper packages.
For all the other Linux distributions, I have a workaround. It's a big hack, but it seems to work.. at least on Debian stable.
I've just put up a linux standalone tarball, which has no library dependencies apart from glibc, and doesn't even need git to be installed on your system.
on FreeBSD
The FreeBSD port has been updated to include the git-annex assistant too..
Various bug fixes, and work on the OSX app today:
- Avoid crashing when ssh-keygen fails due to not being able to parse
authorized_keys.. seems a lot of people have crufty unparsableauthorized_keysfiles. - On OSX, for some reason the webapp was failing to start sometimes due to bind failing with EINVAL. I don't understand why, as that should only happen if the socket is already bound, which it should not as it's just been created. I was able to work around this by retrying with a new socket when bind fails.
- When setting up
authorized_keysto letgit-annex-shellbe run, it had been inserting a perl oneliner into it. I changed that to instead call a~/.ssh/git-annex-shellwrapper script that it sets up. The benefits are it no longer needs perl, and it's less ugly, and the standalone OSX app can modify the wrapper script to point to wherever it's installed today (people like to move these things around I guess). - Made the standalone OSX app set up autostarting when it's first run.
- Spent rather a long time collecting the licenses of all the software that will be bundled with the standalone OSX app. Ended up with a file containing 3954 lines of legalese. Happily, all the software appears redistributable, and free software; even the couple of OSX system libraries we're bundling are licensed under the APSL.
Amazon S3 was the second most popular choice in the prioritizing special remotes poll, and since I'm not sure how I want to support phone/mp3 players, I did it first.
So I added a configurator today to easily set up an Amazon S3 repository. That was straightforward and didn't take long since git-annex already supported S3.
The hard part, of course, is key distribution. Since the webapp so far can only configure the shared encryption method, and not fullblown gpg keys, I didn't feel it would be secure to store the S3 keys in the git repository. Anyone with access to that git repo would have full access to S3 ... just not acceptable. Instead, the webapp stores the keys in a 600 mode file locally, and they're not distributed at all.
When the same S3 repository is enabled on another computer, it prompts for keys then too. I did add a hint about using the IAM Management Console in this case -- it should be possible to set up users in IAM who can only access a single bucket, although I have not tried to set that up.
Also, more work on the standalone OSX app.
Mostly took a break from working on the assistant today. Instead worked on adding incremental fsck to git-annex. Well, that will be something that assistant will use, eventually, probably.
Jimmy and I have been working on a self-contained OSX app for using the assistant, that doesn't depend on installing git, etc. More on that once we have something that works.
Just released git-annex 3.20120924, which includes beta versions of the assistant and webapp. Read the ?errata, then give it a try!
I've uploaded it to Haskell's cabal, and to Debian unstable, and hope my helpers for other distributions will update them soon. (Although the additional dependencies to build the webapp may take a while on some.) I also hope something can be done to make a prebuilt version available on OSX soonish.
I've decided to license the webapp under the AGPL. This should not impact normal users of it, and git-annex can be built without the webapp as a pure GPL licensed program. This is just insurance to prevent someone turning the webapp into a propritary web-only service, by requiring that anyone who does so provide the source of the webapp.
Finally wrapped up progress bars; upload progress is now reported in all situations.
After all that, I was pleased to find a use for the progress info, beyond displaying it to the user. Now the assistant uses it to decide whether it makes sense to immediately retry a failed transfer. This should make it work nicely, or at least better, with flaky network or drives.
The webapp crashed on startup when there was no ~/.gitconfig.
Guess all of us who have tried it so far are actual git users,
but I'm glad I caught this before releasing the beta.
Jimmy Tang kindly took on making a OS X .app directory for git-annex.
So it now has an icon that will launch the webapp.
I'm getting lots of contributors to git-annex all of a sudden. I've had 3 patches this weekend, and 2 of them have been to Haskell code. Justin Azoff is working on ?incremental fsck, and Robie Basak has gotten Amazon Glacier working using the hook special remote.
Started doing some design for transfer control. I will start work on this after releasing the first beta.
Short day today, but I again worked only on progress bars.
- Added upload progress tracking for the directory special remote.
- Some optimisations.
- Added a
git annex-shell transferkeycommand. This isn't used yet, but the plan is to use it to feed back information about how much of a file has been sent when downloading it. So that the uploader can display a progress bar. This method avoids needing to parse the rsync protocol, which is approximately impossible without copying half of rsync. Happily, git-annex's automatic ssh connection caching will make the small amount of data this needs to send be efficiently pipelined over the same ssh connection that rsync is using.
I probably have less than 10 lines of code to write to finish up
progressbars for now. Looking forward to getting that behind me, and on
to something more interesting. Even doing mail merge to print labels to
mail out Kickstarter rewards is more interesting than progress bars at this
point.
Worked more on upload progress tracking. I'm fairly happy with its state now:
It's fully implemented for rsync special remotes.
Git remotes also fully support it, with the notable exception of file uploads run by
git-annex-shell recvkey. That runsrsync --server --sender, and in that mode, rsync refuses to output progress info. Not sure what to do about this case. Maybe I should write a parser for the rsync wire protocol that can tell what chunk of the file is being sent, and shim it in front of the rsync server? That's rather hardcore, but it seems the best of a bad grab bag of options that include things likeLD_PRELOADhacks.Also optimised the rsync progress bar reader to read whole chunks of data rather than one byte at a time.
Also got progress bars to actually update in the webapp for uploads.
This turned out to be tricky because kqueue cannot be used to detect when existing files have been modified. (One of kqueue's worst shortcomings vs inotify.) Currently on kqueue systems it has to poll.
I will probably upload add progress tracking to the directory special remote, which should be very easy (it already implements its own progress bars), and leave the other special remotes for later. I can add upload progress tracking to each special remote when I add support for configuring it in the webapp.
Putting together a shortlist of things I want to sort out before the beta.
- Progress bars for file uploads.
- No mocked up parts in the webapp's UI. Think I implemented the last of those yesterday, although there are some unlinked repository configuration options.
- The basic watching functionality, should work reliably. There are some known scalability issues with eg, kqueue on OSX that need to be dealt with, but needn't block a beta.
- Should keep any configuration of repositories that can be set up using the webapp in sync whenever it's possible to do so. I think that'll work after the past few days work.
- Should be easy to install and get running. Of course part of the point of the beta release is to get it out there, on Hackage, in Debian unstable, and in the other places that git-annex packagers put it. As to getting it running, the autostart files and menu items look good on Linux. The OSX equivilants still need work and testing.
- No howlingly bad bugs. ?This bug is the one I'm most concerned with currently. OTOH, ?watcher commits unlocked files can be listed in the errata.
So I worked on progress bars for uploads today. Wrote a nice little parser for rsync's progress output, that parses arbitrary size chunks, returning any unparsable part. Added a ProgressCallback parameter to all the backends' upload methods. Wrote a nasty thing that intercepts rsync's output, currently a character at a time (horrible, but rsync doesn't output that much, so surprisingly acceptable), and outputs it and parses it. Hooked all this up, and got it working for uploads to git remotes. That's 1/10th of the total ways uploads can happen that have working progress bars. It'll take a while to fill in the rest..
Turns out I was able to easily avoid the potential upload loops that would occur if each time a repo receives a download, it queues uploads to the repos it's connected to. With that done. I suspect, but have not proven, that the assistant is able to keep repos arranged in any shape of graph in sync, as long as it's connected (of course) and each connection is bi-directional. That's a good start .. or at least a nice improvement from only strongly connected graphs being kept in sync.
Eliminated some empty commits that would be made sometimes, which is a nice optimisation.
I wanted to get back to some UI work after this week's deep dive into the internals. So I filled in a missing piece, the repository switcher in the upper right corner. Now the webapp's UI allows setting up different repositories for different purposes, and switching between them.
Implemented deferred downloads. So my example from yesterday of three repositories in a line keep fully in sync now!
I punted on one problem while doing it. It might be possible to get a really big list of deferred downloads in some situation. That all lives in memory. I aim for git-annex to always have a constant upper bound on memory use, so that's not really acceptable. I have TODOed a reminder to do something about limiting the size of this list.
I also ran into a nasty crash while implementing this, where two threads were trying to do things to git HEAD at the same time, and so one crashed, and in a way I don't entirely understand, that crash took down another thread with a BlockedIndefinitelyOnSTM exception. I think I've fixed this, but it's bothersome that this is the second time that modifications to the Merger thread have led to a concurrency related crash that I have not fully understood.
My guess is that STM can get confused when it's retrying, and the thread that was preventing it from completing a transaction crashes, because it suddenly does not see any other references to the TVar(s) involved in the transaction. Any GHC STM gurus out there?
Still work to be done on making data transfers to keep fully in sync in all circumstances. One case I've realized needs work occurs when a USB drive is plugged in. Files are downloaded from it to keep the repo in sync, but the repo neglects to queue uploads of those files it just got out to other repositories it's in contact with. Seems I still need to do something to detecting when a successful download is done, and queue uploads.
Syncing works well when the graph of repositories is strongly connected. Now I'm working on making it work reliably with less connected graphs.
I've been focusing on and testing a doubly-connected list of repositories,
such as: A <-> B <-> C
I was seeing a lot of git-annex branch push failures occuring in this line of repositories topology. Sometimes was is able to recover from these, but when two repositories were trying to push to one-another at the same time, and both failed, both would pull and merge, which actually keeps the git-annex branch still diverged. (The two merge commits differ.)
A large part of the problem was that it pushed directly into the git-annex
branch on the remote; the same branch the remote modifies. I changed it to
push to synced/git-annex on the remote, which avoids most push failures.
Only when A and C are both trying to push into B/synced/git-annex at the
same time would one fail, and need to pull, merge, and retry.
With that change, git syncing always succeeded in my tests, and without needing any retries. But with more complex sets of repositories, or more traffic, it could still fail.
I want to avoid repeated retries, exponential backoffs, and that kind of thing. It'd probably be good enough, but I'm not happy with it because it could take arbitrarily long to get git in sync.
I've settled on letting it retry once to push to the synced/git-annex and synced/master branches. If the retry fails, it enters a fallback mode, which is guaranteed to succeed, as long as the remote is accessible.
The problem with the fallback mode is it uses really ugly branch names.
Which is why Joachim Breitner and I originally decided on making git annex
sync use the single synced/master branch, despite the potential for
failed syncs. But in the assistant, the requirements are different,
and I'm ok with the uglier names.
It does seem to make sense to only use the uglier names as a fallback,
rather than by default. This preserves compatability with git annex sync,
and it allows the assistant to delete fallback sync branches after it's
merged them, so the ugliness is temporary.
Also worked some today on a bug that prevents C from receiving files added to A.
The problem is that file contents and git metadata sync independantly. So C will probably receive the git metadata from B before B has finished downloading the file from A. C would normally queue a download of the content when it sees the file appear, but at this point it has nowhere to get it from.
My first stab at this was a failure. I made each download of a file result in uploads of the file being queued to every remote that doesn't have it yet. So rather than C downloading from B, B uploads to C. Which works fine, but then C sees this download from B has finished, and proceeds to try to re-upload to B. Which rejects it, but notices that this download has finished, so re-uploads it to C...
The problem with that approach is that I don't have an event when a download succeeds, just an event when a download ends. Of course, C could skip uploading back to the same place it just downloaded from, but loops are still possible with other network topologies (ie, if D is connected to both B and C, there would be an upload loop 'B -> C -> D -> B`). So unless I can find a better event to hook into, this idea is doomed.
I do have another idea to fix the same problem. C could certainly remember that it saw a file and didn't know where to get the content from, and then when it receives a git push of a git-annex branch, try again.
Started today doing testing of syncing, and found some bugs and things
it needs to do better. But was quickly sidetracked when I noticed that
transferkey was making a commit to the git-annex branch for every file it
transferred, which is too slow and bloats history too much.
To fix that actually involved fixing a long-standing annoyance; that
read-only git-annex commands like whereis sometimes start off with
"(Recording state in git)", when the journal contains some not yet
committed changes to the git-annex branch. I had to carefully think
through the cases to avoid those commits.
As I was working on that, I found a real nasty lurking bug in the git-annex
branch handling. It's unlikely to happen unless annex.autocommit=false is
set, but it could occur when two git-annex processes race one another just
right too. The root of the bug is that git cat-file --batch does not
always show changes made to the index after it started. I think it does
in enough cases to have tricked me before, but in general it can't be
trusted to report the current state of the index, but only some past state.
I was able to fix the bug, by ensuring that changes being made to the branch are always visible in either the journal or the branch -- never in the index alone.
Hopefully something less low-level tomorrow..!
It's possible for one git annex repository to configure a special remote that it makes sense for other repositories to also be able to use. Today I added the UI to support that; in the list of repositories, such repositories have a "enable" link.
To enable pre-existing rsync special remotes, the webapp has to do the same
probing and ssh key setup that it does when initially creating them.
Rsync.net is also handled as a special case in that code. There was one
ugly part to this.. When a rsync remote is configured in the webapp,
it uses a mangled hostname like "git-annex-example.com-user", to
make ssh use the key it sets up. That gets stored in the remote.log, and so
the enabling code has to unmangle it to get back to the real hostname.
Based on the still-running ?prioritizing special remotes poll, a lot of people want special remote support for their phone or mp3 player. (As opposed to running git-annex on an Android phone, which comes later..) It'd be easy enough to make the webapp set up a directory special remote on such a device, but that makes consuming some types of content on the phone difficult (mp3 players seem to handle them ok based on what people tell me). I need to think more about some of the ideas mentioned in android for more suitable ways of storing files.
One thing's for sure: You won't want the assistant to sync all your files to your phone! So I also need to start coming up with partial syncing controls. One idea is for each remote to have a configurable matcher for files it likes to receive. That could be only mp3 files, or all files inside a given subdirectory, or all files not in a given subdirectory. That means that when the assistant detects a file has been moved, it'll need to add (or remove) a queued transfer. Lots of other things could be matched on, like file size, number of copies, etc. Oh look, I have a beautiful library I wrote earlier that I can reuse!
I've changed the default backend used by git-annex from SHA256 to SHA256E. Including the filename extension in the key is known to make repositories more usable on things like MP3 players, and I've recently learned it also avoids Weird behavior with OS X Finder and Preview.app.
I thought about only changing the default in repositories set up by the assistant, but it seemed simpler to change the main default. The old backend is really only better if you might have multiple copies of files with the same content that have different extensions.
Fixed the socket leak in pairing that eluded me earlier.
I've made a new polls page, and posted a poll: prioritizing special remotes
Tons of pairing work, which culminated today in pairing fully working for the very first time. And it works great! Type something like "my hovercraft is full of eels" into two git annex webapps on the same LAN and the two will find each other, automatically set up ssh keys, and sync up, like magic. Magic based on math.
- Revert changes made to
authorized_keyswhen the user cancels a pairing response. Which could happen if the machine that sent the pairing request originally is no longer on the network. - Some fixes to handle lossy UDP better. Particularly tricky at the end of the conversation -- how do both sides reliably know when a conversation is over when it's over a lossy wire? My solution is just to remember some conversatons we think are over, and keep saying "this conversation is over" if we see messages in that conversation. Works.
- Added a UUID that must be the same in related pairing messages. This has a nice security feature: It allows detection of brute-force attacks to guess the shared secret, after the first wrong guess! In which case the pairing is canceled and a warning printed.
- That led to a thorough security overview, which I've added to the pairing page. Added some guards against unusual attacks, like console poisioning attacks. I feel happy with the security of pairing now, with the caveats that only I have reviewed it (and reviewing your own security designs is never ideal), and that the out-of-band shared secret communication between users is only as good as they make it.
- Found a bug in Yesod's type safe urls. At least, I think it's a bug. Worked around it.
- Got very stuck trying to close the sockets that are opened to send
multicast pairing messages. Nothing works, down to and including calling
C
close(). At the moment I have a socket leak.
I need to understand the details of multicast sockets better to fix this.
Emailed the author of the library I'm using for help.
Worked on pairing all day. It's complicated and I was close to being in the weeds at times. I think it probably works now, but I have not tested it at all. Tomorrow, testing, and cleaning up known problems.
Also ordered 1.5 terabytes of USB keys and a thousand git-annex stickers today.
Alerts can now have buttons, that go to some url when clicked. Yay.
Implementing that was a PITA, because Yesod really only wants its type-safe urls to be rendered from within its Handler monad. Which most things that create alerts are not. I managed to work around Yesod's insistence on this only by using a MVar to store the pure function that Yesod uses internally. That function can only be obtained once the webapp is running.
Fixed a nasty bug where using gpg would cause hangs. I introduced this back when I was reworking all the code in git-annex that runs processes, so it would work with threading. In the process a place that had forked a process to feed input to gpg was lost. Fixed it by spawning a thread to feed gpg. Luckily I have never released a version of git-annex with that bug, but the many users who are building from the master branch should update.
Made alerts be displayed while pairing is going on, with buttons to cancel pairing or respond to a pairing request.
About half way done with implementing pairing. The webapp's interface to prompt for a secret and start pairing is done; the protocol is implemented; broadcasting of pairing requests is working; added Yet Another Thread to listen for incoming pairing traffic.
Very happy with how this came together; starting with defining the protocol with data types let me rapidly iterate until I had designed a simple, clean, robust protocol. The implementation works well too; it's even possible to start pairing, and only then bring up the network interface to the machine you intended to pair with, and it'll detect the new interface and start sending requests to it.
Next, I need to make alerts have a button that performs a stored IO action. So that the incoming pair request alert can have a button to respond to the pair request. And then I need to write the code to actually perform the pairing, including ssh key setup.
Started reading about ZeroMQ with the hope that it could do some firewall traversal thing, to connect mutually-unroutable nodes. Well, it could, but it'd need a proxy to run on a server both can contact, and lots of users won't have a server to run that on. The XMPP approach used by dvcs-autosync is looking like the likeliest way for git-annex to handle that use case.
However, ZeroMQ did point in promising directions to handle another use case I need to support: Local pairing. In fairly short order, I got ZeroMQ working over IP Multicast (PGM), with multiple publishers sending messages that were all seen by multiple clients on the LAN (actually the WAN; works over OpenVPN too). I had been thinking about using Avahi/ZeroConf for discovery of systems to pair with, but ZeroMQ is rather more portable and easy to work with.
Unfortunatly, I wasn't able to get ZeroMQ to behave reliably enough.
It seems to have some timeout issues the way I'm trying to use it,
or perhaps its haskell bindings are buggy? Anyway, it's really overkill
to use PGM when all I need for git-annex pairing discovery is lossy
UDP Multicast. Haskell has a simple network-multicast library for that,
and it works great.
With discovery out of the way (theoretically), the hard part about pairing is going to be verifying that the desired repository is being paired with, and not some imposter. My plan to deal with this involves a shared secret, that can be communicated out of band, and HMAC. The webapp will prompt both parties to enter the same agreed upon secret (which could be any phrase, ideally with 64 bytes of entropy), and will then use it as the key for HMAC on the ssh public key. The digest will be sent over the wire, along with the ssh public key, and the other side can use the shared secret to verifiy the key is correct.
The other hard part about pairing will be finding the best address to use for git, etc to connect to the other host. If MDNS is available, it's ideal, but if not the pair may have to rely on local DNS, or even hard-coded IPs, which will be much less robust. Or, the assistant could broadcast queries for a peer's current IP address itself, as a poor man's MDNS.
All right then! That looks like a good week's worth of work to embark on.
Slight detour to package the haskell network-multicast library and upload to Debian unstable.
Roughed out a data type that models the whole pairing conversation, and can be serialized to implement it. And a state machine to run that conversation. Not yet hooked up to any transport such as multicast UDP.
- On OSX, install a launcher plist file, to run the assistant on login,
and a
git-annex-webapp.commandfile in the desktop. This is not tested yet. - Made the webapp display alerts when the inotify/kqueue layer has a warning message.
- Handle any crashes of each of the 15 or so named threads by displaying an alert. (Of course, this should never happen.)
Now finished building a special configurator for rsync.net. While this is just a rsync remote to git-annex, there are some tricky bits to setting up the ssh key using rsync.net's restricted shell. The configurator automates that nicely. It took about 3 hours of work, and 49 lines of rsync.net specific code to build this.
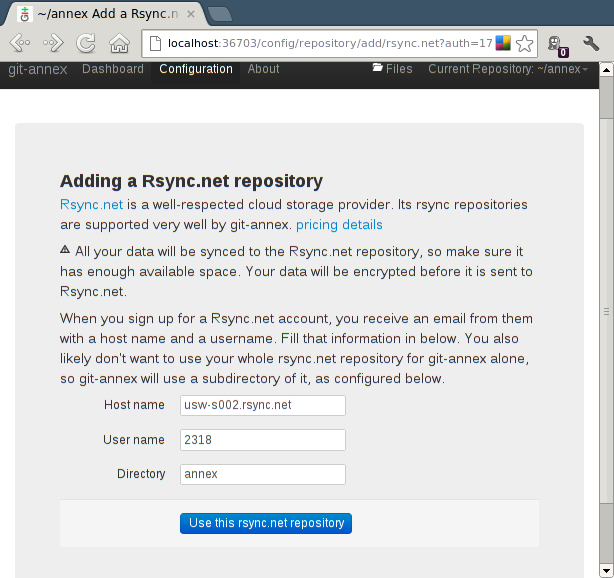
Thanks to rsync.net who heard of my Kickstarter and gave me a really nice free lifetime account. BTW guys, I wish your restricted shell supported '&&' in between commands, and returned a nonzero exit status when the command fails. This would make my error handling work better.
I've also reworked the repository management page. Nice to see those configurators start to fill in!
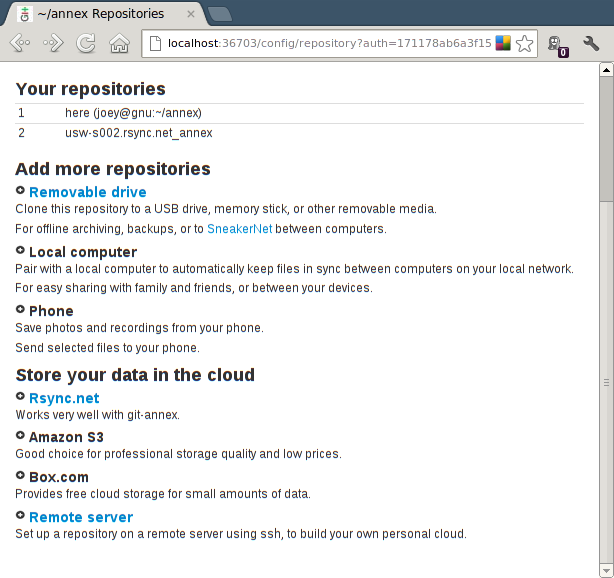
Decided to only make bare git repos on remote ssh servers. This configurator is aimed at using a server somewhere, which is probably not going to be running the assistant. So it doesn't need a non-bare repo, and there's nothing to keep the checked out branch in a non-bare repo up-to-date on such a server, anyway. For non-bare repos on locally accessible boxes, the pairing configurator will be the thing to use, instead of this one.
Note: While the remote ssh configurator works great, and you could even have the assistant running on multiple computers and use it to point them all at the same repo on a server, the assistant does not yet support keeping such a network topology in sync. That needs some of the ideas in cloud to happen, so clients can somehow inform each other when there are changes. Until that happens, the assistant polls only every 30 minutes, so it'll keep in sync with a 30 minute delay.
This configurator can also set up encryped rsync special remotes. Currently it always encrypts them, using the shared cipher mode of git-annex's encryption. That avoids issues with gpg key generation and distribution, and was easy to get working.
I feel I'm in a good place now WRT adding repository configurator wizards to the webapp. This one took about 2.5 days, and involved laying some groundwork that will be useful for other repository configurators. And it was probably one of the more complex ones.
Now I should be able to crank out configurators for things like Amazon S3, Bup, Rsync.net, etc fairly quickly. First, I need to do a beta release of the assistant, and start getting feedback from my backers to prioritize what to work on.
Got ssh probing implemented. It checks if it can connect to the server, and probes the server to see how it should be used.
Turned out to need two ssh probes. The first uses the system's existing ssh configuration, but disables password prompts. If that's able to get in without prompting for a password, then the user must have set that up, and doesn't want to be bothered with password prompts, and it'll respect that configuration.
Otherwise, it sets up a per-host ssh key, and configures a hostname alias
in ~/.ssh/config to use that key, and probes using that.
Configuring ssh this way is nice because it avoids changing ssh's
behavior except when git-annex uses it, and it does not open up the server
to arbitrary commands being run without password.
--
Next up will be creating the repositories. When there's a per-host key,
this will also involve setting up authorized_keys, locking down the ssh
key to only allow running git-annex-shell or rsync.
I decided to keep that separate from the ssh probing, even though it means the user will be prompted twice for their ssh password. It's cleaner and allows the probing to do other checks -- maybe it'll later check the amount of free disk space -- and the user should be able to decide after the probe whether or not to proceed with making the repository.
Today I built the UI in the webapp to set up a ssh or rsync remote.
This is the most generic type of remote, and so it's surely got the most complex description. I've tried to word it as clearly as I can; suggestions most appreciated. Perhaps I should put in a diagram?
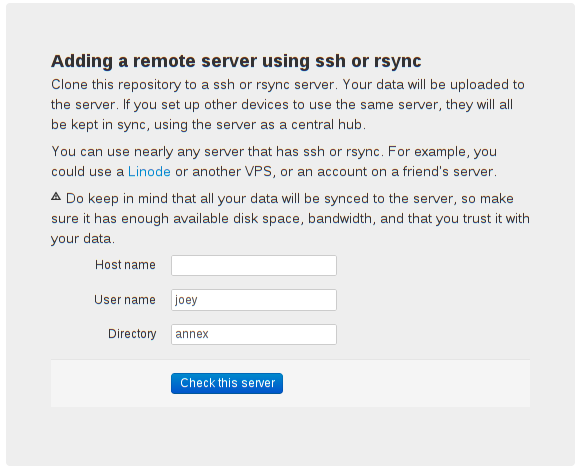
The idea is that this will probe the server, using ssh. If git-annex-shell
is available there, it'll go on to set up a full git remote. If not, it'll
fall back to setting up a rsync special remote. It'll even fall all the way
back to using rsync:// protocol if it can't connect by ssh. So the user
can just point it at a server and let it take care of the details,
generally.
The trickiest part of this will be authentication, of course. I'm relying
on ssh using ssh-askpass to prompt for any passwords, etc, when there's
no controlling terminal. But beyond passwords, this has to deal with ssh
keys.
I'm planning to make it check if you have a ssh key configured already. If you do, it doesn't touch your ssh configuration. I don't want to get in the way of people who have a manual configuration or are using MonkeySphere.
But for a user who has never set up a ssh key, it will prompt asking if
they'd like a key to be set up. If so, it'll generate a key and configure
ssh to only use it with the server.. and as part of its ssh probe, that key
will be added to authorized_keys.
(Obviously, advanced users can skip this entirely; git remote add
ssh://... still works..)
Also today, fixed more UI glitches in the transfer display. I think I have them all fixed now, except for the one that needs lots of javascript to be written to fix it.
Amusingly, while I was working on UI glitches, it turned out that all the fixes involved 100% pure code that has nothing to do with UI. The UI was actually just exposing bugs.
For example, closing a running transfer had a bug that weirdly reordered the queue. This turned out to be due to the transfer queue actually maintaining two versions of the queue, one in a TChan and one a list. Some unknown bugs caused these to get out of sync. That was fixed very handily by deleting the TChan, so there's only one copy of the data.
I had only been using that TChan because I wanted a way to block while the queue was empty. But now that I'm more comfortable with STM, I know how to do that easily using a list:
getQueuedTransfer q = atomically $ do
sz <- readTVar (queuesize q)
if sz < 1
then retry -- blocks until size changes
else ...
Ah, the times before STM were dark times indeed. I'm writing more and more STM code lately, building up more and more complicated and useful transactions. If you use threads and don't know about STM, it's a great thing to learn, to get out of the dark ages of dealing with priority inversions, deadlocks, and races.
Short day today.
- Worked on fixing a number of build failures people reported.
- Solved the problem that was making transfer pause/resume not always work. Although there is another bug where pausing a transfer sometimes lets another queued transfer start running.
- Worked on getting the assistant to start on login on OSX.
More work on the display and control of transfers.
- Hide redundant downloads from the transfer display. It seemed simplest to keep the behavior of queuing downloads from every remote that has a file, rather than going to some other data structure, but it's clutter to display those to the user, especially when you often have 7 copies of each file, like I do.
- When canceling a download, cancel all other queued downloads of that key too.
- Fixed unsettting of the paused flag when resuming a paused transfer.
- Implemented starting queued transfers by clicking on the start button.
- Spent a long time debugging why pausing, then resuming, and then pausing
a transfer doesn't successfully pause it the second time. I see where
the code is seemingly locking up in a
throwTo, but I don't understand why that blocks forever. Urgh..
Got the webapp's progress bars updating for downloads. Updated progressbars with all the options for ways to get progress info. For downloads, it currently uses the easy, and not very expensive, approach of periodically polling the sizes of files that are being downloaded.
For uploads, something more sophisticated will be called for..
The webapp really feels alive now that it has progress bars!
It's done! The assistant branch is merged into master.
Updated the assistant page with some screenshots and instructions for using it.
Made some cosmetic fixes to the webapp.
Fixed the transferrer to use ~/.config/git-annex/program
to find the path to git-annex when running it. (There are ways to find the
path of the currently running program in unux, but they all suck, so I'm
avoiding them this way.)
Read some OSX launchd documentation, and it seems it'd be pretty easy to get the assistant to autostart on login on OSX. If someone would like to test launchd files for me, get in touch.
AKA: Procrastinating really hard on those progress bars.
Almost done with the data transfer code.. Today I filled in some bits and peices.
Made the expensive transfer scan handle multiple remotes in one pass. So on startup, it only runs once, not N times. And when reconnecting to the network, when a remote has changed, it scans all network remotes in one pass, rather than making M redundant passes.
Got syncing with special remotes all working. Pretty easy actually. Just had to avoid doing any git repo push/pull with them, while still queueing data transfers.
It'll even download anything it can from the web special remote. To support that, I added generic support for readonly remotes; it'll only download from those and not try to upload to them.
(Oh, and I properly fixed the nasty GIT_INDEX_FILE environment variable
problem I had the other day.)
I feel I'm very close to being able to merge the assistant branch into master now. I'm reasonably confident the data transfer code will work well now, and manage to get things in sync eventually in all circumstances. (Unless there are bugs.) All the other core functionality of the assistant and webapp is working. The only think I might delay because of is the missing progressbars in the webapp .. but that's a silly thing to block the merge on.
Still, I might spend a day and get a dumb implementation of progress bars for downloads working first (progress bars for uploads are probably rather harder). I'd spend longer on progress bars, but there are so many more exciting things I'm now ready to develop, like automatic configurators for using your git annex with Amazon S3, rsync.net, and the computer across the room..!
Working toward getting the data syncing to happen robustly, so a bunch of improvements.
- Got unmount events to be noticed, so unplugging and replugging a removable drive will resume the syncing to it. There's really no good unmount event available on dbus in kde, so it uses a heuristic there.
- Avoid requeuing a download from a remote that no longer has a key.
- Run a full scan on startup, for multiple reasons, including dealing with crashes.
Ran into a strange issue: Occasionally the assistant will run git-annex
copy and it will not transfer the requested file. It seems that
when the copy command runs git ls-files, it does not see the file
it's supposed to act on in its output.
Eventually I figured out what's going on: When updating the git-annex
branch, it sets GIT_INDEX_FILE, and of course environment settings are
not thread-safe! So there's a race between threads that access
the git-annex branch, and the Transferrer thread, or any other thread
that might expect to look at the normal git index.
Unfortunatly, I don't have a fix for this yet.. Git's only interface for
using a different index file is GIT_INDEX_FILE. It seems I have a lot of
code to tear apart, to push back the setenv until after forking every git
command.
Before I figured out the root problem, I developed a workaround for the
symptom I was seeing. I added a git-annex transferkey, which is
optimised to be run by the assistant, and avoids running git ls-files, so
avoids the problem. While I plan to fix this environment variable problem
properly, transferkey turns out to be so much faster than how it was
using copy that I'm going to keep it.
Implemented everything I planned out yesterday: Expensive scans are only done once per remote (unless the remote changed while it was disconnected), and failed transfers are logged so they can be retried later.
Changed the TransferScanner to prefer to scan low cost remotes first, as a crude form of scheduling lower-cost transfers first.
A whole bunch of interesting syncing scenarios should work now. I have not tested them all in detail, but to the best of my knowledge, all these should work:
- Connect to the network. It starts syncing with a networked remote. Disconnect the network. Reconnect, and it resumes where it left off.
- Migrate between networks (ie, home to cafe to work). Any transfers that can only happen on one LAN are retried on each new network you visit, until they succeed.
One that is not working, but is soooo close:
- Plug in a removable drive. Some transfers start. Yank the plug. Plug it back in. All necessary transfers resume, and it ends up fully in sync, no matter how many times you yank that cable.
That's not working because of an infelicity in the MountWatcher. It doesn't notice when the drive gets unmounted, so it ignores the new mount event.
Woke up this morning with most of the design for a smarter approach to syncing in my head. (This is why I sometimes slip up and tell people I work on this project 12 hours a day..)
To keep the current assistant branch working while I make changes
that break use cases that are working, I've started
developing in a new branch, assistant-wip.
In it, I've started getting rid of unnecessary expensive transfer scans.
First optimisation I've done is to detect when a remote that was
disconnected has diverged its git-annex branch from the local branch.
Only when that's the case does a new transfer scan need to be done, to find
out what new stuff might be available on that remote, to have caused the
change to its branch, while it was disconnected.
That broke a lot of stuff. I have a plan to fix it written down in syncing. It'll involve keeping track of whether a transfer scan has ever been done (if not, one should be run), and recording logs when transfers failed, so those failed transfers can be retried when the remote gets reconnected.
Today, added a thread that deals with recovering when there's been a loss of network connectivity. When the network's down, the normal immediate syncing of changes of course doesn't work. So this thread detects when the network comes back up, and does a pull+push to network remotes, and triggers scanning for file content that needs to be transferred.
I used dbus again, to detect events generated by both network-manager and wicd when they've sucessfully brought an interface up. Or, if they're not available, it polls every 30 minutes.
When the network comes up, in addition to the git pull+push, it also currently does a full scan of the repo to find files whose contents need to be transferred to get fully back into sync.
I think it'll be ok for some git pulls and pushes to happen when moving to a new network, or resuming a laptop (or every 30 minutes when resorting to polling). But the transfer scan is currently really too heavy to be appropriate to do every time in those situations. I have an idea for avoiding that scan when the remote's git-annex branch has not changed. But I need to refine it, to handle cases like this:
- a new remote is added
- file contents start being transferred to (or from it)
- the network is taken down
- all the queued transfers fail
- the network comes back up
- the transfer scan needs to know the remote was not all in sync before #3, and so should do a full scan despite the git-annex branch not having changed
Doubled the ram in my netbook, which I use for all development. Yesod needs rather a lot of ram to compile and link, and this should make me quite a lot more productive. I was struggling with OOM killing bits of chromium during my last week of development.
As I prepare to dive back into development, now is a good time to review what I've built so far, and how well I'm keeping up with my planned roadmap.
I started working two and a half months ago, so am nearing the end of the three months I originally asked to be funded for on Kickstarter.
I've built much of what I planned to build in the first three months -- inotify is done (and kqueue is basically working, but needs scalability work), local syncing is done, the webapp works, and I've built some of the first configurators. It's all functional in a narrow use case involving syncing to removable drives.
progressbars still need to be dealt with, and network syncing needs to be revisited soon, so that I can start building easy configurators for further use cases, like using the cloud, or another machine on the local network.
I think I'm a little behind my original schedule, but not too bad, and at the same time, I think I've built things rather more solidly than I expected them to be at this point. I'm particularly happy with how well the inotify code works, no matter what is thrown at it, and how nice the UI in the webapp is shaping up to be.
I also need to get started on fulfilling my Kickstarter rewards, and I was happy to spend some time in the airport working on the main blocker toward that, a lack of a scalable git-annex logo, which is needed for printing on swag.
Turns out that inkscape has some amazing bitmap tracing capabilities. I was able to come up with this scalable logo in short order, it actually took longer to add back the colors, as the tracer generated a black and white version.
With that roadblock out of the way, I am moving toward ordering large quantities of usb drives, etc.
![]()
Actually did do some work on the webapp today, just fixing a bug I noticed in a spare moment. Also managed a bit in the plane earlier this week, implementing resuming of paused transfers. (Still need to test that.)
But the big thing today was dinner with one of my major Kickstarter backers, and as it turned out, "half the Haskell community of San Francisco" (3 people). Enjoyed talking about git-annex and haskell with them.
I'm looking forward to getting back home and back to work on Monday..
Unexpectedly managed a mostly productive day today.
Went ahead with making the assistant run separate git-annex processes for
transfers. This will currently fail if git-annex is not installed in PATH.
(Deferred dealing with that.)
To stop a transfer, the webapp needs to signal not just the git-annex process, but all its children. I'm using process groups for this, which is working, but I'm not extremely happy with.
Anyway, the webapp's UI can now be used for stopping transfers, and it wasn't far from there to also implementing pausing of transfers.
Pausing a transfer is actually the same as stopping it, except a special signal is sent to the transfer control thread, which keeps running, despite the git-annex process having been killed, waits for a special resume signal, and restarts the transfer. This way a paused transfer continues to occupy a transfer slot, which prevents other queued transfers from running. This seems to be the behavior that makes sense.
Still need to wire up the webapp's button for starting a transfer. For a paused transfer, that will just need to resume it. I have not decided what the button should do when used on a transfer that is queued but not running yet. Maybe it forces it to run even if all transfer slots are already in use? Maybe it stops one of the currently running transfers to free up a slot?
Probably won't be doing any big coding on the git-annex assistant in the upcoming week, as I'll be traveling and/or slightly ill enough that I can't fully get into flow.
There was a new Yesod release this week, which required minor changes to make the webapp build with it. I managed to keep the old version of Yesod also supported, and plan to keep that working so it can be built with the version of Yesod available in, eg, Linux distributions. TBD how much pain that will involve going forward.
I'm mulling over how to support stopping/pausing transfers. The problem is that if the assistant is running a transfer in one thread, and the webapp is used to cancel it, killing that thread won't necessarily stop the transfer, because, at least in Haskell's thread model, killing a thread does not kill processes started by the thread (like rsync).
So one option is to have the transfer thread run a separate git-annex process, which will run the actual transfer. And killing that process will stop the transfer nicely. However, using a separate git-annex process means a little startup overhead for each file transferred (I don't know if it'd be enough to matter). Also, there's the problem that git-annex is sometimes not installed in PATH (wish I understood why cabal does that), which makes it kind of hard for it to run itself. (It can't simply fork, sadly. See past horrible pain with forking and threads.)
The other option is to change the API for git-annex remotes, so that
their storeKey and retrieveKeyFile methods return a pid of the program
that they run. When they do run a program.. not all remotes do. This
seems like it'd make the code in the remotes hairier, and it is also asking
for bugs, when a remote's implementation changes. Or I could go
lower-level, and make every place in the utility libraries that forks a
process record its pid in a per-thread MVar. Still seems to be asking for
bugs.
Oh well, at least git-annex is already crash-safe, so once I figure out
how to kill a transfer process, I can kill it safely.
A bit under the weather, but got into building buttons to control running and queued transfers today. The html and javascript side is done, with each transfer now having a cancel button, as well as a pause/start button.
Canceling queued transfers works. Canceling running transfers will need some more work, because killing a thread doesn't kill the processes being run by that thread. So I'll have to make the assistant run separate git-annex processes for transfers, that can be individually sent signals.
Nothing flashy today; I was up all night trying to download photos taken by a robot lowered onto Mars by a skycrane.
Some work on alerts. Added an alert when a file transfer succeeds or fails. Improved the alert combining code so it handles those alerts, and simplified it a lot, and made it more efficient.
Also made the text of action alerts change from present to past tense when
the action finishes. To support that I wrote a fun data type, a TenseString
that can be rendered in either tense.
Spent yesterday and today making the WebApp handle adding removable drives.
While it needs more testing, I think that it's now possible to use the WebApp for a complete sneakernet usage scenario.
- Start up the webapp, let it make a local repo.
- Add some files, by clicking to open the file manager, and dragging them in.
- Plug in a drive, and tell the webapp to add it.
- Wait while files sync..
- Take the drive to another computer, and repeat the process there.
No command-line needed, and files will automatically be synced between two or more computers using the drive.
Sneakernet is only one usage scenario for the git-annex assistant, but I'm really happy to have one scenario 100% working!
Indeed, since the assistant and webapp can now actually do something
useful, I'll probably be merging them into master soon.
Details follow..
So, yesterday's part of this was building the configuration page to add a removable drive. That needs to be as simple as possible, and it currently consists of a list of things git-annex thinks might be mount points of removable drives, along with how much free space they have. Pick a drive, click the pretty button, and away it goes..
(I decided to make the page so simple it doesn't even ask where you want to put the directory on the removable drive. It always puts it in a "annex" directory. I might add an expert screen later, but experts can always set this up themselves at the command line too.)
I also fought with Yesod and Bootstrap rather a lot to make the form look good. Didn't entirely succeed, and had to file a bug on Yesod about its handling of check boxes. (Bootstrap also has a bug, IMHO; its drop down lists are not always sized wide enough for their contents.)
Ideally this configuration page would listen for mount events, and refresh its list. I may add that eventually; I didn't have a handy channel it could use to do that, so defferred it. Another idea is to have the mount event listener detect removable drives that don't have an annex on them yet, and pop up an alert with a link to this configuration page.
Making the form led to a somewhat interesting problem: How to tell if a mounted
filesystem is a removable drive, or some random thing like /proc or
a fuse filesystem. My answer, besides checking that the user can
write to it, was various heuristics, which seem to work ok, at least here..
sane Mntent { mnt_dir = dir, mnt_fsname = dev }
{- We want real disks like /dev/foo, not
- dummy mount points like proc or tmpfs or
- gvfs-fuse-daemon. -}
| not ('/' `elem` dev) = False
{- Just in case: These mount points are surely not
- removable disks. -}
| dir == "/" = False
| dir == "/tmp" = False
| dir == "/run/shm" = False
| dir == "/run/lock" = False
Today I did all the gritty coding to make it create a git repository on the removable drive, and tell the Annex monad about it, and ensure it gets synced.
As part of that, it detects when the removable drive's filesystem doesn't support symlinks, and makes a bare repository in that case. Another expert level config option that's left out for now is to always make a bare repository, or even to make a directory special remote rather than a git repository at all. (But directory special remotes cannot support the sneakernet use case by themselves...)
Another somewhat interesting problem was what to call the git remotes that it sets up on the removable drive and the local repository. Again this could have an expert-level configuration, but the defaults I chose are to use the hostname as the remote name on the removable drive, and to use the basename of the mount point of the removable drive as the remote name in the local annex.
Originally, I had thought of this as cloning the repository to the drive.
But, partly due to luck, I started out just doing a git init to make
the repository (I had a function lying around to do that..).
And as I worked on it some more, I realized this is not as simple as a clone. It's a bi-directional sync/merge, and indeed the removable drive may have all the data already in it, and the local repository have just been created. Handling all the edge cases of that (like, the local repository may not have a "master" branch yet..) was fun!
Today I added a "Files" link in the navbar of the WebApp. It looks like a regular hyperlink, but clicking on it opens up your desktop's native file manager, to manage the files in the repository!
Quite fun to be able to do this kind of thing from a web page.
Made git annex init (and the WebApp) automatically generate a description
of the repo when none is provided.
Also worked on the configuration pages some. I don't want to get ahead of myself by diving into the full configuration stage yet, but I am at least going to add a configuration screen to clone the repo to a removable drive.
After that, the list of transfers on the dashboard needs some love. I'll probably start by adding UI to cancel running transfers, and then try to get drag and drop reordering of transfers working.
Now installing git-annex automatically generates a freedesktop.org .desktop
file, and installs it, either system-wide (root) or locally (user). So
Menu -> Internet -> Git Annex will start up the web app.
(I don't entirely like putting it on the Internet menu, but the Accessories menu is not any better (and much more crowded here), and there's really no menu where it entirely fits.)
I generated that file by writing a generic library to deal with freedesktop.org desktop files and locations. Which seemed like overkill at the time, but then I found myself continuing to use that library. Funny how that happens.
So, there's also another .desktop file that's used to autostart the
git-annex assistant daemon when the user logs into the desktop.
This even works when git-annex is installed to the ugly non-PATH location
.cabal/bin/git-annex by Cabal! To make that work, it records the path
the binary is at to a freedesktop.org data file, at install time.
That should all work in Gnome, KDE, XFCE, etc. Not Mac OSX I'm guessing...
Also today, I added a sidebar notification when the assistant notices new files. To make that work well, I implemented merging of related sidebar action notifications, so the effect is that there's one notification that collectes a list of recently added files, and transient notifications that show up if a really big file is taking a while to checksum.
I'm pleased that the notification interface is at a point where I was able to implement all that, entirely in pure functional code.
Based on the results of yesterday's poll, the WebApp defaults to
~/Desktop/annex when run in the home directory. If there's no Desktop
directory, it uses just ~/annex. And if run from some other place than
the home directory, it assumes you want to use cwd. Of course, you can
change this default, but I think it's a good one for most use cases.
My work today has all been on making one second of the total lifetime
of the WebApp work. It's the very tricky second in between clicking on
"Make repository" and being redirected to a WebApp running in your new
repository. The trickiness involves threads, and MVars, and
multiple web servers, and I don't want to go into details here.
I'd rather forget.
Anyway, it works; you can run "git annex webapp" and be walked right
through to having a usable repository! Now I need to see about adding
that to the desktop menus, and making "git annex webapp", when run a second
time, remembering where your repository is. I'll use
~/.config/git-annex/repository for storing that.
Started work on the interface displayed when the webapp is started with no existing git-annex repository. All this needs to do is walk the user through setting up a repository, as simply as possible.
A tricky part of this is that most of git-annex runs in the Annex monad, which requires a git-annex repository. Luckily, much of the webapp does not run in Annex, and it was pretty easy to work around the parts that do. Dodged a bullet there.
There will, however, be a tricky transition from this first run webapp, to a normally fully running git-annex assistant and webapp. I think the first webapp will have to start up all the normal threads once it makes the repository, and then redirect the user's web browser to the full webapp.
Anyway, the UI I've made is very simple: A single prompt, for the directory where the repository should go. With, eventually, tab completion, sanity checking (putting the repository in "/" is not good, and making it all of "$HOME" is probably unwise).
Ideally most users will accept the default, which will be something
like /home/username/Desktop/Annex, and be through this step in seconds.
Suggestions for a good default directory name appreciated.. Putting it on a folder that will appear on the desktop seems like a good idea, when there's a Desktop directory. I'm unsure if I should name it something specific like "GitAnnex", or something generic like "Synced".
Time for the first of probably many polls!
What should the default directory name used by the git-annex assistant be?
Annex (38%)
GitAnnex (14%)
~/git-annex/ (2%)
Synced (20%)
AutoSynced (0%)
Shared (2%)
something lowercase! (20%)
CowboyNeal (2%)
Annexbox (2%)
Total votes: 50
(Note: This is a wiki. You can edit this page to add your own poll options!)
Lots of WebApp UI improvements, mostly around the behavior when displaying alert messages. Trying to make the alerts informative without being intrusively annoying, think I've mostly succeeded now.
Also, added an intro display. Shown is the display with only one repo; if there are more repos it also lists them all.
Some days I spend 2 hours chasing red herrings (like "perhaps my JSON ajax calls arn't running asynchronoously?") that turn out to be a simple one-word typo. This was one of them.
However, I did get the sidebar displaying alert messages, which can be easily sent to the user from any part of the assistant. This includes transient alerts of things it's doing, which disappear once the action finishes, and long-term alerts that are displayed until the user closes them. It even supports rendering arbitrary Yesod widgets as alerts, so they can also be used for asking questions, etc.
Time for a screencast!
Focus today was writing a notification broadcaster library. This is a way to send a notification to a set of clients, any of which can be blocked waiting for a new notification to arrive. A complication is that any number of clients may be be dead, and we don't want stale notifications for those clients to pile up and leak memory.
It took me 3 tries to find the solution, which turns out to be head-smackingly simple: An array of SampleVars, one per client.
Using SampleVars means that clients only see the most recent notification, but when the notification is just "the assistant's state changed somehow; display a refreshed rendering of it", that's sufficient.
First use of that was to make the thread that woke up every 10 minutes and checkpointed the daemon status to disk also wait for a notification that it changed. So that'll be more current, and use less IO.
Second use, of course, was to make the WebApp block long polling clients until there is really a change since the last time the client polled.
To do that, I made one change to my Yesod routes:
-/status StatusR GET
+/status/#NotificationId StatusR GET
Now I find another reason to love Yesod, because after doing that,
I hit "make".. and fixed the type error. And hit make.. and fixed
the type error. And then it just freaking worked! Html was generated with
all urls to /status including a NotificationId, and the handler for
that route got it and was able to use it:
{- Block until there is an updated status to display. -}
b <- liftIO $ getNotificationBroadcaster webapp
liftIO $ waitNotification $ notificationHandleFromId b nid
And now the WebApp is able to display transfers in realtime!
When I have both the WebApp and git annex get running on the same screen,
the WebApp displays files that git-annex is transferring about as fast
as the terminal updates.
The progressbars still need to be sorted out, but otherwise the WebApp is a nice live view of file transfers.
I also had some fun with Software Transactional Memory. Now when the assistant moves a transfer from its queue of transfers to do, to its map of transfers that are currently running, it does so in an atomic transaction. This will avoid the transfer seeming to go missing (or be listed twice) if the webapp refreshes at just the wrong point in time. I'm really starting to get into STM.
Next up, I will be making the WebApp maintain a list of notices, displayed on its sidebar, scrolling new notices into view, and removing ones the user closes, and ones that expire. This will be used for displaying errors, as well as other communication with the user (such as displaying a notice while a git sync is in progress with a remote, etc). Seems worth doing now, so the basic UI of the WebApp is complete with no placeholders.
The webapp now displays actual progress bars, for the actual transfers that the assistant is making! And it's seriously shiny.
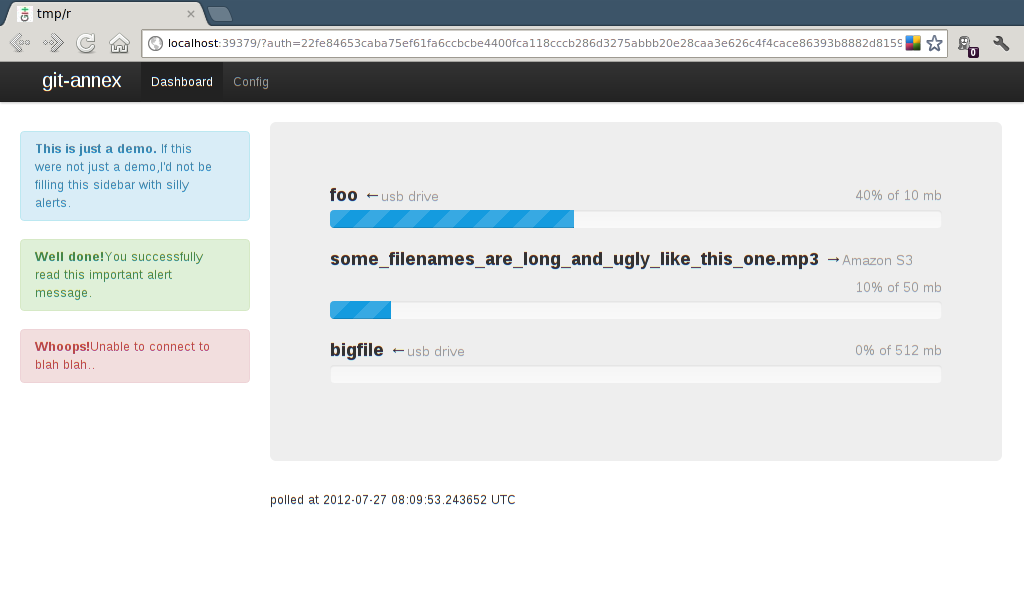
Yes, I used Bootstrap. I can see why so many people are using it, that the common complaint is everything looks the same. I spent a few hours mocking up the transfer display part of the WebApp using Bootstrap, and arrived at something that doesn't entirely suck remarkably quickly.
The really sweet thing about Bootstrap is that when I resized my browser to the shape of a cell phone, it magically redrew the WebApp like so:
To update the display, the WebApp uses two techniques. On noscript browsers, it just uses a meta refresh, which is about the best I can do. I welcome feedback; it might be better to just have an "Update" button in this case.
With javascript enabled, it uses long polling, done over AJAX. There are some other options I considered, including websockets, and server-sent events. Websockets seem too new, and while there's a WAI module supporting server-sent events, and even an example of them in the Yesod book, the module is not packaged for Debian yet. Anyway, long polling is the most widely supported, so a good starting place. It seems to work fine too, I don't really anticipate needing the more sophisticated methods.
(Incidentially, this's the first time I've ever written code that uses AJAX.)
Currently the status display is rendered in html by the web server, and just updated into place by javascript. I like this approach since it keeps the javascript code to a minimum and the pure haskell code to a maximum. But who knows, I may have to switch to JSON that gets rendered by javascript, for some reason, later on.
I was very happy with Yesod when I managed to factor out a general purpose widget that adds long-polling and meta-refresh to any other widget. I was less happy with Yesod when I tried to include jquery on my static site and it kept serving up a truncated version of it. Eventually worked around what's seemingly a bug in the default WAI middleware, by disabling that middleware.
Also yesterday I realized there were about 30 comments stuck in moderation on this website. I thought I had a feed of those, but obviously I didn't. I've posted them all, and also read them all.
Next up is probably some cleanup of bugs and minor todos. Including
figuring out why watch has started to segfault on OSX when it was
working fine before.
After that, I need to build a way to block the long polling request until the DaemonStatus and/or TransferQueue change from the version previously displayed by the WebApp. An interesting concurrency problem..
Once I have that working, I can reduce the current 3 second delay between refreshes to a very short delay, and the WebApp will update in near-realtime as changes come in.
After an all-nighter, I have git annex webapp launching a WebApp!
It doesn't do anything useful yet, just uses Yesod to display a couple of hyperlinked pages and a favicon, securely.
The binary size grew rather alarmingly, BTW. Indeed, it's been growing
for months..
-rwxr-xr-x 1 root root 9.4M Jul 21 16:59 git-annex-no-assistant-stripped
-rwxr-xr-x 1 joey joey 12M Jul 25 20:54 git-annex-no-webapp-stripped
-rwxr-xr-x 1 joey joey 17M Jul 25 20:52 git-annex-with-webapp-stripped
Along the way, some Not Invented Here occurred:
I didn't use the yesod scaffolded site, because it's a lot of what seems mostly to be cruft in this use case. And because I don't like code generated from templates that people are then expected to edit. Ugh. That's my least favorite part of Yesod. This added some pain, since I had to do everything the hard way.
I didn't use wai-handler-launch because:
- It seems broken on IPv6 capable machines (it always opens
http://127.0.0.1:port/even though it apparently doesn't always listen there.. I think it was listening on my machine's ipv6 address instead. I know, I know; I should file a bug about this..) - It always uses port 4587, which is insane. What if you have two webapps?
- It requires javascript in the web browser, which is used to ping the server, and shut it down when the web browser closes (which behavior is wrong for git-annex anyway, since the daemon should stay running across browser closes).
- It opens the webapp on web server startup, which is wrong for git-annex;
instead the command
git annex webappwill open the webapp, aftergit annex assistantstarted the web server.
Instead, I rolled my own WAI webapp laucher, that binds to any free port
on localhost, It does use xdg-open to launch the web browser,
like wai-handler-launch (or just open on OS X).
Also, I wrote my own WAI logger, which logs using System.Log.Logger,
instead of to stdout, like runDebug does.
The webapp only listens for connections from localhost, but that's
not sufficient "security". Instead, I added a secret token to
every url in the webapp, that only git annex webapp knows about.
But, if that token is passed to xdg-open on its command line,
it will be briefly visible to local attackers in the parameters of
xdg-open.. And if the web browser's not already running, it'll run
with it as a parameter, and be very visible.
So instead, I used a nasty hack. On startup, the assistant
will create a html file, readably only by the user, that redirects
the user to the real site url. Then git annex webapp will run
xdg-open on that file.
Making Yesod check the auth= parameter (to verify that the secret token
is right) is when using Yesod started to pay off. Yesod has a simple
isAuthorized method that can be overridden to do your own authentication
like this.
But Yesod really started to shine when I went to add the auth= parameter
to every url in the webapp. There's a joinPath method can can be used
to override the default url builder. And every type-safe url in the
application goes through there, so it's perfect for this.
I just had to be careful to make it not add auth= to the url for the
favicon, which is included in the "Permission Denied" error page. That'd be
an amusing security hole..
Next up: Doing some AJAX to get a dynamic view of the state of the daemon,
including currently running transfers, in the webapp. AKA stuff I've never
done before, and that, unlike all this heavy Haskell Yesod, scares me.
Milestone: I can run git annex assistant, plug in a USB drive, and it
automatically transfers files to get the USB drive and current repo back in
sync.
I decided to implement the naive scan, to find files needing to be
transferred. So it walks through git ls-files and checks each file
in turn. I've deferred less expensive, more sophisticated approaches to later.
I did some work on the TransferQueue, which now keeps track of the length of the queue, and can block attempts to add Transfers to it if it gets too long. This was a nice use of STM, which let me implement that without using any locking.
atomically $ do
sz <- readTVar (queuesize q)
if sz <= wantsz
then enqueue schedule q t (stubInfo f remote)
else retry -- blocks until queuesize changes
Anyway, the point was that, as the scan finds Transfers to do, it doesn't build up a really long TransferQueue, but instead is blocked from running further until some of the files get transferred. The resulting interleaving of the scan thread with transfer threads means that transfers start fairly quickly upon a USB drive being plugged in, and kind of hides the innefficiencies of the scanner, which will most of the time be swamped out by the IO bound large data transfers.
At this point, the assistant should do a good job of keeping repositories in sync, as long as they're all interconnected, or on removable media like USB drives. There's lots more work to be done to handle use cases where repositories are not well-connected, but since the assistant's syncing now covers at least a couple of use cases, I'm ready to move on to the next phase. Webapp, here we come!
Made the MountWatcher update state for remotes located in a drive that gets mounted. This was tricky code. First I had to make remotes declare when they're located in a local directory. Then it has to rescan git configs of git remotes (because the git repo mounted at a mount point may change), and update all the state that a newly available remote can affect.
And it works: I plug in a drive containing one of my git remotes, and the assistant automatically notices it and syncs the git repositories.
But, data isn't transferred yet. When a disconnected remote becomes connected, keys should be transferred in both directions to get back into sync.
To that end, added Yet Another Thread; the TransferScanner thread will scan newly available remotes to find keys, and queue low priority transfers to get them fully in sync.
(Later, this will probably also be used for network remotes that become available when moving between networks. I think network-manager sends dbus events it could use..)
This new thread is missing a crucial peice, it doesn't yet have a way to find the keys that need to be transferred. Doing that efficiently (without scanning the whole git working copy) is Hard. I'm considering design possibilities..
I made the MountWatcher only use dbus if it sees a client connected to dbus that it knows will send mount events, or if it can start up such a client via dbus. (Fancy!) Otherwise it falls back to polling. This should be enough to support users who manually mount things -- if they have gvfs installed, it'll be used to detect their manual mounts, even when a desktop is not running, and if they don't have gvfs, they get polling.
Also, I got the MountWatcher to work with KDE. Found a dbus event that's
emitted when KDE mounts a drive, and this is also used. If anyone with
some other desktop environment wants me to add support for it, and it uses
dbus, it should be easy: Run dbus-monitor, plug in a drive, get
it mounted, and send me a transcript.
Of course, it'd also be nice to support anything similar on OSX that can provide mount event notifications. Not a priority though, since the polling code will work.
Some OS X fixes today..
- Jimmy pointed out that my
getmntentcode broke the build on OSX again. Sorry about that.. I keep thinking Unix portability nightmares are a 80's thing, not a 2010's thing. Anyway, adapted a lot of hackish C code to emulategetmntenton BSD systems, and it seems to work. (I actually think the BSD interface to this is saner than Linux's, but I'd rather have either one than both, sigh..) - Kqueue was blocking all the threads on OSX. This is fixed, and the assistant seems to be working on OSX again.
I put together a preliminary page thanking everyone who contributed to the git-annex Kickstarter. thanks The wall-o-names is scary crazy humbling.
Improved --debug mode for the assistant, now every thread says whenever
it's doing anything interesting, and also there are timestamps.
Had been meaning to get on with syncing to drives when they're mounted, but got sidetracked with the above. Maybe tomorrow. I did think through it in some detail as I was waking up this morning, and think I have a pretty good handle on it.
Really productive day today, now that I'm out of the threaded runtime tarpit!
First, brought back --debug logging, better than before! As part of that, I
wrote some 250 lines of code to provide a IMHO more pleasant interface to
System.Process (itself only 650 lines of code) that avoids all the
low-level setup, cleanup, and tuple unpacking. Now I can do things like
write to a pipe to a process, and ensure it exits nonzero, this easily:
withHandle StdinHandle createProcessSuccess (proc "git" ["hash-object", "--stdin"]) $ \h ->
hHutStr h objectdata
My interface also makes it easy to run nasty background processes, reading their output lazily.
lazystring <- withHandle StdoutHandle createBackgroundProcess (proc "find" ["/"]) hGetContents
Any true Haskellers are shuddering here, I really should be using conduits or pipes, or something. One day..
The assistant needs to detect when removable drives are attached, and sync with them. This is a reasonable thing to be working on at this point, because it'll make the currently incomplete data transfer code fully usable for the sneakernet use case, and firming that up will probably be a good step toward handing other use cases involving data transfer over the network, including cases where network remotes are transientely available.
So I've been playing with using dbus to detect mount events. There's a very nice Haskell library to use dbus.
This simple program will detect removable drives being mounted, and works on Xfce (as long as you have automounting enabled in its configuration), and should also work on Gnome, and, probably, KDE:
{-# LANGUAGE OverloadedStrings #-}
import Data.List (sort)
import DBus
import DBus.Client
import Control.Monad
main = do
client <- connectSession
listen client mountadded $ \s ->
putStrLn (show s)
forever $ getLine -- let listener thread run forever
where
mountadded = matchAny
{ matchInterface = Just "org.gtk.Private.RemoteVolumeMonitor"
, matchMember = Just "MountAdded"
}
(Yeah... "org.gtk.Private.RemoteVolumeMonitor". There are so
many things wrong with that string. What does gtk have to do with
mounting a drive? Why is it Private? Bleagh. Should I only match
the "MountAdded" member and not the interface? Seems everyone who does
this relies on google to find other people who have cargo-culted it,
or just runs dbus-monitor and picks out things.
There seems to be no canonical list of events. Bleagh.)
Spent a while shaving a yak of needing a getmntent interface in Haskell.
Found one in a hsshellscript library; since that library is not packaged
in Debian, and I don't really want to depend on it, I extracted just
the mtab and fstab parts of it into a little library in git-annex.
I've started putting together a MountWatcher thread. On systems without
dbus (do OSX or the BSDs have dbus?), or if dbus is not running, it polls
/etc/mtab every 10 seconds for new mounts. When dbus is available,
it doesn't need the polling, and should notice mounts more quickly.
Open question: Should it still poll even when dbus is available? Some of us
like to mount our own drives, by hand and may have automounting disabled. It'd
be good if the assistant supported that. This might need a
annex.no-dbus setting, but I'd rather avoid needing such manual
configuration.
One idea is to do polling in addition to dbus, if /etc/fstab contains
mount points that seem to be removable drives, on which git remotes lives.
Or it could always do polling in addition to dbus, which is just some extra
work. Or, it could try to introspect dbus to see if mount events will
be generated.
The MountWatcher so far only detects new mounts and prints out what happened. Next up: Do something in response to them.
This will involve manipulating the Annex state to belatedly add the Remote on the mount point.. tricky. And then, for Git Remotes, it should pull/push the Remote to sync git data. Finally, for all remotes, it will need to queue Transfers of file contents from/to the newly available Remote.
Beating my head against the threaded runtime some more. I can reproduce
one of the hangs consistently by running 1000 git annex add commands
in a loop. It hangs around 1% of the time, reading from git cat-file.
Interestingly, git cat-file is not yet running at this point --
git-annex has forked a child process, but the child has not yet exec'd it.
Stracing the child git-annex, I see it stuck in a futex. Adding tracing,
I see the child never manages to run any code at all.
This really looks like the problem is once again in MissingH, which uses
forkProcess. Which happens to come with a big warning about being very
unsafe, in very subtle ways. Looking at the C code that the newer process
library uses when sparning a pipe to a process, it messes around with lots of
things; blocking signals, stopping a timer, etc. Hundreds of lines of C
code to safely start a child process, all doing things that MissingH omits.
That's the second time I've seemingly isolated a hang in the GHC threaded runtime to MissingH.
And so I've started converting git-annex to use the new process library,
for running all its external commands. John Goerzen had mentioned process
to me once before when I found a nasty bug in MissingH, as the cool new
thing that would probably eliminate the System.Cmd.Utils part of MissingH,
but I'd not otherwise heard much about it. (It also seems to have the
benefit of supporting Windows.)
This is a big change and it's early days, but each time I see a hang, I'm
converting the code to use process, and so far the hangs have just gone
away when I do that.
Hours later... I've converted all of git-annex to use process.
In the er, process, the --debug switch stopped printing all the commands
it runs. I may try to restore that later.
I've not tested everything, but the test suite passes, even when using the threaded runtime. MILESTONE
Looking forward to getting out of these weeds and back to useful work..
Hours later yet.... The assistant branch in git now uses the threaded
runtime. It works beautifully, using proper threads to run file transfers
in.
That should fix the problem I was seeing on OSX yesterday. Too tired to test it now.
--
Amazingly, all the assistant's own dozen or so threads and thread synch variables etc all work great under the threaded runtime. I had assumed I'd see yet more concurrency problems there when switching to it, but it all looks good. (Or whatever problems there are are subtle ones?)
I'm very relieved. The threaded logjam is broken! I had been getting increasingly worried that not having the threaded runtime available would make it very difficult to make the assistant perform really well, and cause problems with the webapp, perhaps preventing me from using Yesod.
Now it looks like smooth sailing ahead. Still some hard problems, but it feels like with inotify and kqueue and the threaded runtime all dealt with, the really hard infrastructure-level problems are behind me.
Back home and laptop is fixed.. back to work.
Warmup exercises:
Went in to make it queue transfers when a broken symlink is received, only to find I'd already written code to do that, and forgotten about it. Heh. Did check that the git-annex branch is always sent first, which will ensure that code always knows where to transfer a key from. I had probably not considered this wrinkle when first writing the code; it worked by accident.
Made the assistant check that a remote is known to have a key before queueing a download from it.
Fixed a bad interaction between the
git annex mapcommand and the assistant.
Tried using a modified version of MissingH that doesn't use HSLogger
to make git-annex work with the threaded GHC runtime. Unfortunatly,
I am still seeing hangs in at least 3 separate code paths when
running the test suite. I may have managed to fix one of the hangs,
but have not grokked what's causing the others.
I now have access to a Mac OSX system, thanks to Kevin M. I've fixed some portability problems in git-annex with it before, but today I tested the assistant on it:
Found a problem with the kqueue code that prevents incoming pushes from being noticed.
The problem was that the newly added git ref file does not trigger an add event. The kqueue code saw a generic change event for the refs directory, but since the old file was being deleted and replaced by the new file, the kqueue code, which already had the old file in its cache, did not notice the file had been replaced.
I fixed that by making the kqueue code also track the inode of each file. Currently that adds the overhead of a stat of each file, which could be avoided if haskell exposed the inode returned by
readdir. Room to optimise this later...Also noticed that the kqueue code was not separating out file deletions from directory deletions. IIRC Jimmy had once mentioned a problem with file deletions not being noticed by the assistant, and this could be responsible for that, although the directory deletion code seems to handle them ok normally. It was making the transfer watching thread not notice when any transfers finished, for sure. I fixed this oversight, looking in the cache to see if there used to be a file or a directory, and running the appropriate hook.
Even with these fixes, the assistant does not yet reliably transfer file contents on OSX. I think the problem is that with kqueue we're not guaranteed to get an add event, and a deletion event for a transfer info file -- if it's created and quickly deleted, the code that synthensizes those events doesn't run in time to know it existed. Since the transfer code relies on deletion events to tell when transfers are complete, it stops sending files after the first transfer, if the transfer ran so quickly it doesn't get the expected events.
So, will need to work on OSX support some more...
Managed to find a minimal, 20 line test case for at least one of the ways git-annex was hanging with GHC's threaded runtime. Sent it off to haskell-cafe for analysis. thread
Further managed to narrow the bug down to MissingH's use of logging code, that git-annex doesn't use. bug report. So, I can at least get around this problem with a modified version of MissingH. Hopefully that was the only thing causing the hangs I was seeing!
I didn't plan to work on git-annex much while at DebConf, because the conference always prevents the kind of concentration I need. But I unexpectedly also had to deal with three dead drives and illness this week.
That said, I have been trying to debug a problem with git-annex and Haskell's threaded runtime all week. It just hangs, randomly. No luck so far isolating why, although I now have a branch that hangs fairly reliably, and in which I am trying to whittle the entire git-annex code base (all 18 thousand lines!) into a nice test case.
This threaded runtime problem doesn't affect the assistant yet, but if I want to use Yesod in developing the webapp, I'll need the threaded runtime, and using the threaded runtime in the assistant generally would make it more responsive and less hacky.
Since this is a task I can work on without much concentration, I'll probably keep beating on it until I return home. Then I need to spend some quality thinking time on where to go next in the assistant.
Spent most of the day making file content transfers robust. There were lots of bugs, hopefully I've fixed most of them. It seems to work well now, even when I throw a lot of files at it.
One of the changes also sped up transfers; it no longer roundtrips to the
remote to verify it has a file. The idea here is that when the assistant is
running, repos should typically be fairly tightly synced to their remotes
by it, so some of the extra checks that the move command does are
unnecessary.
Also spent some time trying to use ghc's threaded runtime, but continue to be baffled by the random hangs when using it. This needs fixing eventually; all the assistant's threads can potentially be blocked when it's waiting on an external command it has run.
Also changed how transfer info files are locked. The lock file is now separate from the info file, which allows the TransferWatcher thread to notice when an info file is created, and thus actually track transfers initiated by remotes.
I'm fairly close now to merging the assistant branch into master.
The data syncing code is very brute-force, but it will work well enough
for a first cut.
Next I can either add some repository network mapping, and use graph analysis to reduce the number of data transfers, or I can move on to the webapp. Not sure yet which I'll do. It's likely that since DebConf begins tomorrow I'll put off either of those big things until after the conference.
My laptop's SSD died this morning. I had some work from yesterday committed to the git repo on it, but not pushed as it didn't build. Luckily I was able to get that off the SSD, which is now a read-only drive -- even mounting it fails with fsck write errors.
Wish I'd realized the SSD was dying before the day before my trip to Nicaragua.. Getting back to a useful laptop used most of my time and energy today.
I did manage to fix transfers to not block the rest of the assistant's threads. Problem was that, without Haskell's threaded runtime, waiting on something like a rsync command blocks all threads. To fix this, transfers now are run in separate processes.
Also added code to allow multiple transfers to run at once. Each transfer
takes up a slot, with the number of free slots tracked by a QSemN.
This allows the transfer starting thread to block until a slot frees up,
and then run the transfer.
This needs to be extended to be aware of transfers initiated by remotes.
The transfer watcher thread should detect those starting and stopping
and update the QSemN accordingly. It would also be nice if transfers
initiated by remotes would be delayed when there are no free slots for them
... but I have not thought of a good way to do that.
There's a bug somewhere in the new transfer code, when two transfers are queued close together, the second one is lost and doesn't happen. Would debug this, but I'm spent for the day.
So as not to bury the lead, I've been hard at work on my first day in Nicaragua, and the git-annex assistant fully syncs files (including their contents) between remotes now !!
Details follow..
Made the committer thread queue Upload Transfers when new files are added to the annex. Currently it tries to transfer the new content to every remote; this inefficiency needs to be addressed later.
Made the watcher thread queue Download Transfers when new symlinks appear that point to content we don't have. Typically, that will happen after an automatic merge from a remote. This needs to be improved as it currently adds Transfers from every remote, not just those that have the content.
This was the second place that needed an ordered list of remotes to talk to. So I cached such a list in the DaemonStatus state info. This will also be handy later on, when the webapp is used to add new remotes, so the assistant can know about them immediately.
Added YAT (Yet Another Thread), number 15 or so, the transferrer thread that waits for transfers to be queued and runs them. Currently a naive implementation, it runs one transfer at a time, and does not do anything to recover when a transfer fails.
Actually transferring content requires YAT, so that the transfer action can run in a copy of the Annex monad, without blocking all the assistant's other threads from entering that monad while a transfer is running. This is also necessary to allow multiple concurrent transfers to run in the future.
This is a very tricky piece of code, because that thread will modify the git-annex branch, and its parent thread has to invalidate its cache in order to see any changes the child thread made. Hopefully that's the extent of the complication of doing this. The only reason this was possible at all is that git-annex already support multiple concurrent processes running and all making independent changes to the git-annex branch, etc.
After all my groundwork this week, file content transferring is now fully working!
In a series of airport layovers all day. Since I woke up at 3:45 am, didn't feel up to doing serious new work, so instead I worked through some OSX support backlog.
git-annex will now use Haskell's SHA library if the sha256sum
command is not available. That library is slow, but it's guaranteed to be
available; git-annex already depended on it to calculate HMACs.
Then I decided to see if it makes sense to use the SHA library
when adding smaller files. At some point, its slower implementation should
win over needing to fork and parse the output of sha256sum. This was
the first time I tried out Haskell's
Criterion benchmarker,
and I built this simple benchmark in short order.
import Data.Digest.Pure.SHA
import Data.ByteString.Lazy as L
import Criterion.Main
import Common
testfile :: FilePath
testfile = "/tmp/bar" -- on ram disk
main = defaultMain
[ bgroup "sha256"
[ bench "internal" $ whnfIO internal
, bench "external" $ whnfIO external
]
]
internal :: IO String
internal = showDigest . sha256 <$> L.readFile testfile
external :: IO String
external = pOpen ReadFromPipe "sha256sum" [testfile] $ \h ->
fst . separate (== ' ') <$> hGetLine h
The nice thing about benchmarking in Airports is when you're running a benchmark locally, you don't want to do anything else with the computer, so can alternate people watching, spacing out, and analizing results.
100 kb file:
benchmarking sha256/internal
mean: 15.64729 ms, lb 15.29590 ms, ub 16.10119 ms, ci 0.950
std dev: 2.032476 ms, lb 1.638016 ms, ub 2.527089 ms, ci 0.950
benchmarking sha256/external
mean: 8.217700 ms, lb 7.931324 ms, ub 8.568805 ms, ci 0.950
std dev: 1.614786 ms, lb 1.357791 ms, ub 2.009682 ms, ci 0.950
75 kb file:
benchmarking sha256/internal
mean: 12.16099 ms, lb 11.89566 ms, ub 12.50317 ms, ci 0.950
std dev: 1.531108 ms, lb 1.232353 ms, ub 1.929141 ms, ci 0.950
benchmarking sha256/external
mean: 8.818731 ms, lb 8.425744 ms, ub 9.269550 ms, ci 0.950
std dev: 2.158530 ms, lb 1.916067 ms, ub 2.487242 ms, ci 0.950
50 kb file:
benchmarking sha256/internal
mean: 7.699274 ms, lb 7.560254 ms, ub 7.876605 ms, ci 0.950
std dev: 801.5292 us, lb 655.3344 us, ub 990.4117 us, ci 0.950
benchmarking sha256/external
mean: 8.715779 ms, lb 8.330540 ms, ub 9.102232 ms, ci 0.950
std dev: 1.988089 ms, lb 1.821582 ms, ub 2.181676 ms, ci 0.950
10 kb file:
benchmarking sha256/internal
mean: 1.586105 ms, lb 1.574512 ms, ub 1.604922 ms, ci 0.950
std dev: 74.07235 us, lb 51.71688 us, ub 108.1348 us, ci 0.950
benchmarking sha256/external
mean: 6.873742 ms, lb 6.582765 ms, ub 7.252911 ms, ci 0.950
std dev: 1.689662 ms, lb 1.346310 ms, ub 2.640399 ms, ci 0.950
It's possible to get nice graphical reports out of Criterion, but this is clear enough, so I stopped here. 50 kb seems a reasonable cutoff point.
I also used this to benchmark the SHA256 in Haskell's Crypto package. Surprisingly, it's a lot slower than even the Pure.SHA code. On a 50 kb file:
benchmarking sha256/Crypto
collecting 100 samples, 1 iterations each, in estimated 6.073809 s
mean: 69.89037 ms, lb 69.15831 ms, ub 70.71845 ms, ci 0.950
std dev: 3.995397 ms, lb 3.435775 ms, ub 4.721952 ms, ci 0.950
There's another Haskell library, SHA2, which I should try some time.
Starting to travel, so limited time today.
Yet Another Thread added to the assistant, all it does is watch for changes to transfer information files, and update the assistant's map of transfers currently in progress. Now the assistant will know if some other repository has connected to the local repo and is sending or receiving a file's content.
This seemed really simple to write, it's just 78 lines of code. It worked
100% correctly the first time. But it's only so easy because I've got
this shiny new inotify hammer that I keep finding places to use in the
assistant.
Also, the new thread does some things that caused a similar thread (the merger thread) to go into a MVar deadlock. Luckily, I spent much of day 19 investigating and fixing that deadlock, even though it was not a problem at the time.
So, good.. I'm doing things right and getting to a place where rather nontrivial features can be added easily.
--
Next up: Enough nonsense with tracking transfers... Time to start actually transferring content around!
Well, sometimes you just have to go for the hack. Trying to find a way
to add additional options to git-annex-shell without breaking backwards
compatibility, I noticed that it ignores all options after --, because
those tend to be random rsync options due to the way rsync runs it.
So, I've added a new class of options, that come in between, like
-- opt=val opt=val ... --
The parser for these will not choke on unknown options, unlike normal getopt. So this let me add the additional info I needed to pass to git-annex-shell to make it record transfer information. And if I need to pass more info in the future, that's covered too.
It's ugly, but since only git-annex runs git-annex-shell, this is an ugliness only I (and now you, dear reader) have to put up with.
Note to self: Command-line programs are sometimes an API, particularly if designed to be called remotely, and so it makes sense consider whether they are, and design expandability into them from day 1.
Anyway, we now have full transfer tracking in git-annex! Both sides of a transfer know what's being transferred, and from where, and have the info necessary to interrupt the transfer.
Also did some basic groundwork, adding a queue of transfers to perform, and adding to the daemon's status information a map of currently running transfers.
Next up: The daemon will use inotify to notice new and deleted transfer info files, and update its status info.
Worked today on two action items from my last blog post:
- on-disk transfers in progress information files (read/write/enumerate)
- locking for the files, so redundant transfer races can be detected, and failed transfers noticed
That's all done, and used by the get, copy, and move subcommands.
Also, I made git-annex status use that information to display any
file transfers that are currently in progress:
joey@gnu:~/lib/sound/misc>git annex status
[...]
transfers in progress:
downloading Vic-303.mp3 from leech
(Webapp, here we come!)
However... Files being sent or received by git-annex-shell don't yet
have this transfer info recorded. The problem is that to do so,
git-annex-shell will need to be run with a --remote= parameter. But
old versions will of course fail when run with such an unknown parameter.
This is a problem I last faced in December 2011 when adding the --uuid=
parameter. That time I punted and required the remote git-annex-shell be
updated to a new enough version to accept it. But as git-annex gets more widely
used and packaged, that's becoming less an option. I need to find a real
solution to this problem.
Today is a planning day. I have only a few days left before I'm off to
Nicaragua for DebConf, where I'll only
have smaller chunks of time without interruptions. So it's important to get
some well-defined smallish chunks designed that I can work on later. See
bulleted action items below (now moved to syncing. Each
should be around 1-2 hours unless it turns out to be 8 hours...
First, worked on writing down a design, and some data types, for data transfer tracking (see syncing page). Found that writing down these simple data types before I started slinging code has clarified things a lot for me.
Most importantly, I realized that I will need to modify git-annex-shell
to record on disk what transfers it's doing, so the assistant can get that
information and use it to both avoid redundant transfers (potentially a big
problem!), and later to allow the user to control them using the web app.
While eventually the user will be able to use the web app to prioritize transfers, stop and start, throttle, etc, it's important to get the default behavior right. So I'm thinking about things like how to prioritize uploads vs downloads, when it's appropriate to have multiple downloads running at once, etc.
Random improvements day..
Got the merge conflict resolution code working in git annex assistant.
Did some more fixes to the pushing and pulling code, covering some cases I missed earlier.
Git syncing seems to work well for me now; I've seen it recover from a variety of error conditions, including merge conflicts and repos that were temporarily unavailable.
There is definitely a MVar deadlock if the merger thread's inotify event handler tries to run code in the Annex monad. Luckily, it doesn't currently seem to need to do that, so I have put off debugging what's going on there.
Reworked how the inotify thread runs, to avoid the two inotify threads in the assistant now from both needing to wait for program termination, in a possibly conflicting manner.
Hmm, that seems to have fixed the MVar deadlock problem.
Been thinking about how to fix ?watcher commits unlocked files. Posted some thoughts there.
It's about time to move on to data syncing. While eventually that will need to build a map of the repo network to efficiently sync data over the fastest paths, I'm thinking that I'll first write a dumb version. So, two more threads:
Uploads new data to every configured remote. Triggered by the watcher thread when it adds content. Easy; just use a
TSetof Keys to send.Downloads new data from the cheapest remote that has it. Could be triggered by the merger thread, after it merges in a git sync. Rather hard; how does it work out what new keys are in the tree without scanning it all? Scan through the git history to find newly created files? Maybe the watcher triggers this thread instead, when it sees a new symlink, without data, appear.
Both threads will need to be able to be stopped, and restarted, as needed to control the data transfer. And a lot of other control smarts will eventually be needed, but my first pass will be to do a straightforward implementation. Once it's done, the git annex assistant will be basically usable.
Worked on automatic merge conflict resolution today. I had expected to be able to use git's merge driver interface for this, but that interface is not sufficient. There are two problems with it:
- The merge program is run when git is in the middle of an operation that locks the index. So it cannot delete or stage files. I need to do both as part of my conflict resolution strategy.
- The merge program is not run at all when the merge conflict is caused by one side deleting a file, and the other side modifying it. This is an important case to handle.
So, instead, git-annex will use a regular git merge, and if it fails, it
will fix up the conflicts.
That presented its own difficulty, of finding which files in the tree
conflict. git ls-files --unmerged is the way to do that, but its output
is a quite raw form:
120000 3594e94c04db171e2767224db355f514b13715c5 1 foo
120000 35ec3b9d7586b46c0fd3450ba21e30ef666cfcd6 3 foo
100644 1eabec834c255a127e2e835dadc2d7733742ed9a 2 bar
100644 36902d4d842a114e8b8912c02d239b2d7059c02b 3 bar
I had to stare at the rather impenetrable documentation for hours and write a lot of parsing and processing code to get from that to these mostly self explanatory data types:
data Conflicting v = Conflicting
{ valUs :: Maybe v
, valThem :: Maybe v
} deriving (Show)
data Unmerged = Unmerged
{ unmergedFile :: FilePath
, unmergedBlobType :: Conflicting BlobType
, unmergedSha :: Conflicting Sha
} deriving (Show)
Not the first time I've whined here about time spent parsing unix command
output, is it?
From there, it was relatively easy to write the actual conflict cleanup
code, and make git annex sync use it. Here's how it looks:
$ ls -1
foo.png
bar.png
$ git annex sync
commit
# On branch master
nothing to commit (working directory clean)
ok
merge synced/master
CONFLICT (modify/delete): bar.png deleted in refs/heads/synced/master and modified in HEAD. Version HEAD of bar.png left in tree.
Automatic merge failed; fix conflicts and then commit the result.
bar.png: needs merge
(Recording state in git...)
[master 0354a67] git-annex automatic merge conflict fix
ok
$ ls -1
foo.png
bar.variant-a1fe.png
bar.variant-93a1.png
There are very few options for ways for the conflict resolution code to name conflicting variants of files. The conflict resolver can only use data present in git to generate the names, because the same conflict needs to be resolved the same everywhere.
So I had to choose between using the full key name in the filenames produced when resolving a merge, and using a shorter checksum of the key, that would be more user-friendly, but could theoretically collide with another key. I chose the checksum, and weakened it horribly by only using 32 bits of it!
Surprisingly, I think this is a safe choice. The worst that can happens if such a collision happens is another conflict, and the conflict resolution code will work on conflicts produced by the conflict resolution code! In such a case, it does fall back to putting the whole key in the filename: "bar.variant-SHA256-s2550--2c09deac21fa93607be0844fefa870b2878a304a7714684c4cc8f800fda5e16b.png"
Still need to hook this code into git annex assistant.
Not much available time today, only a few hours.
Main thing I did was fixed up the failed push tracking to use a better data
structure. No need for a queue of failed pushes, all it needs is a map of
remotes that have an outstanding failed push, and a timestamp. Now it
won't grow in memory use forever anymore.
Finding the right thread mutex type for this turned out to be a bit of a challenge. I ended up with a STM TMVar, which is left empty when there are no pushes to retry, so the thread using it blocks until there are some. And, it can be updated transactionally, without races.
I also fixed a bug outside the git-annex assistant code. It was possible to crash git-annex if a local git repository was configured as a remote, and the repository was not available on startup. git-annex now ignores such remotes. This does impact the assistant, since it is a long running process and git repositories will come and go. Now it ignores any that were not available when it started up. This will need to be dealt with when making it support removable drives.
I released a version of git-annex over the weekend that includes the git
annex watch command. There's a minor issue installing it from cabal on
OSX, which I've fixed in my tree. Nice timing: At least the watch command
should be shipped in the next Debian release, which freezes at the end of
the month.
Jimmy found out how kqueue blows up when there are too many directories to keep all open. I'm not surprised this happens, but it's nice to see exactly how. Odd that it happened to him at just 512 directories; I'd have guessed more. I have plans to fork watcher programs that each watch 512 directories (or whatever the ulimit is), to deal with this. What a pitiful interface is kqueue.. I have not thought yet about how the watcher programs would communicate back to the main program.
Back on the assistant front, I've worked today on making git syncing more robust. Now when a push fails, it tries a pull, and a merge, and repushes. That ensures that the push is, almost always, a fast-forward. Unless something else gets in a push first, anyway!
If a push still fails, there's Yet Another Thread, added today, that will wake up after 30 minutes and retry the push. It currently keeps retrying every 30 minutes until the push finally gets though. This will deal, to some degree, with those situations where a remote is only sometimes available.
I need to refine the code a bit, to avoid it keeping an ever-growing queue of failed pushes, if a remote is just dead. And to clear old failed pushes from the queue when a later push succeeds.
I also need to write a git merge driver that handles conflicts in the tree.
If two conflicting versions of a file foo are saved, this would merge
them, renaming them to foo.X and foo.Y. Probably X and Y are the
git-annex keys for the content of the files; this way all clones will
resolve the conflict in a way that leads to the same tree. It's also
possible to get a conflict by one repo deleting a file, and another
modifying it. In this case, renaming the deleted file to foo.Y may
be the right approach, I am not sure.
I glanced through some Haskell dbus bindings today. I belive there are dbus events available to detect when drives are mounted, and on Linux this would let git-annex notice and sync to usb drives, etc.
Syncing works! I have two clones, and any file I create in the first is immediately visible in the second. Delete that file from the second, and it's immediately removed from the first.
Most of my work today felt like stitching existing limbs onto a pre-existing
monster. Took the committer thread, that waits for changes and commits them,
and refashioned it into a pusher thread, that waits for commits and pushes
them. Took the watcher thread, that watches for files being made,
and refashioned it into a merger thread, that watches for git refs being
updated. Pulled in bits of the git annex sync command to reanimate this.
It may be a shambling hulk, but it works.
Actually, it's not much of a shambling hulk; I refactored my code after
copying it.
I think I'm up to 11 threads now in the new
git annex assistant command, each with its own job, and each needing
to avoid stepping on the other's toes. I did see one MVar deadlock error
today, which I have not managed to reproduce after some changes. I think
the committer thread was triggering the merger thread, which probably
then waited on the Annex state MVar the committer thread had held.
Anyway, it even pushes to remotes in parallel, and keeps track of remotes it failed to push to, although as of yet it doesn't do any attempt at periodically retrying.
One bug I need to deal with is that the push code assumes any change made to the remote has already been pushed back to it. When it hasn't, the push will fail due to not being a fast-forward. I need to make it detect this case and pull before pushing.
(I've pushed this work out in a new assistant branch.)
Pondering syncing today. I will be doing syncing of the git repository first, and working on syncing of file data later.
The former seems straightforward enough, since we just want to push all changes to everywhere. Indeed, git-annex already has a sync command that uses a smart technique to allow syncing between clones without a central bare repository. (Props to Joachim Breitner for that.)
But it's not all easy. Syncing should happen as fast as possible, so changes show up without delay. Eventually it'll need to support syncing between nodes that cannot directly contact one-another. Syncing needs to deal with nodes coming and going; one example of that is a USB drive being plugged in, which should immediately be synced, but network can also come and go, so it should periodically retry nodes it failed to sync with. To start with, I'll be focusing on fast syncing between directly connected nodes, but I have to keep this wider problem space in mind.
One problem with git annex sync is that it has to be run in both clones
in order for changes to fully propagate. This is because git doesn't allow
pushing changes into a non-bare repository; so instead it drops off a new
branch in .git/refs/remotes/$foo/synced/master. Then when it's run locally
it merges that new branch into master.
So, how to trigger a clone to run git annex sync when syncing to it?
Well, I just realized I have spent two weeks developing something that can
be repurposed to do that! Inotify can watch for changes to
.git/refs/remotes, and the instant a change is made, the local sync
process can be started. This avoids needing to make another ssh connection
to trigger the sync, so is faster and allows the data to be transferred
over another protocol than ssh, which may come in handy later.
So, in summary, here's what will happen when a new file is created:
- inotify event causes the file to be added to the annex, and immediately committed.
- new branch is pushed to remotes (probably in parallel)
- remotes notice new sync branch and merge it
- (data sync, TBD later)
- file is fully synced and available
Steps 1, 2, and 3 should all be able to be accomplished in under a second.
The speed of git push making a ssh connection will be the main limit
to making it fast. (Perhaps I should also reuse git-annex's existing ssh
connection caching code?)
... I'm getting tired of kqueue.
But the end of the tunnel is in sight. Today I made git-annex handle files that are still open for write after a kqueue creation event is received. Unlike with inotify, which has a new event each time a file is closed, kqueue only gets one event when a file is first created, and so git-annex needs to retry adding files until there are no writers left.
Eventually I found an elegant way to do that. The committer thread already wakes up every second as long as there's a pending change to commit. So for adds that need to be retried, it can just push them back onto the change queue, and the committer thread will wait one second and retry the add. One second might be too frequent to check, but it will do for now.
This means that git annex watch should now be usable on OSX, FreeBSD, and
NetBSD! (It'll also work on Debian kFreeBSD once lsof is ported to it.)
I've meged kqueue support to master.
I also think I've squashed the empty commits that were sometimes made.
Incidentally, I'm 50% through my first month, and finishing inotify was the first half of my roadmap for this month. Seem to be right on schedule.. Now I need to start thinking about syncing.
Good news! My beta testers report that the new kqueue code works on OSX.
At least "works" as well as it does on Debian kFreeBSD. My crazy
development strategy of developing on Debian kFreeBSD while targeting Mac
OSX is vindicated.
So, I've been beating the kqueue code into shape for the last 12 hours, minus a few hours sleep.
First, I noticed it was seeming to starve the other threads. I'm using
Haskell's non-threaded runtime, which does cooperative multitasking between
threads, and my C code was never returning to let the other threads run.
Changed that around, so the C code runs until SIGALARMed, and then that
thread calls yield before looping back into the C code. Wow, cooperative
multitasking.. I last dealt with that when programming for Windows 3.1!
(Should try to use Haskell's -threaded runtime sometime, but git-annex
doesn't work under it, and I have not tried to figure out why not.)
Then I made a single commit, with no testing, in which I made the kqueue code maintain a cache of what it expects in the directory tree, and use that to determine what files changed how when a change is detected. Serious code. It worked on the first go. If you were wondering why I'm writing in Haskell ... yeah, that's why.
And I've continued to hammer on the kqueue code, making lots of little
fixes, and at this point it seems almost able to handle the changes I
throw at it. It does have one big remaining problem; kqueue doesn't tell me
when a writer closes a file, so it will sometimes miss adding files. To fix
this, I'm going to need to make it maintain a queue of new files, and
periodically check them, with lsof, to see when they're done being
written to, and add them to the annex. So while a file is being written
to, git annex watch will have to wake up every second or so, and run
lsof ... and it'll take it at least 1 second to notice a file's complete.
Not ideal, but the best that can be managed with kqueue.
Followed my plan from yesterday, and wrote a simple C library to interface
to kqueue, and Haskell code to use that library. By now I think I
understand kqueue fairly well -- there are some very tricky parts to the
interface.
But... it still didn't work. After building all this, my code was failing the same way that the haskell kqueue library failed yesterday. I filed a bug report with a testcase.
Then I thought to ask on #haskell. Got sorted out in quick order! The
problem turns out to be that haskell's runtime has a periodic SIGALARM,
that is interrupting my kevent call. It can be worked around with +RTS -V0,
but I put in a fix to retry to kevent when it's interrupted.
And now git-annex watch can detect changes to directories on BSD and OSX!
Note: I said "detect", not "do something useful in response to". Getting
from the limited kqueue events to actually staging changes in the git repo
is going to be another day's work. Still, brave FreeBSD or OSX users
might want to check out the watch branch from git and see if
git annex watch will at least say it sees changes you make to your
repository.
I've been investigating how to make git annex watch work on
FreeBSD, and by extension, OSX.
One option is kqueue, which works on both operating systems, and allows very basic monitoring of file changes. There's also an OSX specific hfsevents interface.
Kqueue is far from optimal for git annex watch, because it provides even
less information than inotify (which didn't really provide everything I
needed, thus the lsof hack). Kqueue doesn't have events for files being
closed, only an event when a file is created. So it will be difficult for
git annex watch to know when a file is done being written to and can be
annexed. git annex will probably need to run lsof periodically to check when
recently added files are complete. (hsevents shares this limitation)
Kqueue also doesn't provide specific events when a file or directory is
moved. Indeed, it doesn't provide specific events about what changed at
all. All you get with kqueue is a generic "oh hey, the directory you're
watching changed in some way", and it's up to you to scan it to work out
how. So git annex will probably need to run git ls-tree --others
to find changes in the directory tree. This could be expensive with large
trees. (hsevents has per-file events on current versions of OSX)
Despite these warts, I want to try kqueue first, since it's more portable than hfsevents, and will surely be easier for me to develop support for, since I don't have direct access to OSX.
So I went to a handy Debian kFreeBSD porter box, and tried some kqueue stuff to get a feel for it. I got a python program that does basic directory monitoring with kqueue to work, so I know it's usable there.
Next step was getting kqueue working from Haskell. Should be easy, there's a Haskell library already. I spent a while trying to get it to work on Debian kFreeBSD, but ran into a problem that could be caused by the Debian kFreeBSD being different, or just a bug in the Haskell library. I didn't want to spend too long shaving this yak; I might install "real" FreeBSD on a spare laptop and try to get it working there instead.
But for now, I've dropped down to C instead, and have a simple C program that can monitor a directory with kqueue. Next I'll turn it into a simple library, which can easily be linked into my Haskell code. The Haskell code will pass it a set of open directory descriptors, and it'll return the one that it gets an event on. This is necessary because kqueue doesn't recurse into subdirectories on its own.
I've generally had good luck with this approach to adding stuff in Haskell; rather than writing a bit-banging and structure packing low level interface in Haskell, write it in C, with a simpler interface between C and Haskell.
A rather frustrating and long day coding went like this:
1-3 pm
Wrote a single function, of which all any Haskell programmer needs to know is its type signature:
Lsof.queryDir :: FilePath -> IO [(FilePath, LsofOpenMode, ProcessInfo)]
When I'm spending another hour or two taking a unix utility like lsof and parsing its output, which in this case is in a rather complicated machine-parsable output format, I often wish unix streams were strongly typed, which would avoid this bother.
3-9 pm
Six hours spent making it defer annexing files until the commit thread wakes up and is about to make a commit. Why did it take so horribly long? Well, there were a number of complications, and some really bad bugs involving races that were hard to reproduce reliably enough to deal with.
In other words, I was lost in the weeds for a lot of those hours...
At one point, something glorious happened, and it was always making exactly one commit for batch mode modifications of a lot of files (like untarring them). Unfortunately, I had to lose that gloriousness due to another potential race, which, while unlikely, would have made the program deadlock if it happened.
So, it's back to making 2 or 3 commits per batch mode change. I also have a buglet that causes sometimes a second empty commit after a file is added. I know why (the inotify event for the symlink gets in late, after the commit); will try to improve commit frequency later.
9-11 pm
Put the capstone on the day's work, by calling lsof on a directory full of hardlinks to the files that are about to be annexed, to check if any are still open for write.
This works great! Starting up git annex watch when processes have files
open is no longer a problem, and even if you're evil enough to try having
multiple processes open the same file, it will complain and not annex it
until all the writers close it.
(Well, someone really evil could turn the write bit back on after git annex
clears it, and open the file again, but then really evil people can do
that to files in .git/annex/objects too, and they'll get their just
deserts when git annex fsck runs. So, that's ok..)
Anyway, will beat on it more tomorrow, and if all is well, this will finally go out to the beta testers.
git merge watch_
My cursor has been mentally poised here all day, but I've been reluctant to merge watch into master. It seems solid, but is it correct? I was able to think up a lot of races it'd be subject to, and deal with them, but did I find them all?
Perhaps I need to do some automated fuzz testing to reassure myself. I looked into using genbackupdata to that end. It's not quite what I need, but could be moved in that direction. Or I could write my own fuzz tester, but it seems better to use someone else's, because a) laziness and b) they're less likely to have the same blind spots I do.
My reluctance to merge isn't helped by the known bugs with files that are
either already open before git annex watch starts, or are opened by two
processes at once, and confuse it into annexing the still-open file when one
process closes it.
I've been thinking about just running lsof on every file as it's being
annexed to check for that, but in the end, lsof is too slow. Since its
check involves trawling through all of /proc, it takes it a good half a
second to check a file, and adding 25 seconds to the time it takes to
process 100 files is just not acceptable.
But an option that could work is to run lsof after a bunch of new files
have been annexed. It can check a lot of files nearly as fast as a single
one. In the rare case that an annexed file is indeed still open, it could
be moved back out of the annex. Then when its remaining writer finally
closes it, another inotify event would re-annex it.
Since last post, I've worked on speeding up git annex watch's startup time
in a large repository.
The problem was that its initial scan was naively staging every symlink in
the repository, even though most of them are, presumably, staged correctly
already. This was done in case the user copied or moved some symlinks
around while git annex watch was not running -- we want to notice and
commit such changes at startup.
Since I already had the stat info for the symlink, it can look at the
ctime to see if the symlink was made recently, and only stage it if so.
This sped up startup in my big repo from longer than I cared to wait (10+
minutes, or half an hour while profiling) to a minute or so. Of course,
inotify events are already serviced during startup, so making it scan
quickly is really only important so people don't think it's a resource hog.
First impressions are important.
But what does "made recently" mean exactly? Well, my answer is possibly
over engineered, but most of it is really groundwork for things I'll need
later anyway. I added a new data structure for tracking the status of the
daemon, which is periodically written to disk by another thread (thread #6!)
to .git/annex/daemon.status Currently it looks like this; I anticipate
adding lots more info as I move into the syncing stage:
lastRunning:1339610482.47928s
scanComplete:True
So, only symlinks made after the daemon was last running need to be expensively staged on startup. Although, as RichiH pointed out, this fails if the clock is changed. But I have been planning to have a cleanup thread anyway, that will handle this, and other potential problems, so I think that's ok.
Stracing its startup scan, it's fairly tight now. There are some repeated
getcwd syscalls that could be optimised out for a minor speedup.
Added the sanity check thread. Thread #7! It currently only does one sanity check per day, but the sanity check is a fairly lightweight job, so I may make it run more frequently. OTOH, it may never ever find a problem, so once per day seems a good compromise.
Currently it's only checking that all files in the tree are properly staged
in git. I might make it git annex fsck later, but fscking the whole tree
once per day is a bit much. Perhaps it should only fsck a few files per
day? TBD
Currently any problems found in the sanity check are just fixed and logged. It would be good to do something about getting problems that might indicate bugs fed back to me, in a privacy-respecting way. TBD
I also refactored the code, which was getting far too large to all be in one module.
I have been thinking about renaming git annex watch to git annex assistant,
but I think I'll leave the command name as-is. Some users might
want a simple watcher and stager, without the assistant's other features
like syncing and the webapp. So the next stage of the
roadmap will be a different command that also runs
watch.
At this point, I feel I'm done with the first phase of inotify. It has a couple known bugs, but it's ready for brave beta testers to try. I trust it enough to be running it on my live data.
Kickstarter is over. Yay!
Today I worked on the bug where git annex watch turned regular files
that were already checked into git into symlinks. So I made it check
if a file is already in git before trying to add it to the annex.
The tricky part was doing this check quickly. Unless I want to write my
own git index parser (or use one from Hackage), this check requires running
git ls-files, once per file to be added. That won't fly if a huge
tree of files is being moved or unpacked into the watched directory.
Instead, I made it only do the check during git annex watch's initial
scan of the tree. This should be OK, because once it's running, you
won't be adding new files to git anyway, since it'll automatically annex
new files. This is good enough for now, but there are at least two problems
with it:
- Someone might
git mergein a branch that has some regular files, and it would add the merged in files to the annex. - Once
git annex watchis running, if you modify a file that was checked into git as a regular file, the new version will be added to the annex.
I'll probably come back to this issue, and may well find myself directly querying git's index.
I've started work to fix the memory leak I see when running git annex
watch in a large repository (40 thousand files). As always with a Haskell
memory leak, I crack open Real World Haskell's chapter on profiling.
Eventually this yields a nice graph of the problem:
So, looks like a few minor memory leaks, and one huge leak. Stared at this for a while and trying a few things, and got a much better result:
I may come back later and try to improve this further, but it's not bad memory usage. But, it's still rather slow to start up in such a large repository, and its initial scan is still doing too much work. I need to optimize more..
Since my last blog, I've been polishing the git annex watch command.
First, I fixed the double commits problem. There's still some extra
committing going on in the git-annex branch that I don't understand. It
seems like a shutdown event is somehow being triggered whenever
a git command is run by the commit thread.
I also made git annex watch run as a proper daemon, with locking to
prevent multiple copies running, and a pid file, and everything.
I made git annex watch --stop stop it.
Then I managed to greatly increase its startup speed. At startup, it generates "add" events for every symlink in the tree. This is necessary because it doesn't really know if a symlink is already added, or was manually added before it starter, or indeed was added while it started up. Problem was that these events were causing a lot of work staging the symlinks -- most of which were already correctly staged.
You'd think it could just check if the same symlink was in the index. But it can't, because the index is in a constant state of flux. The symlinks might have just been deleted and re-added, or changed, and the index still have the old value.
Instead, I got creative. We can't trust what the index says about the
symlink, but if the index happens to contain a symlink that looks right,
we can trust that the SHA1 of its blob is the right SHA1, and reuse it
when re-staging the symlink. Wham! Massive speedup!
Then I started running git annex watch on my own real git annex repos,
and noticed some problems.. Like it turns normal files already checked into
git into symlinks. And it leaks memory scanning a big tree. Oops..
I put together a quick screencast demoing git annex watch.
While making the screencast, I noticed that git-annex watch was spinning
in strace, which is bad news for powertop and battery usage. This seems to
be a GHC bug also affecting Xmonad. I
tried switching to GHC's threaded runtime, which solves that problem, but
causes git-annex to hang under heavy load. Tried to debug that for quite a
while, but didn't get far. Will need to investigate this further..
Am seeing indications that this problem only affects ghc 7.4.1; in
particular 7.4.2 does not seem to have the problem.
After a few days otherwise engaged, back to work today.
My focus was on adding the committing thread mentioned in day 4 speed. I got rather further than expected!
First, I implemented a really dumb thread, that woke up once per second,
checked if any changes had been made, and committed them. Of course, this
rather sucked. In the middle of a large operation like untarring a tarball,
or rm -r of a large directory tree, it made lots of commits and made
things slow and ugly. This was not unexpected.
So next, I added some smarts to it. First, I wanted to stop it waking up every second when there was nothing to do, and instead blocking wait on a change occurring. Secondly, I wanted it to know when past changes happened, so it could detect batch mode scenarios, and avoid committing too frequently.
I played around with combinations of various Haskell thread communications
tools to get that information to the committer thread: MVar, Chan,
QSem, QSemN. Eventually, I realized all I needed was a simple channel
through which the timestamps of changes could be sent. However, Chan
wasn't quite suitable, and I had to add a dependency on
Software Transactional Memory,
and use a TChan. Now I'm cooking with gas!
With that data channel available to the committer thread, it quickly got some very nice smart behavior. Playing around with it, I find it commits instantly when I'm making some random change that I'd want the git-annex assistant to sync out instantly; and that its batch job detection works pretty well too.
There's surely room for improvement, and I made this part of the code be an entirely pure function, so it's really easy to change the strategy. This part of the committer thread is so nice and clean, that here's the current code, for your viewing pleasure:
{- Decide if now is a good time to make a commit.
- Note that the list of change times has an undefined order.
-
- Current strategy: If there have been 10 commits within the past second,
- a batch activity is taking place, so wait for later.
-}
shouldCommit :: UTCTime -> [UTCTime] -> Bool
shouldCommit now changetimes
| len == 0 = False
| len > 4096 = True -- avoid bloating queue too much
| length (filter thisSecond changetimes) < 10 = True
| otherwise = False -- batch activity
where
len = length changetimes
thisSecond t = now `diffUTCTime` t <= 1
Still some polishing to do to eliminate minor inefficiencies and deal with more races, but this part of the git-annex assistant is now very usable, and will be going out to my beta testers soon!
Only had a few hours to work today, but my current focus is speed, and I
have indeed sped up parts of git annex watch.
One thing folks don't realize about git is that despite a rep for being
fast, it can be rather slow in one area: Writing the index. You don't
notice it until you have a lot of files, and the index gets big. So I've
put a lot of effort into git-annex in the past to avoid writing the index
repeatedly, and queue up big index changes that can happen all at once. The
new git annex watch was not able to use that queue. Today I reworked the
queue machinery to support the types of direct index writes it needs, and
now repeated index writes are eliminated.
... Eliminated too far, it turns out, since it doesn't yet ever flush that queue until shutdown! So the next step here will be to have a worker thread that wakes up periodically, flushes the queue, and autocommits. (This will, in fact, be the start of the syncing phase of my roadmap!) There's lots of room here for smart behavior. Like, if a lot of changes are being made close together, wait for them to die down before committing. Or, if it's been idle and a single file appears, commit it immediately, since this is probably something the user wants synced out right away. I'll start with something stupid and then add the smarts.
(BTW, in all my years of programming, I have avoided threads like the nasty bug-prone plague they are. Here I already have three threads, and am going to add probably 4 or 5 more before I'm done with the git annex assistant. So far, it's working well -- I give credit to Haskell for making it easy to manage state in ways that make it possible to reason about how the threads will interact.)
What about the races I've been stressing over? Well, I have an ulterior
motive in speeding up git annex watch, and that's to also be able to
slow it down. Running in slow-mo makes it easy to try things that might
cause a race and watch how it reacts. I'll be using this technique when
I circle back around to dealing with the races.
Another tricky speed problem came up today that I also need to fix. On
startup, git annex watch scans the whole tree to find files that have
been added or moved etc while it was not running, and take care of them.
Currently, this scan involves re-staging every symlink in the tree. That's
slow! I need to find a way to avoid re-staging symlinks; I may use git
cat-file to check if the currently staged symlink is correct, or I may
come up with some better and faster solution. Sleeping on this problem.
Oh yeah, I also found one more race bug today. It only happens at startup and could only make it miss staging file deletions.
Today I worked on the race conditions, and fixed two of them. Both
were fixed by avoiding using git add, which looks at the files currently
on disk. Instead, git annex watch injects symlinks directly into git's
index, using git update-index.
There is one bad race condition remaining. If multiple processes have a file open for write, one can close it, and it will be added to the annex. But then the other can still write to it.
Getting away from race conditions for a while, I made git annex watch
not annex .gitignore and .gitattributes files.
And, I made it handle running out of inotify descriptors. By default,
/proc/sys/fs/inotify/max_user_watches is 8192, and that's how many
directories inotify can watch. Now when it needs more, it will print
a nice message showing how to increase it with sysctl.
FWIW, DropBox also uses inotify and has the same limit. It seems to not
tell the user how to fix it when it goes over. Here's what git annex
watch will say:
Too many directories to watch! (Not watching ./dir4299)
Increase the limit by running:
echo fs.inotify.max_user_watches=81920 | sudo tee -a /etc/sysctl.conf; sudo sysctl -p
Last night I got git annex watch to also handle deletion of files.
This was not as tricky as feared; the key is using git rm --ignore-unmatch,
which avoids most problematic situations (such as a just deleted file
being added back before git is run).
Also fixed some races when git annex watch is doing its startup scan of
the tree, which might be changed as it's being traversed. Now only one
thread performs actions at a time, so inotify events are queued up during
the scan, and dealt with once it completes. It's worth noting that inotify
can only buffer so many events .. Which might have been a problem except
for a very nice feature of Haskell's inotify interface: It has a thread
that drains the limited inotify buffer and does its own buffering.
Right now, git annex watch is not as fast as it could be when doing
something like adding a lot of files, or deleting a lot of files.
For each file, it currently runs a git command that updates the index.
I did some work toward coalescing these into one command (which git annex
already does normally). It's not quite ready to be turned on yet,
because of some races involving git add that become much worse
if it's delayed by event coalescing.
And races were the theme of today. Spent most of the day really
getting to grips with all the fun races that can occur between
modification happening to files, and git annex watch. The inotify
page now has a long list of known races, some benign, and several,
all involving adding files, that are quite nasty.
I fixed one of those races this evening. The rest will probably involve
moving away from using git add, which necessarily examines the file
on disk, to directly shoving the symlink into git's index.
BTW, it turns out that dvcs-autosync has grappled with some of these same
races: http://comments.gmane.org/gmane.comp.version-control.home-dir/665
I hope that git annex watch will be in a better place to deal with them,
since it's only dealing with git, and with a restricted portion of it
relevant to git-annex.
It's important that git annex watch be rock solid. It's the foundation
of the git annex assistant. Users should not need to worry about races
when using it. Most users won't know what race conditions are. If only I
could be so lucky!
First day of Kickstarter funded work!
Worked on inotify today. The watch branch in git now does a pretty
good job of following changes made to the directory, annexing files
as they're added and staging other changes into git. Here's a quick
transcript of it in action:
joey@gnu:~/tmp>mkdir demo
joey@gnu:~/tmp>cd demo
joey@gnu:~/tmp/demo>git init
Initialized empty Git repository in /home/joey/tmp/demo/.git/
joey@gnu:~/tmp/demo>git annex init demo
init demo ok
(Recording state in git...)
joey@gnu:~/tmp/demo>git annex watch &
[1] 3284
watch . (scanning...) (started)
joey@gnu:~/tmp/demo>dd if=/dev/urandom of=bigfile bs=1M count=2
add ./bigfile 2+0 records in
2+0 records out
2097152 bytes (2.1 MB) copied, 0.835976 s, 2.5 MB/s
(checksum...) ok
(Recording state in git...)
joey@gnu:~/tmp/demo>ls -la bigfile
lrwxrwxrwx 1 joey joey 188 Jun 4 15:36 bigfile -> .git/annex/objects/Wx/KQ/SHA256-s2097152--e5ced5836a3f9be782e6da14446794a1d22d9694f5c85f3ad7220b035a4b82ee/SHA256-s2097152--e5ced5836a3f9be782e6da14446794a1d22d9694f5c85f3ad7220b035a4b82ee
joey@gnu:~/tmp/demo>git status -s
A bigfile
joey@gnu:~/tmp/demo>mkdir foo
joey@gnu:~/tmp/demo>mv bigfile foo
"del ./bigfile"
joey@gnu:~/tmp/demo>git status -s
AD bigfile
A foo/bigfile
Due to Linux's inotify interface, this is surely some of the most subtle, race-heavy code that I'll need to deal with while developing the git annex assistant. But I can't start wading, need to jump off the deep end to make progress!
The hardest problem today involved the case where a directory is moved outside of the tree that's being watched. Inotify will still send events for such directories, but it doesn't make sense to continue to handle them.
Ideally I'd stop inotify watching such directories, but a lot of state would need to be maintained to know which inotify handle to stop watching. (Seems like Haskell's inotify API makes this harder than it needs to be...)
Instead, I put in a hack that will make it detect inotify events from directories moved away, and ignore them. This is probably acceptable, since this is an unusual edge case.
The notable omission in the inotify code, which I'll work on next, is staging deleting of files. This is tricky because adding a file to the annex happens to cause a deletion event. I need to make sure there are no races where that deletion event causes data loss.